AttacKG+:Boosting Attack Knowledge Graph Construction with Large Language Models
2405.04753
0
0
💬
Abstract
Attack knowledge graph construction seeks to convert textual cyber threat intelligence (CTI) reports into structured representations, portraying the evolutionary traces of cyber attacks. Even though previous research has proposed various methods to construct attack knowledge graphs, they generally suffer from limited generalization capability to diverse knowledge types as well as requirement of expertise in model design and tuning. Addressing these limitations, we seek to utilize Large Language Models (LLMs), which have achieved enormous success in a broad range of tasks given exceptional capabilities in both language understanding and zero-shot task fulfillment. Thus, we propose a fully automatic LLM-based framework to construct attack knowledge graphs named: AttacKG+. Our framework consists of four consecutive modules: rewriter, parser, identifier, and summarizer, each of which is implemented by instruction prompting and in-context learning empowered by LLMs. Furthermore, we upgrade the existing attack knowledge schema and propose a comprehensive version. We represent a cyber attack as a temporally unfolding event, each temporal step of which encapsulates three layers of representation, including behavior graph, MITRE TTP labels, and state summary. Extensive evaluation demonstrates that: 1) our formulation seamlessly satisfies the information needs in threat event analysis, 2) our construction framework is effective in faithfully and accurately extracting the information defined by AttacKG+, and 3) our attack graph directly benefits downstream security practices such as attack reconstruction. All the code and datasets will be released upon acceptance.
Create account to get full access
Overview
- This paper proposes a new framework called AttacKG+ to automatically construct attack knowledge graphs from cyber threat intelligence (CTI) reports.
- The framework uses large language models (LLMs) to perform key tasks like rewriting, parsing, identifying, and summarizing information from the CTI reports.
- The authors also introduce an upgraded attack knowledge schema to represent cyber attacks as temporally unfolding events with multiple layers of information.
Plain English Explanation
The paper describes a new system called AttacKG+ that can automatically convert textual cyber threat reports into structured knowledge graphs. These graphs depict the evolution of cyber attacks, which is valuable for security analysts to understand and respond to threats.
Previous methods for building these attack knowledge graphs often required specialized expertise to design and tune the models. To address this limitation, the researchers turned to large language models - powerful AI systems that can perform a wide variety of language tasks with little customization.
The AttacKG+ framework has four main steps: rewriting the threat reports, parsing the information, identifying key entities and relationships, and summarizing the attack details. All of these steps are powered by instruction prompting and in-context learning with LLMs, making the whole process fully automated.
The authors also propose an enhanced knowledge schema to represent cyber attacks. This schema captures the temporal sequence of an attack, the attacker behaviors involved, the malicious techniques used, and high-level summaries of the attack state. This rich representation aims to satisfy the information needs of security analysts.
The researchers show that AttacKG+ can accurately extract the attack details defined by this new schema, and that the resulting knowledge graphs are beneficial for downstream security applications like attack reconstruction.
Technical Explanation
The core of the AttacKG+ framework is its use of large language models (LLMs) to automate the construction of attack knowledge graphs from cyber threat intelligence (CTI) reports. The framework consists of four main modules:
- Rewriter: This module uses an LLM to paraphrase and simplify the technical language in the CTI reports, making the information more accessible.
- Parser: The LLM is then used to parse the rewritten text and extract structured information about the cyber attack, such as the events, entities, and relationships.
- Identifier: Next, the framework identifies and labels key elements of the attack, such as the attacker behaviors and MITRE TTPs (Tactics, Techniques, and Procedures).
- Summarizer: Finally, the LLM summarizes the attack details and generates a high-level description of the attack state at each temporal step.
To support this process, the authors also propose an upgraded attack knowledge schema that represents cyber attacks as temporally unfolding events. This schema captures three layers of information: a behavior graph, MITRE TTP labels, and state summaries.
The researchers evaluate AttacKG+ extensively, demonstrating its effectiveness in faithfully and accurately extracting the information defined by the new schema. They also show that the resulting attack knowledge graphs can directly benefit downstream security practices, such as attack reconstruction.
Critical Analysis
The AttacKG+ framework represents an innovative approach to leveraging large language models for the important task of constructing attack knowledge graphs from cyber threat intelligence. By automating the process, the authors address a key limitation of previous methods that required specialized expertise.
However, the paper does not extensively discuss potential limitations or caveats of the LLM-based approach. For example, it's unclear how well the system would generalize to new types of cyber threats or highly domain-specific terminology that may be challenging for language models to handle.
