ATNPA: A Unified View of Oversmoothing Alleviation in Graph Neural Networks

0
🧠
Sign in to get full access
Overview
- This paper proposes a new method called ATNPA (Adaptive Topology Normalization and Projection Alignment) for addressing the issue of oversmoothing in graph neural networks (GNNs).
- Oversmoothing is a common problem in GNNs where the node representations become increasingly similar, making it difficult to distinguish different nodes.
- The authors present a unified view of oversmoothing alleviation techniques and show how ATNPA can be used to improve the performance of various GNN models.
Plain English Explanation
The paper deals with a problem called "oversmoothing" that can happen when using graph neural networks (GNNs). In GNNs, the representations of nodes (the way the network represents each node) can become too similar to each other, making it hard to tell different nodes apart. This can hurt the performance of the GNN on various tasks.
The authors propose a new method called ATNPA that aims to fix this oversmoothing problem. ATNPA works by adaptively adjusting the network structure and the way the node representations are projected (transformed) to prevent them from becoming too similar. This helps preserve the unique information about each node, improving the GNN's overall performance.
The paper also provides a broader perspective on different techniques that have been proposed to address the oversmoothing issue in GNNs, showing how ATNPA fits into this bigger picture. By unifying these approaches, the authors hope to give researchers a more comprehensive understanding of the problem and potential solutions.
Technical Explanation
The paper introduces a new method called ATNPA (Adaptive Topology Normalization and Projection Alignment) for addressing the issue of oversmoothing in graph neural networks (GNNs). Oversmoothing is a common problem in GNNs where the node representations become increasingly similar, making it difficult to distinguish different nodes.
The authors present a unified view of oversmoothing alleviation techniques, including spectral graph pruning, global-local normalization, adaptive normalization, and salient subgraph recognition. They show how ATNPA can be used to improve the performance of various GNN models by adaptively adjusting the network structure and the way the node representations are projected.
The ATNPA method consists of two main components:
-
Adaptive Topology Normalization (ATN): This component adaptively normalizes the graph structure to prevent oversmoothing. It learns a graph-specific normalization matrix that can be applied to the adjacency matrix of the graph.
-
Projection Alignment (PA): This component aligns the node representations to prevent them from becoming overly similar. It learns a projection matrix that maps the node representations to a space where the differences between nodes are better preserved.
The authors evaluate ATNPA on a range of benchmark datasets and show that it outperforms state-of-the-art GNN models in various tasks, including node classification, link prediction, and graph classification. They also provide insights into the relationship between the network structure, node representations, and oversmoothing, offering a more comprehensive understanding of this important issue in the field of graph neural networks.
Critical Analysis
The paper presents a well-designed and thorough study of the oversmoothing problem in GNNs and proposes a new method, ATNPA, to address this issue. The authors provide a solid theoretical foundation and a clear, unified view of existing oversmoothing alleviation techniques, which is a valuable contribution to the field.
One potential limitation of the ATNPA method is that it may be computationally more expensive than some other approaches, as it requires learning the adaptive normalization matrix and projection matrix. The authors acknowledge this and suggest that future work could explore more efficient implementations or ways to balance the trade-off between performance and computational cost.
Additionally, the paper could have discussed the potential limitations or caveats of the ATNPA method in more detail. For example, it would be interesting to know how the method performs on larger, more complex graphs or how it handles graphs with different structural properties. The authors could also have explored potential negative societal impacts or ethical considerations related to the use of GNNs and oversmoothing alleviation techniques.
Overall, the paper presents a significant contribution to the field of graph neural networks and offers a promising solution to the oversmoothing problem. The authors' unified perspective and the ATNPA method itself provide a solid foundation for further research and development in this area.
Conclusion
This paper introduces a new method called ATNPA (Adaptive Topology Normalization and Projection Alignment) for addressing the issue of oversmoothing in graph neural networks (GNNs). Oversmoothing is a common problem in GNNs where the node representations become increasingly similar, making it difficult to distinguish different nodes.
The authors present a unified view of oversmoothing alleviation techniques, including spectral graph pruning, global-local normalization, adaptive normalization, and salient subgraph recognition. They show how ATNPA can be used to improve the performance of various GNN models by adaptively adjusting the network structure and the way the node representations are projected.
The ATNPA method consists of two main components: Adaptive Topology Normalization (ATN) and Projection Alignment (PA). ATN adaptively normalizes the graph structure to prevent oversmoothing, while PA aligns the node representations to preserve the differences between nodes.
