BiasKG: Adversarial Knowledge Graphs to Induce Bias in Large Language Models
2405.04756
0
0
💬
Abstract
Modern large language models (LLMs) have a significant amount of world knowledge, which enables strong performance in commonsense reasoning and knowledge-intensive tasks when harnessed properly. The language model can also learn social biases, which has a significant potential for societal harm. There have been many mitigation strategies proposed for LLM safety, but it is unclear how effective they are for eliminating social biases. In this work, we propose a new methodology for attacking language models with knowledge graph augmented generation. We refactor natural language stereotypes into a knowledge graph, and use adversarial attacking strategies to induce biased responses from several open- and closed-source language models. We find our method increases bias in all models, even those trained with safety guardrails. This demonstrates the need for further research in AI safety, and further work in this new adversarial space.
Create account to get full access
Overview
- Large language models (LLMs) have a vast amount of knowledge, allowing them to perform well on tasks requiring reasoning and knowledge
- However, LLMs can also learn and exhibit social biases, which can be harmful to society
- Researchers have proposed many strategies to mitigate the safety risks of LLMs, but it is unclear how effective they are at eliminating biases
- This work proposes a new approach to attack LLMs by constructing a knowledge graph of stereotypes and using adversarial techniques to induce biased responses
- The researchers find that their method increases bias in various LLMs, even those with safety measures, highlighting the need for further research in AI safety
Plain English Explanation
Large language models are artificial intelligence systems that can understand and generate human-like text. These models have access to a huge amount of information, which allows them to perform well on tasks that require reasoning and knowledge. However, these models can also pick up on and exhibit societal biases, which can lead to harmful outcomes.
Researchers have proposed many different strategies to try to make these language models safer and less biased. But it's unclear how effective these approaches are at completely eliminating biases.
In this new study, the researchers take a different approach. They create a knowledge graph that captures common stereotypes and biases. Then, they use this knowledge graph to actively try to make the language models produce biased responses, almost like attacking the models.
The researchers found that their attack method was able to increase the level of bias in various language models, even those that had been trained with safety measures in place. This demonstrates that the problem of bias in large language models is still a significant challenge that requires more research and better solutions.
The key takeaway is that while large language models are powerful, we need to be very careful about the biases and societal harms they can perpetuate. More work is needed to ensure these systems are safe and equitable for everyone.
Technical Explanation
The researchers in this paper propose a new methodology for attacking large language models (LLMs) by leveraging a knowledge graph of stereotypes. They construct a knowledge graph that captures common natural language stereotypes and then use adversarial attacking strategies to induce biased responses from several open-source and closed-source LLMs.
The researchers find that their attack method is effective at increasing the level of bias exhibited by the tested LLMs, even for those models that have been trained with various safety guardrails in place, as described in related work such as [[https://aimodels.fyi/papers/arxiv/causal-explainable-guardrails-large-language-models|Causal and Explainable Guardrails for Large Language Models]].
This demonstrates the significant challenge of eliminating social biases in large language models, as even advanced mitigation techniques may not be sufficient, as explored in [[https://aimodels.fyi/papers/arxiv/counter-intuitive-large-language-models-can-better|Counter-Intuitive: Large Language Models Can Better Learn from Fewer Examples]]. The researchers argue that this work highlights the need for further research in AI safety, and the exploration of new adversarial spaces, as proposed in [[https://aimodels.fyi/papers/arxiv/rlrfreinforcement-learning-from-reflection-through-debates-as|Reinforcement Learning from Reflection through Debates as a Safety Net for Large Language Models]].
Critical Analysis
The researchers provide a compelling demonstration of the difficulties in fully mitigating social biases in large language models. By constructing a knowledge graph of stereotypes and using it to actively induce biased responses, they show that even models with safety measures in place can still be vulnerable to producing harmful outputs.
However, the researchers acknowledge that their attack method is a somewhat narrow approach, focused on exploiting specific stereotypes. It remains to be seen how generalizable their findings are to other types of biases or more nuanced forms of bias. Further research would be needed to assess the broader applicability of this attack strategy.
Additionally, the researchers do not provide a detailed analysis of the specific biases that were amplified through their attacks. A more granular understanding of the nature and origins of these biases could help inform the development of more robust mitigation strategies, as explored in [[https://aimodels.fyi/papers/arxiv/evaluating-mitigating-linguistic-discrimination-large-language-models|Evaluating and Mitigating Linguistic Discrimination in Large Language Models]].
Overall, this work highlights the significant challenge of ensuring the safety and fairness of large language models, and the need for continued innovation in the field of AI safety. Developing a comprehensive understanding of the sources and manifestations of bias, and designing effective mitigation strategies, will be crucial for realizing the full potential of these powerful technologies while minimizing their societal harms.
