Zeroth-Order Optimization Meets Human Feedback: Provable Learning via Ranking Oracles
2303.03751
0
0
🛠️
Abstract
In this study, we delve into an emerging optimization challenge involving a black-box objective function that can only be gauged via a ranking oracle-a situation frequently encountered in real-world scenarios, especially when the function is evaluated by human judges. Such challenge is inspired from Reinforcement Learning with Human Feedback (RLHF), an approach recently employed to enhance the performance of Large Language Models (LLMs) using human guidance. We introduce ZO-RankSGD, an innovative zeroth-order optimization algorithm designed to tackle this optimization problem, accompanied by theoretical assurances. Our algorithm utilizes a novel rank-based random estimator to determine the descent direction and guarantees convergence to a stationary point. Moreover, ZO-RankSGD is readily applicable to policy optimization problems in Reinforcement Learning (RL), particularly when only ranking oracles for the episode reward are available. Last but not least, we demonstrate the effectiveness of ZO-RankSGD in a novel application: improving the quality of images generated by a diffusion generative model with human ranking feedback. Throughout experiments, we found that ZO-RankSGD can significantly enhance the detail of generated images with only a few rounds of human feedback. Overall, our work advances the field of zeroth-order optimization by addressing the problem of optimizing functions with only ranking feedback, and offers a new and effective approach for aligning Artificial Intelligence (AI) with human intentions.
Create account to get full access
Overview
- This study focuses on an optimization challenge involving a black-box objective function that can only be evaluated through a ranking oracle, a common scenario in real-world situations where the function is assessed by human judges.
- The challenge is inspired by Reinforcement Learning with Human Feedback (RLHF), an approach used to enhance the performance of Large Language Models (LLMs) using human guidance.
- The researchers introduce ZO-RankSGD, a novel zeroth-order optimization algorithm designed to tackle this optimization problem, with theoretical guarantees.
- ZO-RankSGD utilizes a novel rank-based random estimator to determine the descent direction, ensuring convergence to a stationary point.
- The algorithm is applicable to policy optimization problems in Reinforcement Learning (RL) when only ranking oracles for the episode reward are available.
- The researchers demonstrate the effectiveness of ZO-RankSGD in improving the quality of images generated by a diffusion generative model with human ranking feedback.
Plain English Explanation
In this study, the researchers are exploring a problem where they have a black-box function, meaning they can't see inside it or how it works. The only way they can evaluate this function is by getting a ranking or score from human judges. This is a common situation in the real world, especially when the function is something that humans are assessing, like the quality of a piece of content or the performance of a model.
The researchers were inspired by a technique called Reinforcement Learning with Human Feedback (RLHF), which is used to improve the performance of large language models by getting feedback from humans. In this study, the researchers developed a new algorithm called ZO-RankSGD that can optimize these black-box functions using only the rankings provided by the human judges.
ZO-RankSGD works by using a novel way to estimate the best direction to move in to improve the function. It has some mathematical guarantees that ensure it will converge to a stable point. The researchers also show that this algorithm can be used to improve the quality of images generated by a diffusion model, where the only feedback the model gets is from human rankings of the images.
Overall, this research presents a new way to optimize functions that can only be evaluated through human feedback, which is an important problem in many real-world applications of artificial intelligence.
Technical Explanation
The researchers introduce an optimization challenge involving a black-box objective function that can only be evaluated through a ranking oracle, a common scenario in real-world settings where the function is assessed by human judges. This challenge is inspired by Reinforcement Learning with Human Feedback (RLHF), an approach used to enhance the performance of Large Language Models (LLMs) using human guidance.
To address this challenge, the researchers propose ZO-RankSGD, a novel zeroth-order optimization algorithm. ZO-RankSGD utilizes a novel rank-based random estimator to determine the descent direction, ensuring convergence to a stationary point. The algorithm is readily applicable to policy optimization problems in Reinforcement Learning (RL), particularly when only ranking oracles for the episode reward are available.
The researchers demonstrate the effectiveness of ZO-RankSGD in a novel application: improving the quality of images generated by a diffusion generative model with human ranking feedback. The experiments show that ZO-RankSGD can significantly enhance the detail of generated images with only a few rounds of human feedback.
Critical Analysis
The researchers acknowledge that their proposed algorithm, ZO-RankSGD, relies on a strong assumption that the objective function is smooth and satisfies certain regularity conditions. In real-world scenarios, these assumptions may not always hold, and the performance of the algorithm could be affected. The paper does not provide a detailed analysis of the sensitivity of ZO-RankSGD to violations of these assumptions.
