Preferred-Action-Optimized Diffusion Policies for Offline Reinforcement Learning
2405.18729
0
0
Abstract
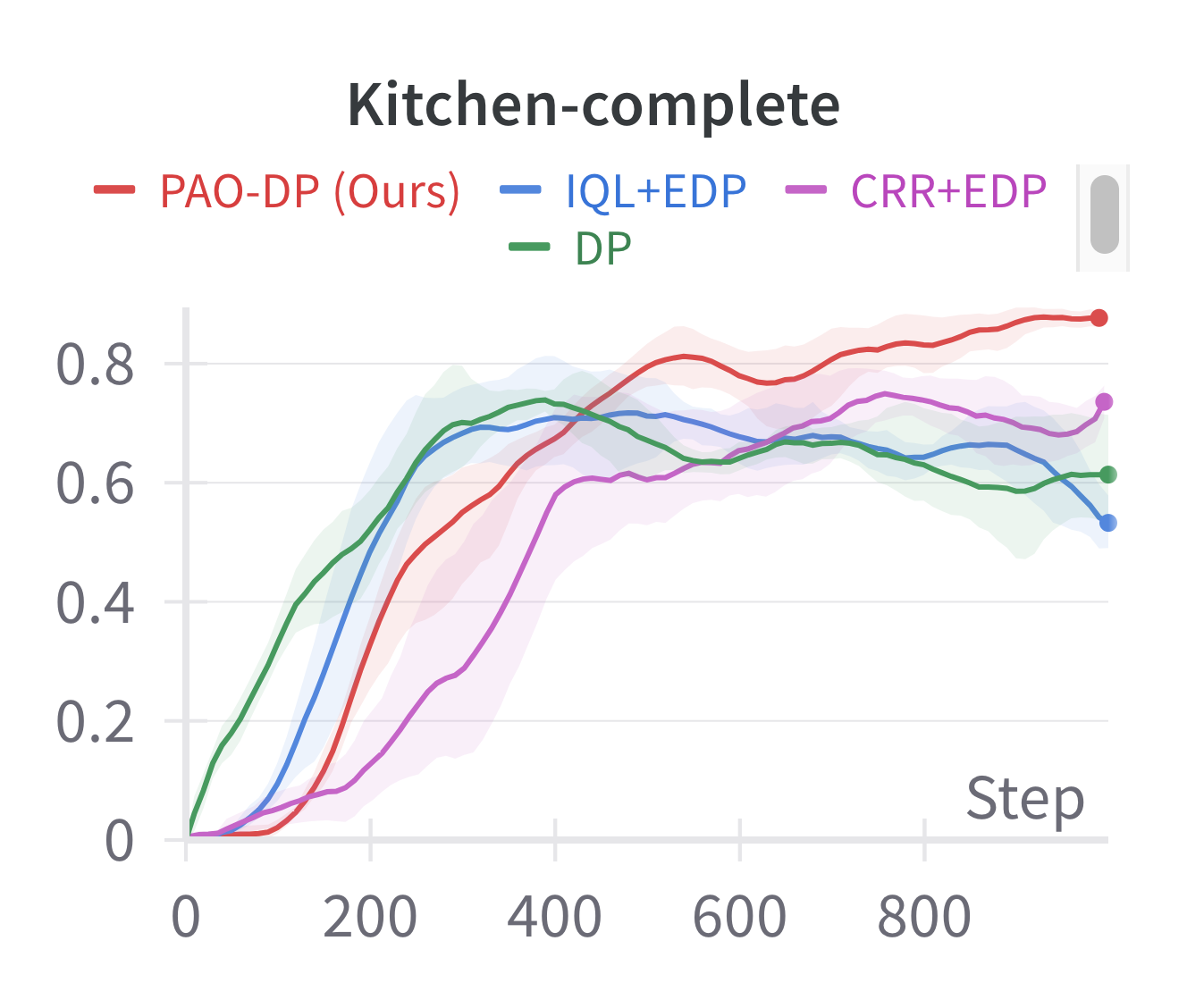
Offline reinforcement learning (RL) aims to learn optimal policies from previously collected datasets. Recently, due to their powerful representational capabilities, diffusion models have shown significant potential as policy models for offline RL issues. However, previous offline RL algorithms based on diffusion policies generally adopt weighted regression to improve the policy. This approach optimizes the policy only using the collected actions and is sensitive to Q-values, which limits the potential for further performance enhancement. To this end, we propose a novel preferred-action-optimized diffusion policy for offline RL. In particular, an expressive conditional diffusion model is utilized to represent the diverse distribution of a behavior policy. Meanwhile, based on the diffusion model, preferred actions within the same behavior distribution are automatically generated through the critic function. Moreover, an anti-noise preference optimization is designed to achieve policy improvement by using the preferred actions, which can adapt to noise-preferred actions for stable training. Extensive experiments demonstrate that the proposed method provides competitive or superior performance compared to previous state-of-the-art offline RL methods, particularly in sparse reward tasks such as Kitchen and AntMaze. Additionally, we empirically prove the effectiveness of anti-noise preference optimization.