Additionally, the authors do not provide a detailed analysis of the potential biases or errors that could be introduced by the LLM-based components. As with any AI system, it's important to carefully examine and mitigate such issues, especially when the output is intended to inform critical security decisions.
Further research could also explore ways to make the knowledge graph construction more interactive, allowing security analysts to provide feedback and guidance to iteratively refine the results. This could help address any shortcomings in the fully automated approach.
Overall, the AttacKG+ framework represents an exciting step forward in leveraging powerful language models for cybersecurity applications. However, continued research and development will be necessary to ensure the system's robustness and reliability in real-world security settings.
Conclusion
This paper presents a novel framework called AttacKG+ that uses large language models to automatically construct attack knowledge graphs from cyber threat intelligence reports. By automating this process, the authors address a key limitation of previous methods that required specialized expertise.
The framework consists of four modules - rewriting, parsing, identifying, and summarizing - all of which are powered by instruction prompting and in-context learning with LLMs. The authors also propose an enhanced knowledge schema to represent cyber attacks as temporally unfolding events with multiple layers of information.
Extensive evaluation demonstrates the effectiveness of the AttacKG+ framework in faithfully extracting the details defined by the new schema and generating knowledge graphs that can benefit downstream security practices. This work represents an exciting advancement in leveraging powerful language models for critical cybersecurity applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
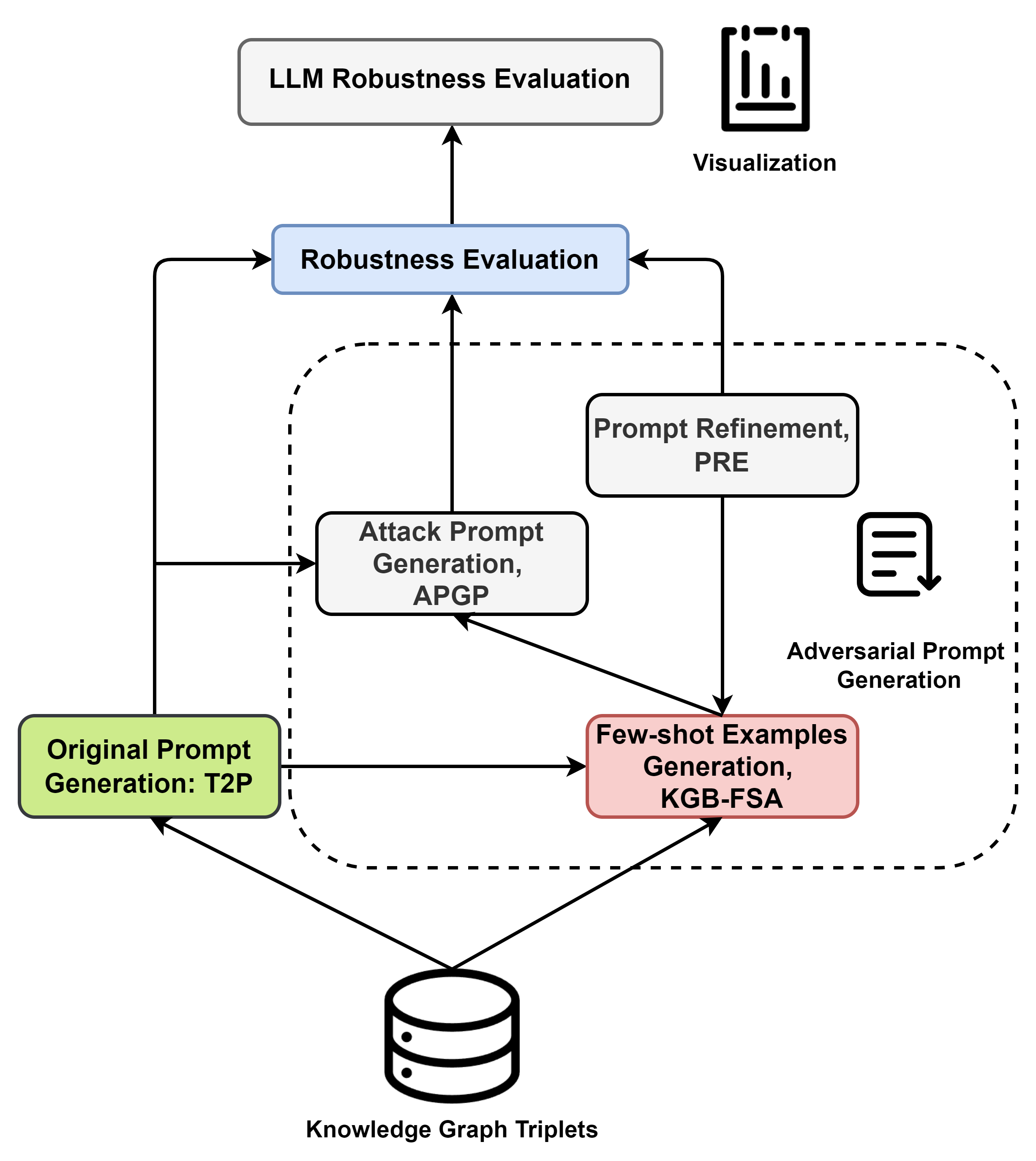
KGPA: Robustness Evaluation for Large Language Models via Cross-Domain Knowledge Graphs
Aihua Pei (Waseda University), Zehua Yang (Waseda University), Shunan Zhu (Waseda University), Ruoxi Cheng (Southeast University), Ju Jia (Southeast University), Lina Wang (Wuhan University)