Conclusion
This paper presents a new methodology for attacking large language models by leveraging a knowledge graph of stereotypes. The researchers demonstrate that their approach can induce biased responses from various LLMs, even those that have been trained with safety measures in place.
The key takeaway is that the problem of bias in large language models is still a significant challenge that requires further research and more effective solutions. While many strategies have been proposed to mitigate these issues, this work suggests that more robust and comprehensive approaches are needed to truly eliminate harmful social biases from these powerful AI systems.
As large language models continue to advance and become more ubiquitous, ensuring their safety and fairness will be of paramount importance. The findings of this study underscore the critical need for ongoing innovation and diligence in the field of AI safety, to help realize the transformative potential of these technologies while protecting against their potential for societal harm.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
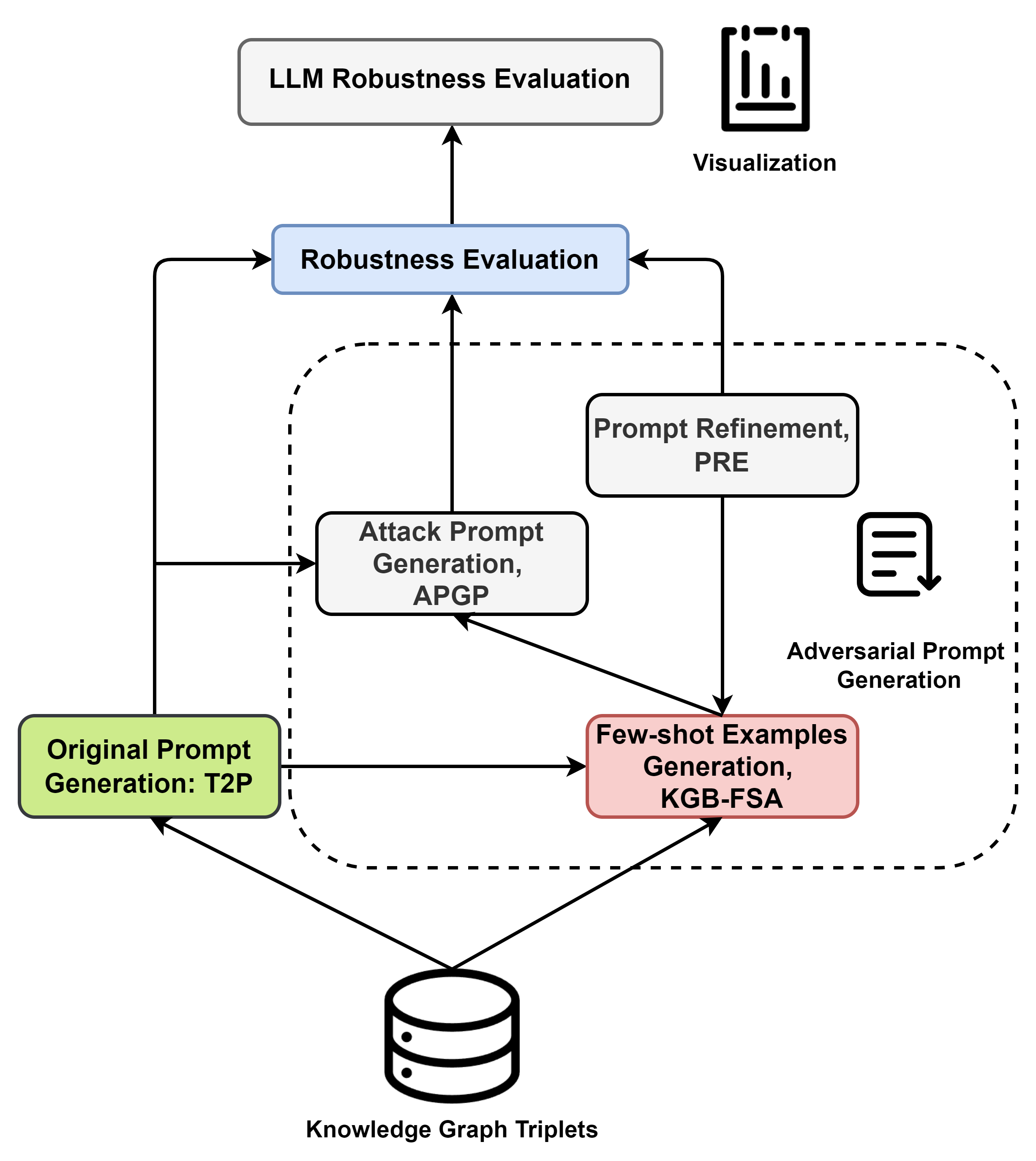
KGPA: Robustness Evaluation for Large Language Models via Cross-Domain Knowledge Graphs
Aihua Pei (Waseda University), Zehua Yang (Waseda University), Shunan Zhu (Waseda University), Ruoxi Cheng (Southeast University), Ju Jia (Southeast University), Lina Wang (Wuhan University)
0
0
Existing frameworks for assessing robustness of large language models (LLMs) overly depend on specific benchmarks, increasing costs and failing to evaluate performance of LLMs in professional domains due to dataset limitations. This paper proposes a framework that systematically evaluates the robustness of LLMs under adversarial attack scenarios by leveraging knowledge graphs (KGs). Our framework generates original prompts from the triplets of knowledge graphs and creates adversarial prompts by poisoning, assessing the robustness of LLMs through the results of these adversarial attacks. We systematically evaluate the effectiveness of this framework and its modules. Experiments show that adversarial robustness of the ChatGPT family ranks as GPT-4-turbo > GPT-4o > GPT-3.5-turbo, and the robustness of large language models is influenced by the professional domains in which they operate.
