Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
2402.11541
0
0
Abstract
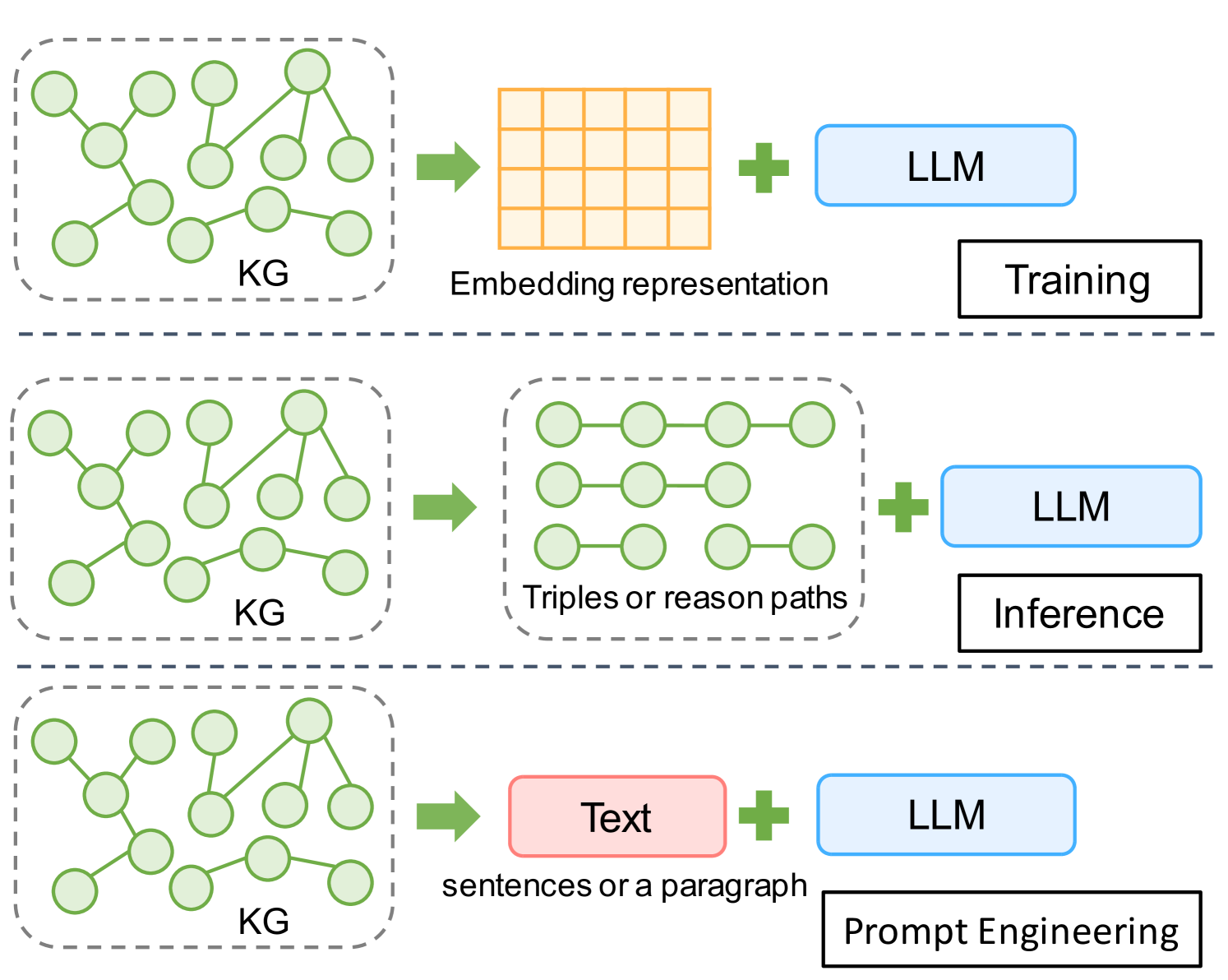
Although the method of enhancing large language models' (LLMs') reasoning ability and reducing their hallucinations through the use of knowledge graphs (KGs) has received widespread attention, the exploration of how to enable LLMs to integrate the structured knowledge in KGs on-the-fly remains inadequate. Researchers often co-train KG embeddings and LLM parameters to equip LLMs with the ability of comprehending KG knowledge. However, this resource-hungry training paradigm significantly increases the model learning cost and is also unsuitable for non-open-source, black-box LLMs. In this paper, we employ complex question answering (CQA) as a task to assess the LLM's ability of comprehending KG knowledge. We conducted a comprehensive comparison of KG knowledge injection methods (from triples to natural language text), aiming to explore the optimal prompting method for supplying KG knowledge to LLMs, thereby enhancing their comprehension of KG. Contrary to our initial expectations, our analysis revealed that LLMs effectively handle messy, noisy, and linearized KG knowledge, outperforming methods that employ well-designed natural language (NL) textual prompts. This counter-intuitive finding provides substantial insights for future research on LLMs' comprehension of structured knowledge.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the surprising finding that large language models (LLMs) can better understand knowledge graphs than previously thought.
