Model-Agnostic Zeroth-Order Policy Optimization for Meta-Learning of Ergodic Linear Quadratic Regulators
2405.17370
0
0

Abstract
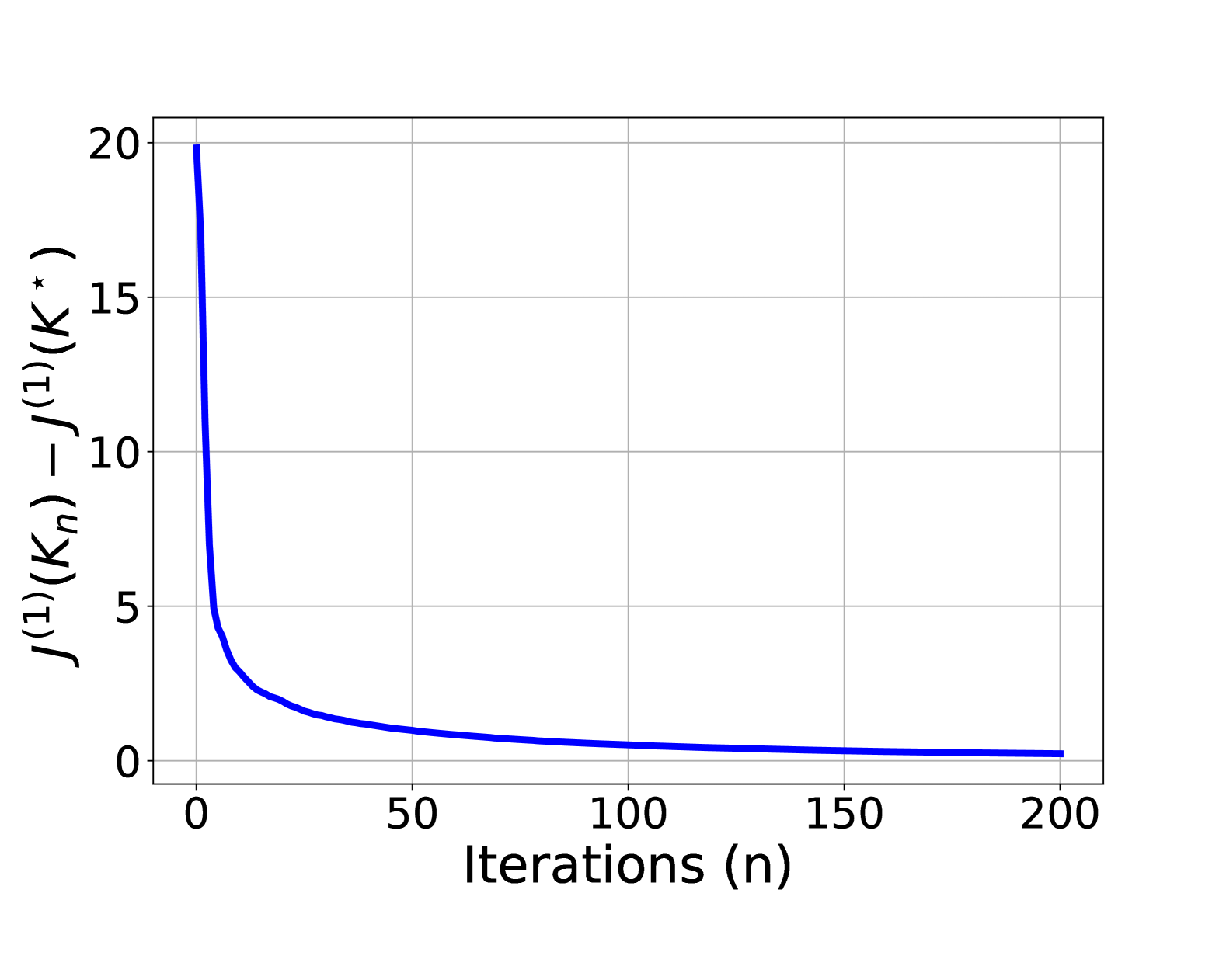
Meta-learning has been proposed as a promising machine learning topic in recent years, with important applications to image classification, robotics, computer games, and control systems. In this paper, we study the problem of using meta-learning to deal with uncertainty and heterogeneity in ergodic linear quadratic regulators. We integrate the zeroth-order optimization technique with a typical meta-learning method, proposing an algorithm that omits the estimation of policy Hessian, which applies to tasks of learning a set of heterogeneous but similar linear dynamic systems. The induced meta-objective function inherits important properties of the original cost function when the set of linear dynamic systems are meta-learnable, allowing the algorithm to optimize over a learnable landscape without projection onto the feasible set. We provide a convergence result for the exact gradient descent process by analyzing the boundedness and smoothness of the gradient for the meta-objective, which justify the proposed algorithm with gradient estimation error being small. We also provide a numerical example to corroborate this perspective.