The authors' evaluation of ATNPA on benchmark datasets demonstrates its effectiveness in improving the performance of GNN models on tasks such as node classification, link prediction, and graph classification. This paper provides a valuable contribution to the field of graph neural networks and offers a promising solution to the oversmoothing problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
ATNPA: A Unified View of Oversmoothing Alleviation in Graph Neural Networks
Yufei Jin, Xingquan Zhu
Oversmoothing is a commonly observed challenge in graph neural network (GNN) learning, where, as layers increase, embedding features learned from GNNs quickly become similar/indistinguishable, making them incapable of differentiating network proximity. A GNN with shallow layer architectures can only learn short-term relation or localized structure information, limiting its power of learning long-term connection, evidenced by their inferior learning performance on heterophilous graphs. Tackling oversmoothing is crucial to harness deep-layer architectures for GNNs. To date, many methods have been proposed to alleviate oversmoothing. The vast difference behind their design principles, combined with graph complications, make it difficult to understand and even compare their difference in tackling the oversmoothing. In this paper, we propose ATNPA, a unified view with five key steps: Augmentation, Transformation, Normalization, Propagation, and Aggregation, to summarize GNN oversmoothing alleviation approaches. We first outline three themes to tackle oversmoothing, and then separate all methods into six categories, followed by detailed reviews of representative methods, including their relation to the ATNPA, and discussion about their niche, strength, and weakness. The review not only draws in-depth understanding of existing methods in the field, but also shows a clear road map for future study.
Read more5/6/2024
🧠
0
Demystifying Oversmoothing in Attention-Based Graph Neural Networks
Xinyi Wu, Amir Ajorlou, Zihui Wu, Ali Jadbabaie
Oversmoothing in Graph Neural Networks (GNNs) refers to the phenomenon where increasing network depth leads to homogeneous node representations. While previous work has established that Graph Convolutional Networks (GCNs) exponentially lose expressive power, it remains controversial whether the graph attention mechanism can mitigate oversmoothing. In this work, we provide a definitive answer to this question through a rigorous mathematical analysis, by viewing attention-based GNNs as nonlinear time-varying dynamical systems and incorporating tools and techniques from the theory of products of inhomogeneous matrices and the joint spectral radius. We establish that, contrary to popular belief, the graph attention mechanism cannot prevent oversmoothing and loses expressive power exponentially. The proposed framework extends the existing results on oversmoothing for symmetric GCNs to a significantly broader class of GNN models, including random walk GCNs, Graph Attention Networks (GATs) and (graph) transformers. In particular, our analysis accounts for asymmetric, state-dependent and time-varying aggregation operators and a wide range of common nonlinear activation functions, such as ReLU, LeakyReLU, GELU and SiLU.
Read more6/5/2024
0
Graph Neural Networks Do Not Always Oversmooth
Bastian Epping, Alexandre Ren'e, Moritz Helias, Michael T. Schaub
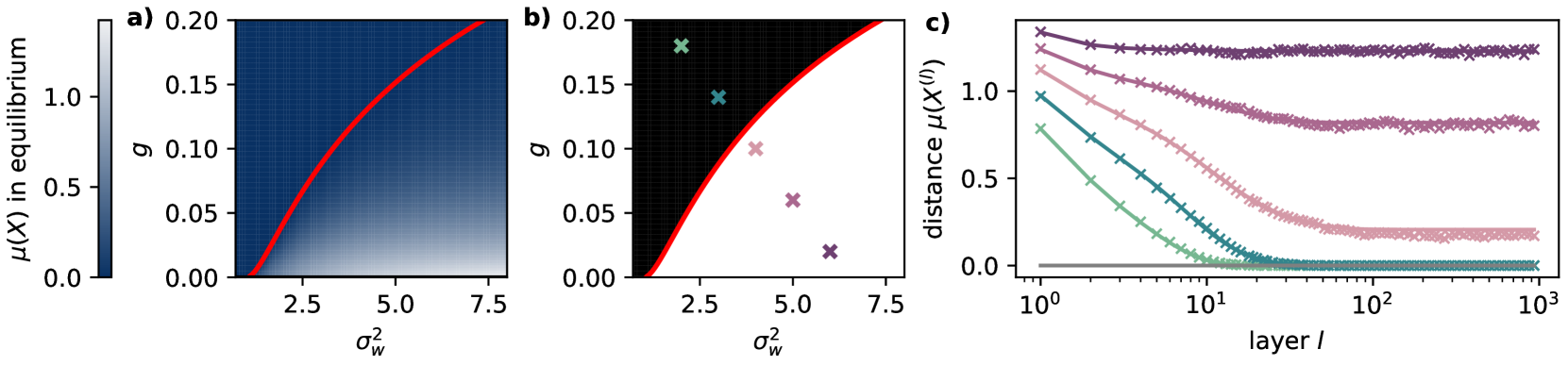
Graph neural networks (GNNs) have emerged as powerful tools for processing relational data in applications. However, GNNs suffer from the problem of oversmoothing, the property that the features of all nodes exponentially converge to the same vector over layers, prohibiting the design of deep GNNs. In this work we study oversmoothing in graph convolutional networks (GCNs) by using their Gaussian process (GP) equivalence in the limit of infinitely many hidden features. By generalizing methods from conventional deep neural networks (DNNs), we can describe the distribution of features at the output layer of deep GCNs in terms of a GP: as expected, we find that typical parameter choices from the literature lead to oversmoothing. The theory, however, allows us to identify a new, nonoversmoothing phase: if the initial weights of the network have sufficiently large variance, GCNs do not oversmooth, and node features remain informative even at large depth. We demonstrate the validity of this prediction in finite-size GCNs by training a linear classifier on their output. Moreover, using the linearization of the GCN GP, we generalize the concept of propagation depth of information from DNNs to GCNs. This propagation depth diverges at the transition between the oversmoothing and non-oversmoothing phase. We test the predictions of our approach and find good agreement with finite-size GCNs. Initializing GCNs near the transition to the non-oversmoothing phase, we obtain networks which are both deep and expressive.