- The researchers investigate the knowledge reasoning capabilities of LLMs and how they compare to human performance on tasks related to knowledge graphs.
- The results challenge the common assumption that LLMs struggle with tasks requiring logical reasoning and suggest they may be more capable in this area than expected.
Plain English Explanation
Knowledge graphs are structured databases that represent information as a network of connected concepts and relationships. They are commonly used to store and organize large amounts of knowledge, like the information in encyclopedias or databases.
The paper "Head to Tail: How Knowledgeable Are Large Language Models?" has shown that LLMs like GPT-3 can understand and reason about the information in knowledge graphs quite well. This is surprising because LLMs are often thought to struggle with logical reasoning and tasks that require structured knowledge.
The researchers in this new paper decided to further investigate this phenomenon. They designed experiments to test how LLMs perform on various knowledge graph reasoning tasks, and compared the results to human performance. Contrary to expectations, they found that LLMs can sometimes outperform humans on these types of tasks.
This suggests that LLMs may have more advanced reasoning capabilities than previously believed. They may be able to extract and manipulate structured knowledge from text in ways that are more sophisticated than we thought.
Technical Explanation
The paper examines the knowledge reasoning capabilities of large language models (LLMs) by comparing their performance to human performance on a range of tasks related to knowledge graphs.
The researchers first constructed a benchmark suite of knowledge graph reasoning tasks, which tested the models' ability to understand concepts, relationships, and logical inferences within the knowledge graph. They evaluated several state-of-the-art LLMs, including GPT-3, on this benchmark.
Surprisingly, the results showed that the LLMs were able to outperform human participants on many of the tasks, especially those requiring logical reasoning and inference. The models demonstrated a strong ability to traverse the knowledge graph, identify relevant connections, and make deductions about the underlying information.
Further analysis revealed that the LLMs were able to effectively leverage the structured knowledge representation in the knowledge graphs, despite their training on unstructured text data. This challenges the common assumption that LLMs struggle with tasks requiring logical reasoning and structured knowledge.
The paper suggests that the knowledge reasoning capabilities of LLMs are more advanced than previously thought, and that these models may be better able to understand and reason about structured knowledge than humans in certain contexts. This has important implications for the development of knowledge-intensive AI systems and their potential applications.
Critical Analysis
The paper presents compelling evidence that LLMs can achieve superior performance on knowledge graph reasoning tasks compared to humans. This challenges the prevailing view that LLMs struggle with logical reasoning and structured knowledge. However, the authors acknowledge several important caveats and limitations to their findings.
First, the benchmark tasks used in the study may not fully capture the complexity and diversity of real-world knowledge graph reasoning. The tasks were designed to isolate specific capabilities, but in practice, knowledge graph reasoning often involves more nuanced and contextual understanding.
Additionally, the study focused on a limited set of LLM architectures and configurations. It's possible that other LLM models or training approaches could exhibit different capabilities when it comes to knowledge graph reasoning.
The paper also does not explore the underlying mechanisms that allow LLMs to outperform humans on these tasks. More research is needed to understand how LLMs are able to effectively leverage the structured information in knowledge graphs, and whether this capability generalizes to other types of structured data.
Finally, the authors note that while the LLMs demonstrated strong performance, there may be certain types of reasoning or tasks where human experts still maintain an advantage. Further research is needed to fully characterize the strengths and limitations of LLMs compared to human intelligence.
Overall, this paper presents thought-provoking findings that challenge our assumptions about the reasoning capabilities of large language models. However, it also highlights the need for continued investigation and a more nuanced understanding of the relationship between LLMs and structured knowledge.
Conclusion
This paper challenges the common assumption that large language models (LLMs) struggle with tasks requiring logical reasoning and structured knowledge. Through a series of experiments comparing LLM and human performance on knowledge graph reasoning tasks, the researchers found that LLMs can often outperform humans, particularly on tasks involving logical inference and deduction.
These findings suggest that the knowledge reasoning capabilities of LLMs may be more advanced than previously thought. The models appear to be able to effectively leverage the structured information in knowledge graphs, despite being trained primarily on unstructured text data.