Additionally, the researchers focus on the theoretical guarantees of ZO-RankSGD, but the practical implications of these guarantees are not fully explored. It would be valuable to have a more in-depth discussion on the tradeoffs between the algorithm's convergence properties and its practical performance in different real-world settings.
Furthermore, the researchers demonstrate the effectiveness of ZO-RankSGD in improving the quality of generated images, but the method's applicability to other types of black-box optimization problems, such as optimizing human-centric objectives in AI-assisted systems, is not thoroughly investigated. Exploring the versatility of ZO-RankSGD across a broader range of applications would strengthen the impact of this research.
Conclusion
This study presents an innovative zeroth-order optimization algorithm, ZO-RankSGD, designed to tackle the challenge of optimizing black-box objective functions that can only be evaluated through ranking oracles. The algorithm's theoretical guarantees and its demonstrated success in improving the quality of generated images with human feedback suggest its potential to advance the field of zeroth-order optimization and align artificial intelligence systems with human intentions. However, the researchers acknowledge the need to address the algorithm's sensitivity to assumptions and explore its broader applicability to further strengthen the impact of this research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Revisiting Zeroth-Order Optimization for Memory-Efficient LLM Fine-Tuning: A Benchmark
Yihua Zhang, Pingzhi Li, Junyuan Hong, Jiaxiang Li, Yimeng Zhang, Wenqing Zheng, Pin-Yu Chen, Jason D. Lee, Wotao Yin, Mingyi Hong, Zhangyang Wang, Sijia Liu, Tianlong Chen
0
0
In the evolving landscape of natural language processing (NLP), fine-tuning pre-trained Large Language Models (LLMs) with first-order (FO) optimizers like SGD and Adam has become standard. Yet, as LLMs grow {in size}, the substantial memory overhead from back-propagation (BP) for FO gradient computation presents a significant challenge. Addressing this issue is crucial, especially for applications like on-device training where memory efficiency is paramount. This paper proposes a shift towards BP-free, zeroth-order (ZO) optimization as a solution for reducing memory costs during LLM fine-tuning, building on the initial concept introduced by MeZO. Unlike