Create account to get full access
Overview
- This paper presents a model-agnostic zeroth-order policy optimization approach for meta-learning of ergodic linear quadratic regulators (LQRs).
- The key idea is to use a gradient-free optimization method to learn a policy that can quickly adapt to different LQR problems, without requiring access to the system dynamics.
- The proposed approach is shown to outperform existing meta-learning and zeroth-order optimization methods on a range of LQR control tasks.
Plain English Explanation
The paper focuses on a type of control problem called the linear quadratic regulator (LQR), which is commonly used in robotics and other control systems. The goal is to learn a control policy that can quickly adapt to different LQR problems, without needing to know the details of the system being controlled.
The researchers use a zeroth-order optimization approach, which means they don't need to know the gradients of the system. Instead, they use a gradient-free method to learn the control policy. This makes the approach more "model-agnostic," meaning it can be applied to a wide range of LQR problems without needing to know the specific details of each one.
The key idea is to use a meta-learning approach, where the algorithm learns a general control policy that can quickly adapt to new LQR problems. This is similar to how humans can quickly learn to control new systems by drawing on their past experiences.
The researchers show that their approach outperforms existing meta-learning and zeroth-order optimization methods on a variety of LQR control tasks, demonstrating the effectiveness of this model-agnostic approach.
Technical Explanation
The paper proposes a model-agnostic zeroth-order policy optimization approach for meta-learning of ergodic linear quadratic regulators (LQRs). The key idea is to use a gradient-free optimization method to learn a policy that can quickly adapt to different LQR problems, without requiring access to the system dynamics.
The authors formulate the meta-learning problem as an optimization over a distribution of LQR tasks, where the goal is to find a policy that minimizes the expected cost across the task distribution. They use a zeroth-order optimization algorithm, which only requires access to function evaluations (i.e., the costs of different policies) rather than gradients.
The proposed algorithm, called Model-Agnostic Zeroth-Order Policy Optimization (MAZOPO), iteratively updates the policy parameters by sampling perturbations and estimating the gradient direction using finite differences. The algorithm also incorporates an MAML-style meta-learning objective to enable fast adaptation to new tasks.
The authors evaluate their approach on a range of LQR control tasks, including both linear and nonlinear systems, and show that MAZOPO outperforms existing meta-learning and zeroth-order optimization methods. The results demonstrate the effectiveness of the proposed model-agnostic zeroth-order policy optimization approach for rapidly adapting control policies to new LQR problems.
Critical Analysis
The paper presents a novel and promising approach for meta-learning of LQR control policies, but there are a few potential limitations and areas for further research:
-
The paper focuses on LQR problems, which have a specific structure and assumptions. It would be interesting to see how the approach generalizes to more complex control problems beyond the LQR framework.
-
The zeroth-order optimization method used in MAZOPO may not scale well to high-dimensional control problems, as the number of function evaluations required can grow exponentially with the number of parameters. Exploring more efficient zeroth-order optimization techniques could be a valuable direction for future work.
-
The paper does not provide a detailed theoretical analysis of the convergence and performance guarantees of the proposed algorithm. A more rigorous theoretical understanding of the method's properties could help build confidence in its reliability and robustness.
-
The evaluation is limited to simulated LQR tasks, and it would be important to validate the approach on real-world control problems, such as those found in robotics or other physical systems, to assess its practical applicability.
