Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection

0
Sign in to get full access
Overview
- Introduces a novel approach for anomaly detection using attention-aware entropy distillation
- Proposes a framework that combines spatial and channel attention mechanisms to capture relevant features for anomaly detection
- Leverages knowledge distillation to transfer learned representations from a teacher model to a smaller student model, improving efficiency and performance
Plain English Explanation
This research paper presents a new method for detecting anomalies, which are unusual or unexpected patterns in data. The key idea is to use attention mechanisms to focus on the most relevant features in the data, and then use a technique called knowledge distillation to transfer the knowledge from a larger, more complex model to a smaller, more efficient model.
The attention mechanisms help the model identify the most important spatial and channel-wise features in the data, allowing it to better distinguish normal patterns from anomalies. The knowledge distillation process then takes the insights learned by the larger model and distills them into a smaller model, making the anomaly detection system more compact and efficient without sacrificing performance.
This approach is particularly useful in applications where anomaly detection needs to be done quickly and with limited computational resources, such as in real-time monitoring systems or on edge devices. By leveraging attention and knowledge distillation, the researchers were able to develop a more accurate and efficient anomaly detection system compared to previous methods.
Technical Explanation
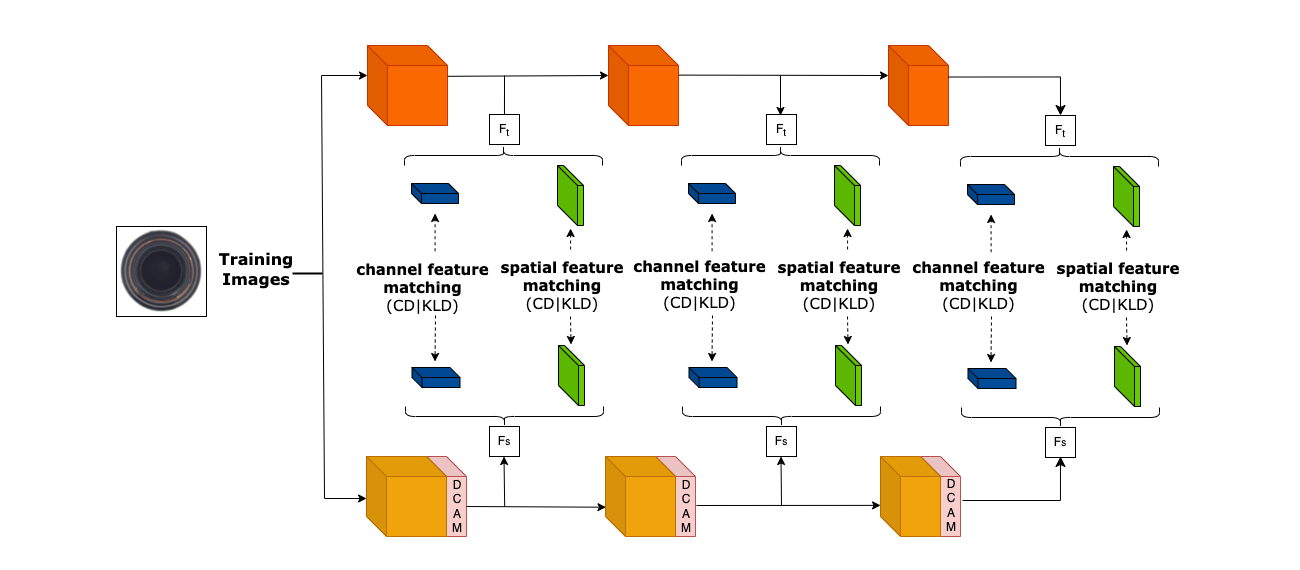
The paper proposes an "Attend, Distill, Detect" (ADD) framework for anomaly detection. The key components are:
-
Attention Mechanism: The framework uses both spatial attention and channel attention to identify the most relevant features for anomaly detection. The spatial attention module focuses on the most informative spatial regions, while the channel attention module identifies the most important channels or feature maps.
-
Knowledge Distillation: The framework uses a teacher-student knowledge distillation approach to transfer the learned representations from a larger, more complex model (the teacher) to a smaller, more efficient model (the student). This allows the student model to benefit from the teacher's knowledge without the computational overhead of the larger model.
-
Anomaly Detection: The student model is used for the final anomaly detection task. It leverages the attention-aware features learned during the distillation process to accurately identify anomalies in the data.
The researchers evaluated the ADD framework on multiple benchmark datasets for anomaly detection, and demonstrated that it outperforms previous state-of-the-art methods in terms of both accuracy and computational efficiency.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated framework for anomaly detection. The use of attention mechanisms to focus on the most relevant features is a particularly promising approach, as it can help the model better distinguish normal patterns from anomalies.
However, the paper does not address some potential limitations of the approach. For example, the effectiveness of the attention-aware distillation may be dependent on the similarity between the teacher and student models, as well as the quality and diversity of the training data. Additionally, the paper does not explore the robustness of the framework to different types of anomalies or its performance on real-world, large-scale datasets.
Further research could investigate the generalizability of the ADD framework, explore its applicability to other anomaly detection tasks (e.g., video anomaly detection, network intrusion detection), and examine its sensitivity to various hyperparameters and architectural choices.
Conclusion
The "Attend, Distill, Detect" framework presented in this paper offers a novel and effective approach to anomaly detection. By leveraging attention mechanisms to focus on the most relevant features and using knowledge distillation to transfer insights from a larger model to a smaller, more efficient one, the researchers have developed a system that is both accurate and computationally lightweight.
This work has important implications for a variety of applications, such as real-time monitoring systems, edge computing, and security. The ability to detect anomalies quickly and efficiently can help organizations and individuals identify and respond to potential issues before they escalate, ultimately enhancing safety, security, and overall system performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
Sushovan Jena, Vishwas Saini, Ujjwal Shaw, Pavitra Jain, Abhay Singh Raihal, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Arnav Bhavsar
Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the cross-class interference problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.
Read more5/13/2024