0
0
Existing frameworks for assessing robustness of large language models (LLMs) overly depend on specific benchmarks, increasing costs and failing to evaluate performance of LLMs in professional domains due to dataset limitations. This paper proposes a framework that systematically evaluates the robustness of LLMs under adversarial attack scenarios by leveraging knowledge graphs (KGs). Our framework generates original prompts from the triplets of knowledge graphs and creates adversarial prompts by poisoning, assessing the robustness of LLMs through the results of these adversarial attacks. We systematically evaluate the effectiveness of this framework and its modules. Experiments show that adversarial robustness of the ChatGPT family ranks as GPT-4-turbo > GPT-4o > GPT-3.5-turbo, and the robustness of large language models is influenced by the professional domains in which they operate.
6/18/2024
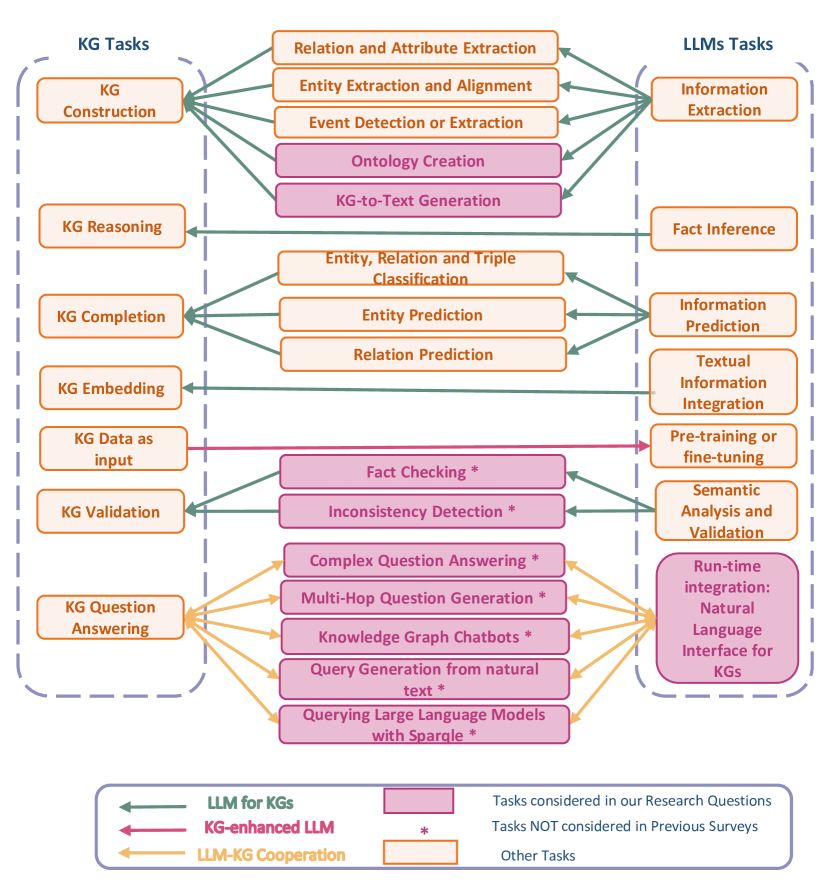
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
💬
BiasKG: Adversarial Knowledge Graphs to Induce Bias in Large Language Models
Chu Fei Luo, Ahmad Ghawanmeh, Xiaodan Zhu, Faiza Khan Khattak
0
0
Modern large language models (LLMs) have a significant amount of world knowledge, which enables strong performance in commonsense reasoning and knowledge-intensive tasks when harnessed properly. The language model can also learn social biases, which has a significant potential for societal harm. There have been many mitigation strategies proposed for LLM safety, but it is unclear how effective they are for eliminating social biases. In this work, we propose a new methodology for attacking language models with knowledge graph augmented generation. We refactor natural language stereotypes into a knowledge graph, and use adversarial attacking strategies to induce biased responses from several open- and closed-source language models. We find our method increases bias in all models, even those trained with safety guardrails. This demonstrates the need for further research in AI safety, and further work in this new adversarial space.