Create account to get full access
Overview
- This paper introduces a novel approach called Preferred-Action-Optimized Diffusion (PAOD) for offline reinforcement learning.
- PAOD aims to learn a diffusion policy that generates trajectories that are similar to the preferred actions in the offline dataset.
- The method is designed to address the challenge of sparse rewards in offline RL, where the offline dataset may not contain enough information to directly learn an optimal policy.
Plain English Explanation
The paper presents a new technique called Preferred-Action-Optimized Diffusion (PAOD) for solving reinforcement learning problems using offline data. In many real-world situations, it can be difficult or expensive to collect large amounts of interactive data to train a reinforcement learning agent. Instead, PAOD tries to learn a policy by looking at a fixed dataset of previous interactions, without the ability to actively explore the environment.
The key idea behind PAOD is to learn a "diffusion" policy that generates trajectories (sequences of actions and states) that are similar to the "preferred" actions in the offline dataset. The preferred actions are those that are deemed to be high-quality or desirable, based on some measure of reward or performance. By learning to mimic these preferred actions, the PAOD policy can effectively learn a good behavior without having to discover it through trial-and-error exploration.
This approach is particularly useful when the offline dataset has sparse rewards, meaning that there are only a few instances of highly rewarded actions. In such cases, it can be challenging for traditional reinforcement learning methods to learn an optimal policy. PAOD aims to overcome this challenge by focusing on learning a policy that captures the essence of the preferred actions, rather than trying to directly optimize for the sparse rewards.
Technical Explanation
The paper formalizes the PAOD approach within the framework of offline reinforcement learning. The key components are:
-
Preferred Action Identification: The first step is to identify the "preferred" actions in the offline dataset, which serve as the target for the learned policy. This is done by computing a heuristic reward score for each action and selecting the top-performing ones as the preferred actions.
-
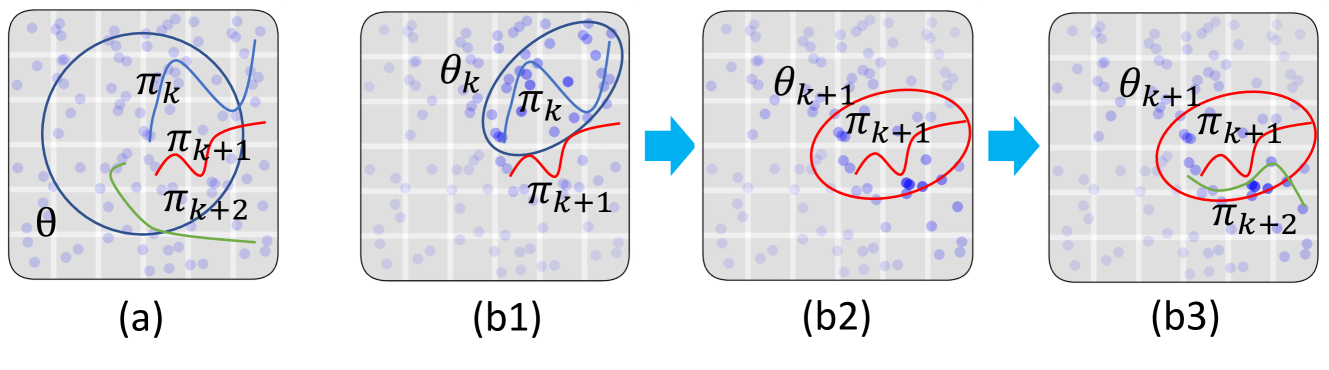
Diffusion Policy Learning: The core of the PAOD method is a diffusion model that learns to generate trajectories that are similar to the preferred actions. This is formulated as a conditional diffusion process, where the model learns to transition from initial states to desired states (i.e., the preferred actions) in a step-by-step manner.
-
Optimization: The diffusion policy is trained by minimizing a combination of the reconstruction loss (how well the generated trajectories match the preferred actions) and a regularization term (to encourage diverse exploration).
The paper demonstrates the effectiveness of PAOD on several challenging offline reinforcement learning benchmarks, including Diffusion-Based Reinforcement Learning via Q-Weighted Action Sampling and Trajectory-Oriented Policy Optimization for Sparse Rewards. The results show that PAOD can achieve strong performance while addressing the challenge of sparse rewards in the offline setting.
Critical Analysis
The paper provides a well-designed and thoroughly evaluated approach to offline reinforcement learning, addressing the important challenge of learning from limited and sparse data. The key strengths of the PAOD method are its ability to effectively capture the essence of preferred actions in the offline dataset and its principled formulation as a diffusion process.
However, the paper also acknowledges several limitations and areas for future research:
-
Sensitivity to Preferred Action Identification: The performance of PAOD is heavily dependent on the quality of the preferred action identification step. If the heuristic used to select preferred actions is not well-calibrated, it could lead to suboptimal learning.