6/18/2024
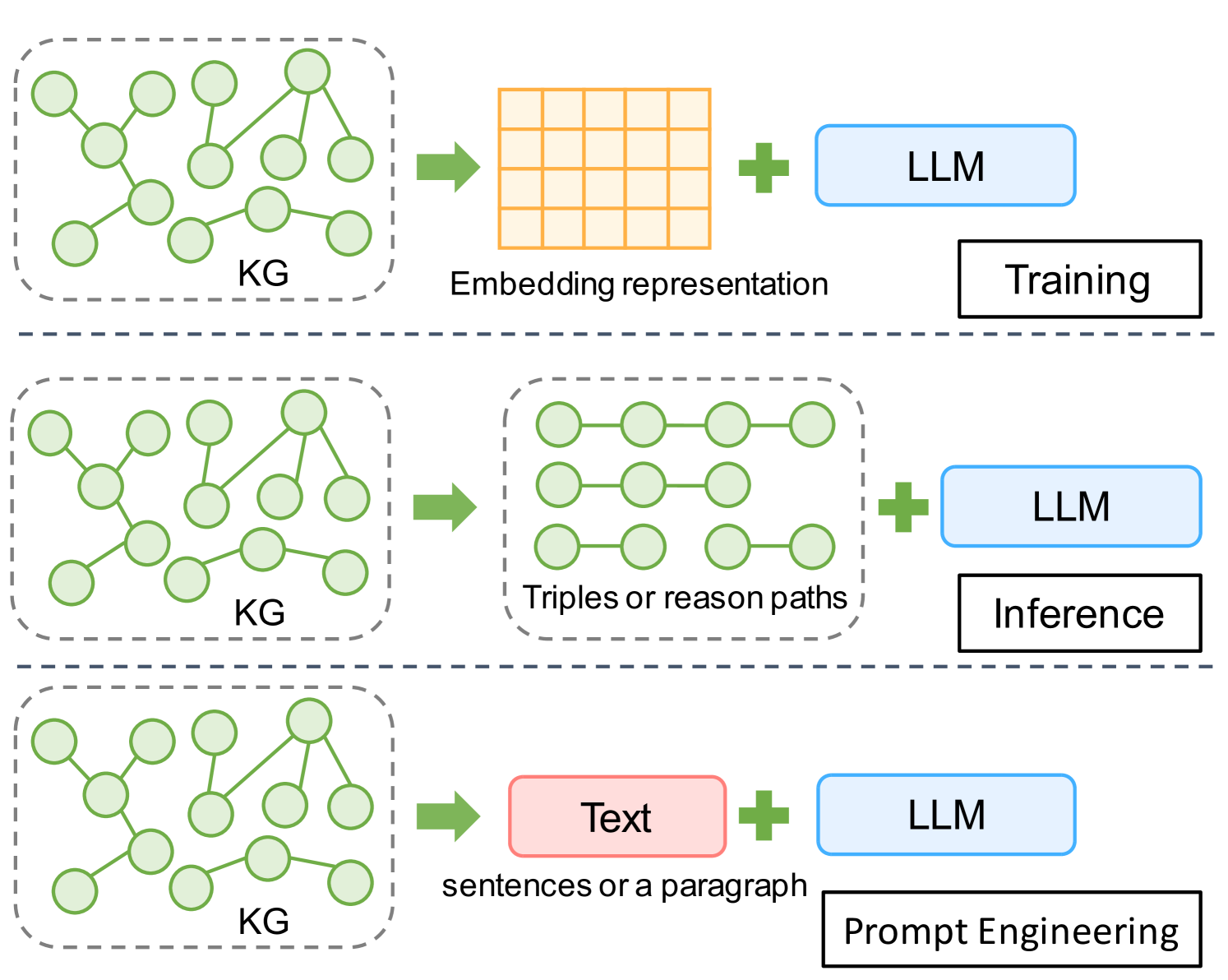
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
💬
AttacKG+:Boosting Attack Knowledge Graph Construction with Large Language Models
Yongheng Zhang, Tingwen Du, Yunshan Ma, Xiang Wang, Yi Xie, Guozheng Yang, Yuliang Lu, Ee-Chien Chang
0
0
Attack knowledge graph construction seeks to convert textual cyber threat intelligence (CTI) reports into structured representations, portraying the evolutionary traces of cyber attacks. Even though previous research has proposed various methods to construct attack knowledge graphs, they generally suffer from limited generalization capability to diverse knowledge types as well as requirement of expertise in model design and tuning. Addressing these limitations, we seek to utilize Large Language Models (LLMs), which have achieved enormous success in a broad range of tasks given exceptional capabilities in both language understanding and zero-shot task fulfillment. Thus, we propose a fully automatic LLM-based framework to construct attack knowledge graphs named: AttacKG+. Our framework consists of four consecutive modules: rewriter, parser, identifier, and summarizer, each of which is implemented by instruction prompting and in-context learning empowered by LLMs. Furthermore, we upgrade the existing attack knowledge schema and propose a comprehensive version. We represent a cyber attack as a temporally unfolding event, each temporal step of which encapsulates three layers of representation, including behavior graph, MITRE TTP labels, and state