5/9/2024
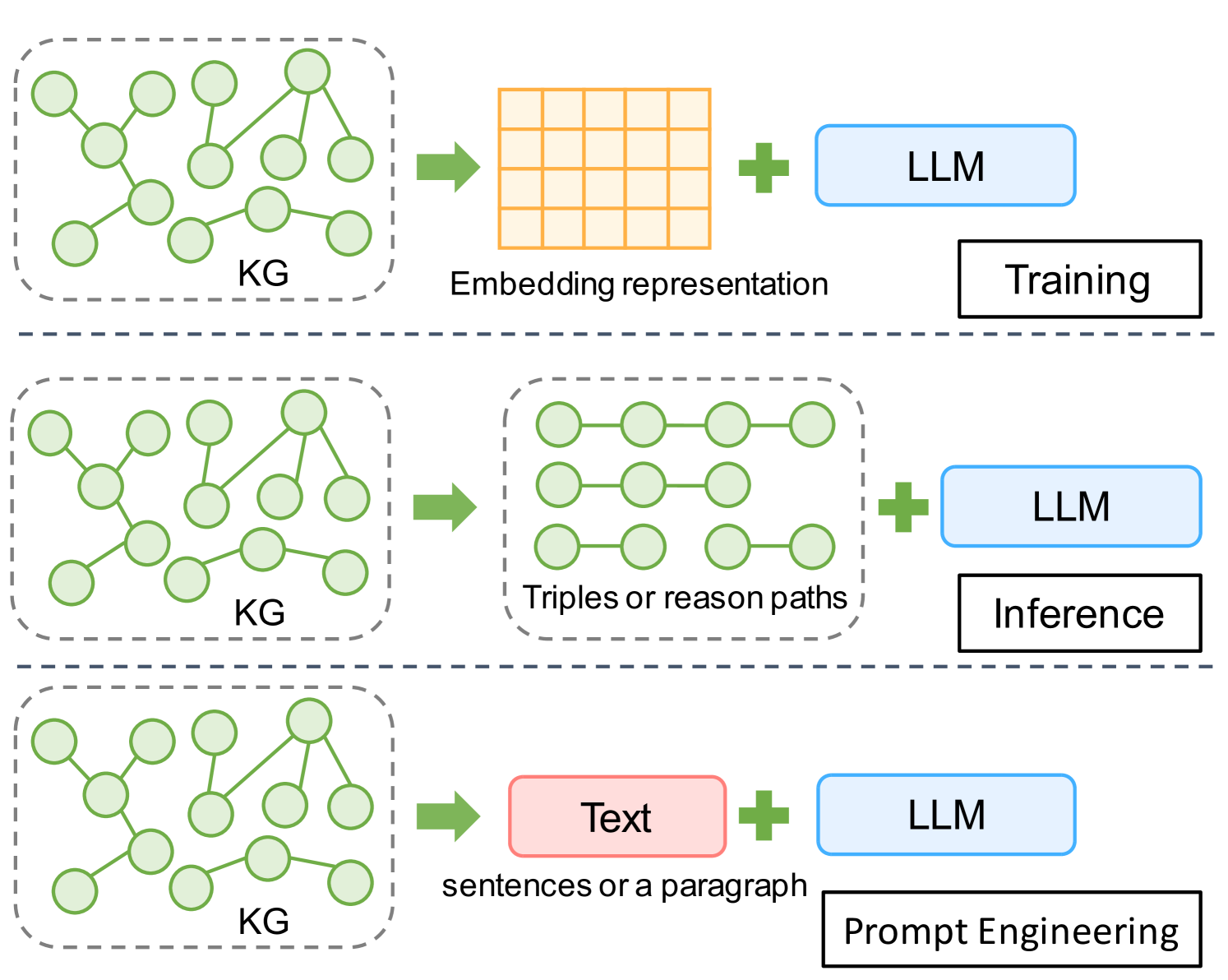
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024