This has important implications for the development of knowledge-intensive AI systems that can better understand and reason about complex, structured information. It also raises questions about the nature of intelligence and the comparative capabilities of artificial and human intelligence.
While the paper presents compelling evidence, it also acknowledges important limitations and areas for further research. Continued investigation is needed to fully characterize the strengths and weaknesses of LLMs when it comes to knowledge reasoning, and to explore the underlying mechanisms that enable their surprising performance.
Overall, this paper offers a thought-provoking challenge to our assumptions about the reasoning capabilities of large language models, and suggests new directions for the advancement of AI systems that can better understand and leverage structured knowledge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Wenyu Huang, Guancheng Zhou, Mirella Lapata, Pavlos Vougiouklis, Sebastien Montella, Jeff Z. Pan
0
0
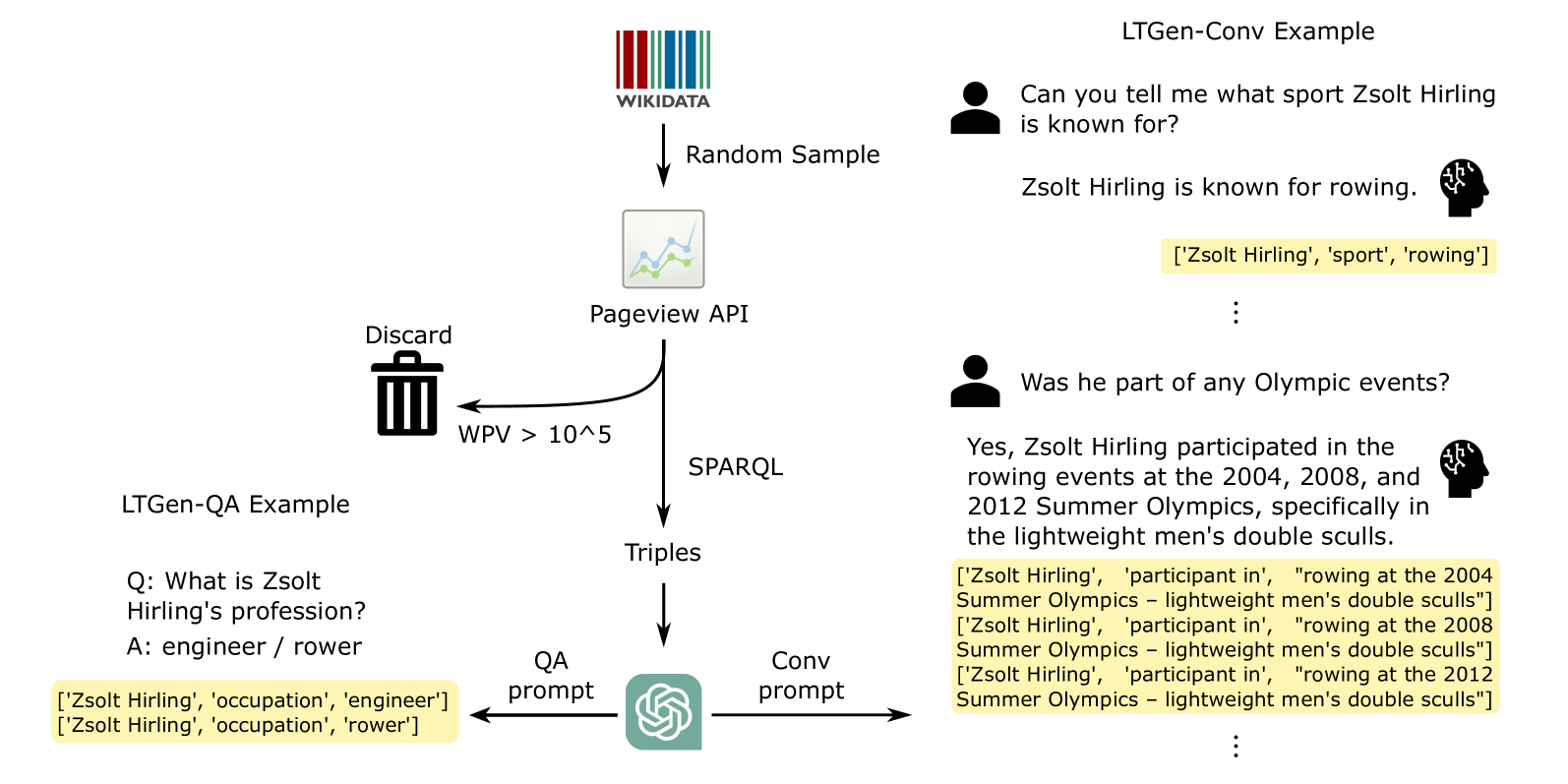
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
5/13/2024
CuriousLLM: Elevating Multi-Document QA with Reasoning-Infused Knowledge Graph Prompting
Zukang Yang, Zixuan Zhu
0
0
In the field of Question Answering (QA), unifying large language models (LLMs) with external databases has shown great success. However, these methods often fall short in providing the advanced reasoning needed for complex QA tasks. To address these issues, we improve over a novel approach called Knowledge Graph Prompting (KGP), which combines knowledge graphs with a LLM-based agent to improve reasoning and search accuracy. Nevertheless, the original KGP framework necessitates costly fine-tuning with large datasets yet still suffers from LLM hallucination. Therefore, we propose a reasoning-infused LLM agent to enhance this framework. This agent mimics human curiosity to ask follow-up questions to more efficiently navigate the search. This simple modification significantly boosts the LLM performance in QA tasks without the high costs and latency associated with the initial KGP framework. Our ultimate goal is to further develop this approach, leading to more accurate, faster, and cost-effective solutions in the QA domain.