Read more6/5/2024
0
Beyond Over-smoothing: Uncovering the Trainability Challenges in Deep Graph Neural Networks
Jie Peng, Runlin Lei, Zhewei Wei
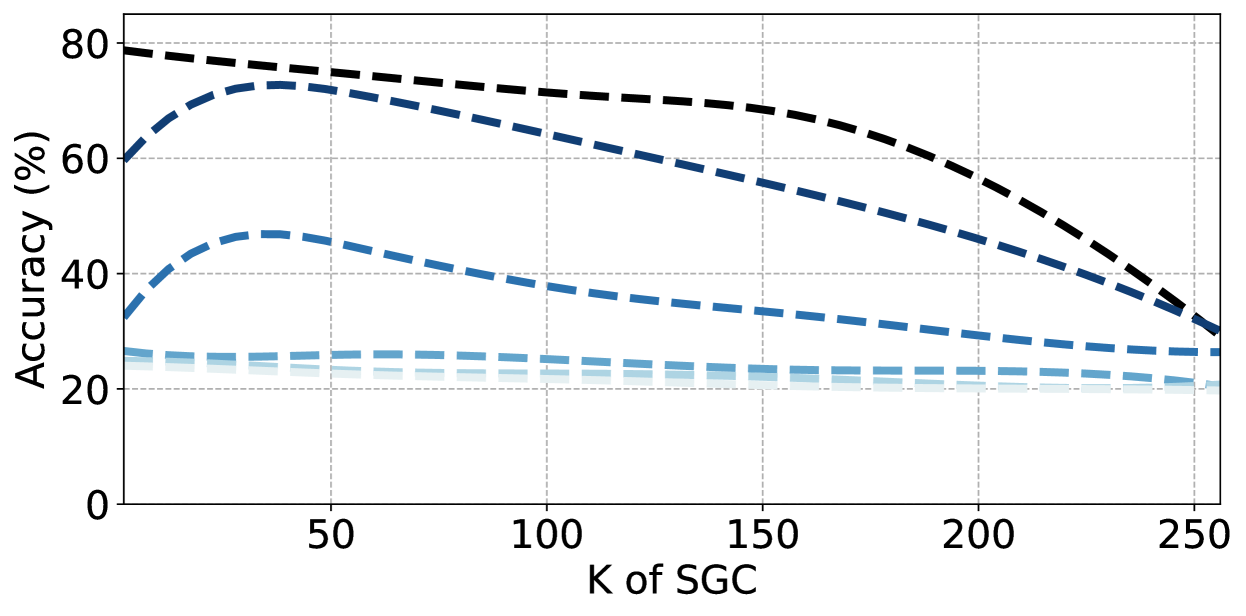
The drastic performance degradation of Graph Neural Networks (GNNs) as the depth of the graph propagation layers exceeds 8-10 is widely attributed to a phenomenon of Over-smoothing. Although recent research suggests that Over-smoothing may not be the dominant reason for such a performance degradation, they have not provided rigorous analysis from a theoretical view, which warrants further investigation. In this paper, we systematically analyze the real dominant problem in deep GNNs and identify the issues that these GNNs towards addressing Over-smoothing essentially work on via empirical experiments and theoretical gradient analysis. We theoretically prove that the difficult training problem of deep MLPs is actually the main challenge, and various existing methods that supposedly tackle Over-smoothing actually improve the trainability of MLPs, which is the main reason for their performance gains. Our further investigation into trainability issues reveals that properly constrained smaller upper bounds of gradient flow notably enhance the trainability of GNNs. Experimental results on diverse datasets demonstrate consistency between our theoretical findings and empirical evidence. Our analysis provides new insights in constructing deep graph models.
Read more8/9/2024