traditional ZO-SGD methods, our work expands the exploration to a wider array of ZO optimization techniques, through a comprehensive, first-of-its-kind benchmarking study across five LLM families (Roberta, OPT, LLaMA, Vicuna, Mistral), three task complexities, and five fine-tuning schemes. Our study unveils previously overlooked optimization principles, highlighting the importance of task alignment, the role of the forward gradient method, and the balance between algorithm complexity and fine-tuning performance. We further introduce novel enhancements to ZO optimization, including block-wise descent, hybrid training, and gradient sparsity. Our study offers a promising direction for achieving further memory-efficient LLM fine-tuning. Codes to reproduce all our experiments are at https://github.com/ZO-Bench/ZO-LLM .
5/29/2024
A Zeroth-Order Proximal Algorithm for Consensus Optimization
Chengan Wang, Zichong Ou, Jie Lu
0
0
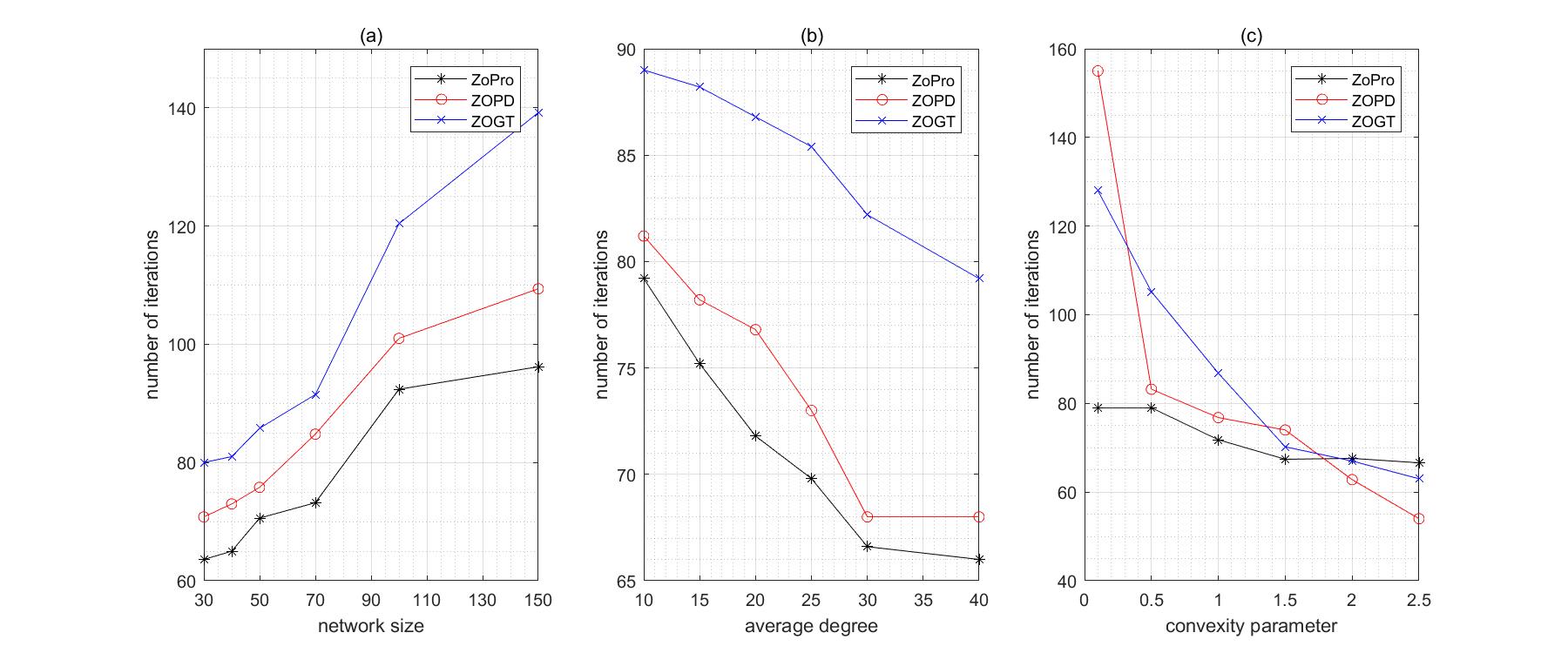
This paper considers a consensus optimization problem, where all the nodes in a network, with access to the zeroth-order information of its local objective function only, attempt to cooperatively achieve a common minimizer of the sum of their local objectives. To address this problem, we develop ZoPro, a zeroth-order proximal algorithm, which incorporates a zeroth-order oracle for approximating Hessian and gradient into a recently proposed, high-performance distributed second-order proximal algorithm. We show that the proposed ZoPro algorithm, equipped with a dynamic stepsize, converges linearly to a neighborhood of the optimum in expectation, provided that each local objective function is strongly convex and smooth. Extensive simulations demonstrate that ZoPro converges faster than several state-of-the-art distributed zeroth-order algorithms and outperforms a few distributed second-order algorithms in terms of running time for reaching given accuracy.
6/17/2024
Variance-reduced Zeroth-Order Methods for Fine-Tuning Language Models
Tanmay Gautam, Youngsuk Park, Hao Zhou, Parameswaran Raman, Wooseok Ha
0
0
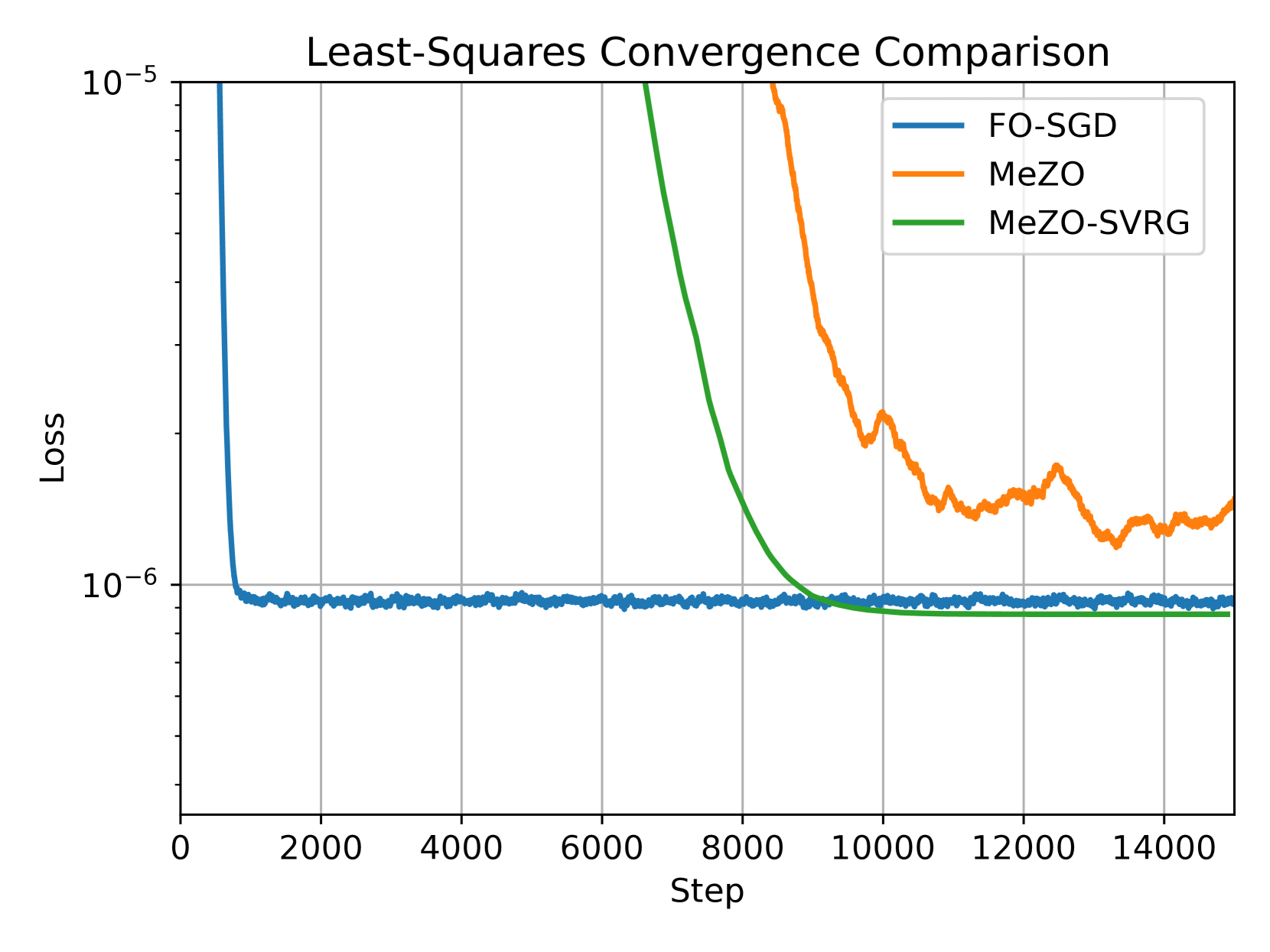