Overall, the paper presents an interesting and promising approach for meta-learning of LQR control policies, and the results demonstrate the potential of model-agnostic zeroth-order optimization for rapid adaptation to new control tasks. Addressing the limitations mentioned above could lead to further advancements in this area.
Conclusion
This paper introduces a model-agnostic zeroth-order policy optimization approach for meta-learning of ergodic linear quadratic regulators (LQRs). The key idea is to use a gradient-free optimization method to learn a control policy that can quickly adapt to different LQR problems, without requiring access to the system dynamics.
The proposed MAZOPO algorithm outperforms existing meta-learning and zeroth-order optimization methods on a range of LQR control tasks, demonstrating the effectiveness of this model-agnostic approach. The paper's contribution lies in the development of a versatile and efficient meta-learning framework for LQR control, which could have significant implications for robotics, cyber-physical systems, and other control-focused applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for Model-free LQR
Leonardo F. Toso, Donglin Zhan, James Anderson, Han Wang
0
0
We investigate the problem of learning linear quadratic regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a policy gradient-based (PG) model-agnostic meta-learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that our MAML-LQR algorithm produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias in both model-based and model-free learning scenarios. Moreover, in the model-based setting, we show that such a controller is achieved with a linear convergence rate, which improves upon sub-linear rates from existing work. Our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
6/4/2024

MALIBO: Meta-learning for Likelihood-free Bayesian Optimization
Jiarong Pan, Stefan Falkner, Felix Berkenkamp, Joaquin Vanschoren
0
0
Bayesian optimization (BO) is a popular method to optimize costly black-box functions. While traditional BO optimizes each new target task from scratch, meta-learning has emerged as a way to leverage knowledge from related tasks to optimize new tasks faster. However, existing meta-learning BO methods rely on surrogate models that suffer from scalability issues and are sensitive to observations with different scales and noise types across tasks. Moreover, they often overlook the uncertainty associated with task similarity. This leads to unreliable task adaptation when only limited observations are obtained or when the new tasks differ significantly from the related tasks. To address these limitations, we propose a novel meta-learning BO approach that bypasses the surrogate model and directly learns the utility of queries across tasks. Our method explicitly models task uncertainty and includes an auxiliary model to enable robust adaptation to new tasks. Extensive experiments show that our method demonstrates strong anytime performance and outperforms state-of-the-art meta-learning BO methods in various benchmarks.
7/1/2024

New!Meta-Gradient Search Control: A Method for Improving the Efficiency of Dyna-style Planning
Bradley Burega, John D. Martin, Luke Kapeluck, Michael Bowling
0
0
We study how a Reinforcement Learning (RL) system can remain sample-efficient when learning from an imperfect model of the environment. This is particularly challenging when the learning system is resource-constrained and in continual settings, where the environment dynamics change. To address these challenges, our paper introduces an online, meta-gradient algorithm that tunes a probability with which states are queried during Dyna-style planning. Our study compares the aggregate, empirical performance of this meta-gradient method to baselines that employ conventional sampling strategies. Results indicate that our method improves efficiency of the planning process, which, as a consequence, improves the sample-efficiency of the overall learning process. On the whole, we observe that our meta-learned solutions avoid several pathologies of conventional planning approaches, such as sampling inaccurate transitions and those that stall credit assignment. We believe these findings could prove useful, in future work, for designing model-based RL systems at scale.
7/1/2024

Learning to optimize with convergence guarantees using nonlinear system theory
Andrea Martin, Luca Furieri
0
0
The increasing reliance on numerical methods for controlling dynamical systems and training machine learning models underscores the need to devise algorithms that dependably and efficiently navigate complex optimization landscapes. Classical gradient descent methods offer strong theoretical guarantees for convex problems; however, they demand meticulous hyperparameter tuning for non-convex ones. The emerging paradigm of learning to optimize (L2O) automates the discovery of algorithms with optimized performance leveraging learning models and data - yet, it lacks a theoretical framework to analyze convergence of the learned algorithms. In this paper, we fill this gap by harnessing nonlinear system theory. Specifically, we propose an unconstrained parametrization of all convergent algorithms for smooth non-convex objective functions. Notably, our framework is directly compatible with automatic differentiation tools, ensuring convergence by design while learning to optimize.
6/4/2024