0
Distilling Aggregated Knowledge for Weakly-Supervised Video Anomaly Detection
Jash Dalvi, Ali Dabouei, Gunjan Dhanuka, Min Xu
Video anomaly detection aims to develop automated models capable of identifying abnormal events in surveillance videos. The benchmark setup for this task is extremely challenging due to: i) the limited size of the training sets, ii) weak supervision provided in terms of video-level labels, and iii) intrinsic class imbalance induced by the scarcity of abnormal events. In this work, we show that distilling knowledge from aggregated representations of multiple backbones into a relatively simple model achieves state-of-the-art performance. In particular, we develop a bi-level distillation approach along with a novel disentangled cross-attention-based feature aggregation network. Our proposed approach, DAKD (Distilling Aggregated Knowledge with Disentangled Attention), demonstrates superior performance compared to existing methods across multiple benchmark datasets. Notably, we achieve significant improvements of 1.36%, 0.78%, and 7.02% on the UCF-Crime, ShanghaiTech, and XD-Violence datasets, respectively.
Read more6/6/2024

0
Dual-Modeling Decouple Distillation for Unsupervised Anomaly Detection
Xinyue Liu, Jianyuan Wang, Biao Leng, Shuo Zhang
Knowledge distillation based on student-teacher network is one of the mainstream solution paradigms for the challenging unsupervised Anomaly Detection task, utilizing the difference in representation capabilities of the teacher and student networks to implement anomaly localization. However, over-generalization of the student network to the teacher network may lead to negligible differences in representation capabilities of anomaly, thus affecting the detection effectiveness. Existing methods address the possible over-generalization by using differentiated students and teachers from the structural perspective or explicitly expanding distilled information from the content perspective, which inevitably result in an increased likelihood of underfitting of the student network and poor anomaly detection capabilities in anomaly center or edge. In this paper, we propose Dual-Modeling Decouple Distillation (DMDD) for the unsupervised anomaly detection. In DMDD, a Decouple Student-Teacher Network is proposed to decouple the initial student features into normality and abnormality features. We further introduce Dual-Modeling Distillation based on normal-anomaly image pairs, fitting normality features of anomalous image and the teacher features of the corresponding normal image, widening the distance between abnormality features and the teacher features in anomalous regions. Synthesizing these two distillation ideas, we achieve anomaly detection which focuses on both edge and center of anomaly. Finally, a Multi-perception Segmentation Network is proposed to achieve focused anomaly map fusion based on multiple attention. Experimental results on MVTec AD show that DMDD surpasses SOTA localization performance of previous knowledge distillation-based methods, reaching 98.85% on pixel-level AUC and 96.13% on PRO.
Read more8/9/2024
✨
0
Attention-guided Feature Distillation for Semantic Segmentation
Amir M. Mansourian, Arya Jalali, Rozhan Ahmadi, Shohreh Kasaei
In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, this paper showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, employs the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. Simply using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student, AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of improving the mean Intersection over Union (mIoU) of the student network on the PascalVoc 2012, Cityscapes, COCO, and CamVid datasets.
Read more8/27/2024