4/16/2024
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
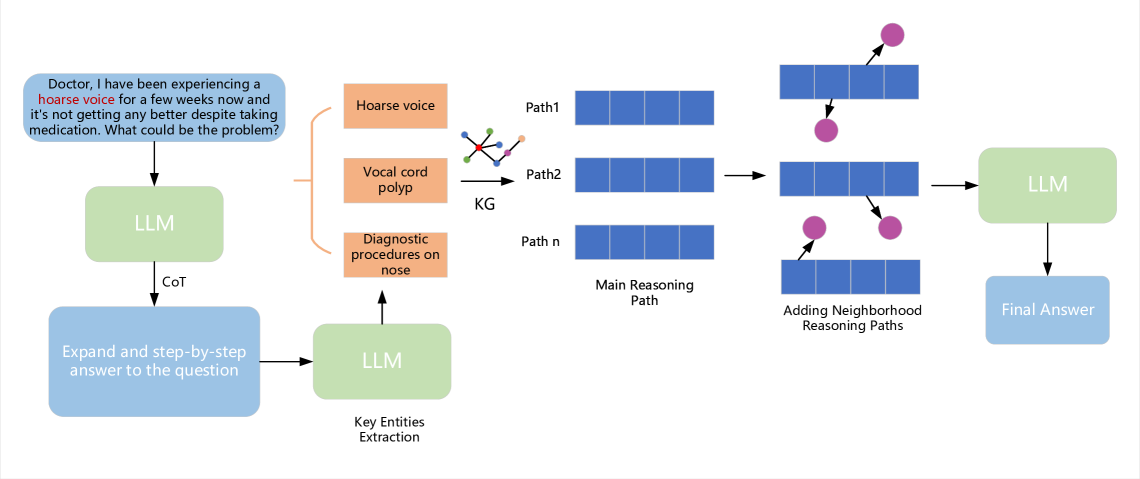
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
💬
Logic Query of Thoughts: Guiding Large Language Models to Answer Complex Logic Queries with Knowledge Graphs
Lihui Liu, Zihao Wang, Ruizhong Qiu, Yikun Ban, Eunice Chan, Yangqiu Song, Jingrui He, Hanghang Tong
0
0
Despite the superb performance in many tasks, large language models (LLMs) bear the risk of generating hallucination or even wrong answers when confronted with tasks that demand the accuracy of knowledge. The issue becomes even more noticeable when addressing logic queries that require multiple logic reasoning steps. On the other hand, knowledge graph (KG) based question answering methods are capable of accurately identifying the correct answers with the help of knowledge graph, yet its accuracy could quickly deteriorate when the knowledge graph itself is sparse and incomplete. It remains a critical challenge on how to integrate knowledge graph reasoning with LLMs in a mutually beneficial way so as to mitigate both the hallucination problem of LLMs as well as the incompleteness issue of knowledge graphs. In this paper, we propose 'Logic-Query-of-Thoughts' (LGOT) which is the first of its kind to combine LLMs with knowledge graph based logic query reasoning. LGOT seamlessly combines knowledge graph reasoning and LLMs, effectively breaking down complex logic queries into easy to answer subquestions. Through the utilization of both knowledge graph reasoning and LLMs, it successfully derives answers for each subquestion. By aggregating these results and selecting the highest quality candidate answers for each step, LGOT achieves accurate results to complex questions. Our experimental findings demonstrate substantial performance enhancements, with up to 20% improvement over ChatGPT.
4/16/2024