-
Scalability to High-Dimensional Actions: The current PAOD formulation may struggle with high-dimensional action spaces, as the diffusion process could become increasingly complex and difficult to optimize.
-
Generalization to Unseen States: The paper focuses on generating trajectories that match the preferred actions in the offline dataset. It is unclear how well the learned policy would generalize to unseen states or situations not represented in the training data.
-
Interpretability and Explainability: The diffusion-based approach used in PAOD is relatively complex, and it may be challenging to interpret the inner workings of the learned policy and understand the reasoning behind its decisions.
These limitations and areas for future work highlight the ongoing challenges in the field of offline reinforcement learning and the need for continued research to address these issues.
Conclusion
The Preferred-Action-Optimized Diffusion (PAOD) method introduced in this paper presents a promising approach to offline reinforcement learning, particularly in scenarios with sparse rewards. By learning a diffusion policy that generates trajectories similar to preferred actions in the offline dataset, PAOD can effectively learn good behaviors without the need for extensive exploration.
The paper's rigorous evaluation and thoughtful discussion of limitations and future research directions suggest that PAOD is a valuable contribution to the field of reinforcement learning. As researchers continue to tackle the challenges of learning from limited data, techniques like PAOD may play an important role in expanding the applicability of reinforcement learning to real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion Policies creating a Trust Region for Offline Reinforcement Learning
Tianyu Chen, Zhendong Wang, Mingyuan Zhou
0
0
Offline reinforcement learning (RL) leverages pre-collected datasets to train optimal policies. Diffusion Q-Learning (DQL), introducing diffusion models as a powerful and expressive policy class, significantly boosts the performance of offline RL. However, its reliance on iterative denoising sampling to generate actions slows down both training and inference. While several recent attempts have tried to accelerate diffusion-QL, the improvement in training and/or inference speed often results in degraded performance. In this paper, we introduce a dual policy approach, Diffusion Trusted Q-Learning (DTQL), which comprises a diffusion policy for pure behavior cloning and a practical one-step policy. We bridge the two polices by a newly introduced diffusion trust region loss. The diffusion policy maintains expressiveness, while the trust region loss directs the one-step policy to explore freely and seek modes within the region defined by the diffusion policy. DTQL eliminates the need for iterative denoising sampling during both training and inference, making it remarkably computationally efficient. We evaluate its effectiveness and algorithmic characteristics against popular Kullback-Leibler (KL) based distillation methods in 2D bandit scenarios and gym tasks. We then show that DTQL could not only outperform other methods on the majority of the D4RL benchmark tasks but also demonstrate efficiency in training and inference speeds. The PyTorch implementation is available at https://github.com/TianyuCodings/Diffusion_Trusted_Q_Learning.
6/4/2024

DiffPoGAN: Diffusion Policies with Generative Adversarial Networks for Offline Reinforcement Learning
Xuemin Hu, Shen Li, Yingfen Xu, Bo Tang, Long Chen
0
0
Offline reinforcement learning (RL) can learn optimal policies from pre-collected offline datasets without interacting with the environment, but the sampled actions of the agent cannot often cover the action distribution under a given state, resulting in the extrapolation error issue. Recent works address this issue by employing generative adversarial networks (GANs). However, these methods often suffer from insufficient constraints on policy exploration and inaccurate representation of behavior policies. Moreover, the generator in GANs fails in fooling the discriminator while maximizing the expected returns of a policy. Inspired by the diffusion, a generative model with powerful feature expressiveness, we propose a new offline RL method named Diffusion Policies with Generative Adversarial Networks (DiffPoGAN). In this approach, the diffusion serves as the policy generator to generate diverse distributions of actions, and a regularization method based on maximum likelihood estimation (MLE) is developed to generate data that approximate the distribution of behavior policies. Besides, we introduce an additional regularization term based on the discriminator output to effectively constrain policy exploration for policy improvement. Comprehensive experiments are conducted on the datasets for deep data-driven reinforcement learning (D4RL), and experimental results show that DiffPoGAN outperforms state-of-the-art methods in offline RL.
6/14/2024
Learning from Random Demonstrations: Offline Reinforcement Learning with Importance-Sampled Diffusion Models
Zeyu Fang, Tian Lan
0
0
Generative models such as diffusion have been employed as world models in offline reinforcement learning to generate synthetic data for more effective learning. Existing work either generates diffusion models one-time prior to training or requires additional interaction data to update it. In this paper, we propose a novel approach for offline reinforcement learning with closed-loop policy evaluation and world-model adaptation. It iteratively leverages a guided diffusion world model to directly evaluate the offline target policy with actions drawn from it, and then performs an importance-sampled world model update to adaptively align the world model with the updated policy. We analyzed the performance of the proposed method and provided an upper bound on the return gap between our method and the real environment under an optimal policy. The result sheds light on various factors affecting learning performance. Evaluations in the D4RL environment show significant improvement over state-of-the-art baselines, especially when only random or medium-expertise demonstrations are available -- thus requiring improved alignment between the world model and offline policy evaluation.
5/31/2024
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
0
0
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
6/27/2024