Fine-tuning language models (LMs) has demonstrated success in a wide array of downstream tasks. However, as LMs are scaled up, the memory requirements for backpropagation become prohibitively high. Zeroth-order (ZO) optimization methods can leverage memory-efficient forward passes to estimate gradients. More recently, MeZO, an adaptation of ZO-SGD, has been shown to consistently outperform zero-shot and in-context learning when combined with suitable task prompts. In this work, we couple ZO methods with variance reduction techniques to enhance stability and convergence for inference-based LM fine-tuning. We introduce Memory-Efficient Zeroth-Order Stochastic Variance-Reduced Gradient (MeZO-SVRG) and demonstrate its efficacy across multiple LM fine-tuning tasks, eliminating the reliance on task-specific prompts. Evaluated across a range of both masked and autoregressive LMs on benchmark GLUE tasks, MeZO-SVRG outperforms MeZO with up to 20% increase in test accuracies in both full- and partial-parameter fine-tuning settings. MeZO-SVRG benefits from reduced computation time as it often surpasses MeZO's peak test accuracy with a $2times$ reduction in GPU-hours. MeZO-SVRG significantly reduces the required memory footprint compared to first-order SGD, i.e. by $2times$ for autoregressive models. Our experiments highlight that MeZO-SVRG's memory savings progressively improve compared to SGD with larger batch sizes.
4/15/2024

Model-Agnostic Zeroth-Order Policy Optimization for Meta-Learning of Ergodic Linear Quadratic Regulators
Yunian Pan, Quanyan Zhu
0
0
Meta-learning has been proposed as a promising machine learning topic in recent years, with important applications to image classification, robotics, computer games, and control systems. In this paper, we study the problem of using meta-learning to deal with uncertainty and heterogeneity in ergodic linear quadratic regulators. We integrate the zeroth-order optimization technique with a typical meta-learning method, proposing an algorithm that omits the estimation of policy Hessian, which applies to tasks of learning a set of heterogeneous but similar linear dynamic systems. The induced meta-objective function inherits important properties of the original cost function when the set of linear dynamic systems are meta-learnable, allowing the algorithm to optimize over a learnable landscape without projection onto the feasible set. We provide a convergence result for the exact gradient descent process by analyzing the boundedness and smoothness of the gradient for the meta-objective, which justify the proposed algorithm with gradient estimation error being small. We also provide a numerical example to corroborate this perspective.
5/28/2024