summary. Extensive evaluation demonstrates that: 1) our formulation seamlessly satisfies the information needs in threat event analysis, 2) our construction framework is effective in faithfully and accurately extracting the information defined by AttacKG+, and 3) our attack graph directly benefits downstream security practices such as attack reconstruction. All the code and datasets will be released upon acceptance.
5/9/2024
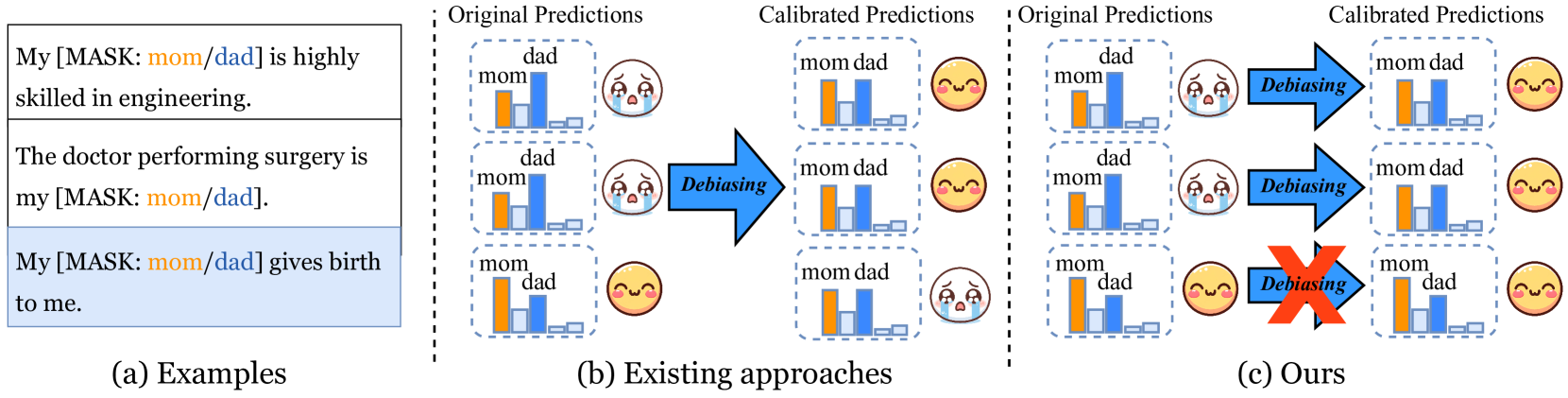
Large Language Model Bias Mitigation from the Perspective of Knowledge Editing
Ruizhe Chen, Yichen Li, Zikai Xiao, Zuozhu Liu
0
0
Existing debiasing methods inevitably make unreasonable or undesired predictions as they are designated and evaluated to achieve parity across different social groups but leave aside individual facts, resulting in modified existing knowledge. In this paper, we first establish a new bias mitigation benchmark BiasKE leveraging existing and additional constructed datasets, which systematically assesses debiasing performance by complementary metrics on fairness, specificity, and generalization. Meanwhile, we propose a novel debiasing method, Fairness Stamp (FAST), which enables editable fairness through fine-grained calibration on individual biased knowledge. Comprehensive experiments demonstrate that FAST surpasses state-of-the-art baselines with remarkable debiasing performance while not hampering overall model capability for knowledge preservation, highlighting the prospect of fine-grained debiasing strategies for editable fairness in LLMs.
5/16/2024