Dual-Modeling Decouple Distillation for Unsupervised Anomaly Detection

0

Sign in to get full access
Overview
- Presents a novel unsupervised anomaly detection approach called Dual-Modeling Decouple Distillation (DM2D)
- Combines knowledge distillation with dual modeling to detect anomalies without labeled data
- Achieves strong anomaly detection performance on various datasets
Plain English Explanation
The paper introduces a new method called Dual-Modeling Decouple Distillation (DM2D) for unsupervised anomaly detection. Anomaly detection is the task of identifying unusual or abnormal data points in a dataset.
In DM2D, two separate models are trained - a "teacher" model and a "student" model. The teacher model learns the normal patterns in the data, while the student model is trained to mimic the teacher using a technique called knowledge distillation.
The key insight is that the student model will struggle to perfectly match the teacher's outputs on anomalous data points, allowing those anomalies to be detected. This dual modeling and distillation approach is effective for finding anomalies without any labeled training data, making it useful for real-world applications.
Technical Explanation
The paper proposes the Dual-Modeling Decouple Distillation (DM2D) framework for unsupervised anomaly detection. DM2D consists of two main components:
-
Dual Modeling: Two neural network models are trained - a "teacher" model and a "student" model. The teacher model is trained on the normal data samples to learn their underlying patterns. The student model is then trained to mimic the teacher's outputs using knowledge distillation.
-
Decouple Distillation: The student model is trained to match the teacher's outputs on normal data, but will struggle to do so on anomalous data. This difference in performance on normal versus anomalous data allows the anomalies to be detected.
The authors conduct extensive experiments on several anomaly detection benchmark datasets and show that DM2D outperforms previous state-of-the-art unsupervised methods. The key advantages of DM2D are its ability to detect anomalies without any labeled training data and its robust performance across diverse datasets.
Critical Analysis
The paper presents a well-designed and empirically validated unsupervised anomaly detection approach. The use of dual modeling and decouple distillation is a clever way to leverage the strengths of knowledge distillation for anomaly detection.
One potential limitation is that the performance of DM2D may depend on the specific architectures and hyperparameters of the teacher and student models. The authors do not provide a detailed exploration of how different model choices affect the results.
Additionally, the paper does not discuss the computational complexity or training time of DM2D compared to other unsupervised anomaly detection methods. These practical considerations could be relevant for real-world deployment.
Overall, the paper makes a compelling contribution to the field of anomaly detection and provides a promising new approach for identifying unusual patterns in data without relying on labeled training examples.
Conclusion
The Dual-Modeling Decouple Distillation (DM2D) framework introduced in this paper represents an innovative and effective solution for unsupervised anomaly detection. By combining dual modeling and knowledge distillation, DM2D can identify anomalies without requiring any labeled training data, making it a versatile tool for a wide range of applications.
The strong empirical results demonstrate the practical value of this approach, and the underlying principles could inspire further advancements in the field of anomaly detection. As AI systems become increasingly important in various industries, developing robust and generalizable anomaly detection methods will be crucial for ensuring the reliability and safety of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual-Modeling Decouple Distillation for Unsupervised Anomaly Detection
Xinyue Liu, Jianyuan Wang, Biao Leng, Shuo Zhang
Knowledge distillation based on student-teacher network is one of the mainstream solution paradigms for the challenging unsupervised Anomaly Detection task, utilizing the difference in representation capabilities of the teacher and student networks to implement anomaly localization. However, over-generalization of the student network to the teacher network may lead to negligible differences in representation capabilities of anomaly, thus affecting the detection effectiveness. Existing methods address the possible over-generalization by using differentiated students and teachers from the structural perspective or explicitly expanding distilled information from the content perspective, which inevitably result in an increased likelihood of underfitting of the student network and poor anomaly detection capabilities in anomaly center or edge. In this paper, we propose Dual-Modeling Decouple Distillation (DMDD) for the unsupervised anomaly detection. In DMDD, a Decouple Student-Teacher Network is proposed to decouple the initial student features into normality and abnormality features. We further introduce Dual-Modeling Distillation based on normal-anomaly image pairs, fitting normality features of anomalous image and the teacher features of the corresponding normal image, widening the distance between abnormality features and the teacher features in anomalous regions. Synthesizing these two distillation ideas, we achieve anomaly detection which focuses on both edge and center of anomaly. Finally, a Multi-perception Segmentation Network is proposed to achieve focused anomaly map fusion based on multiple attention. Experimental results on MVTec AD show that DMDD surpasses SOTA localization performance of previous knowledge distillation-based methods, reaching 98.85% on pixel-level AUC and 96.13% on PRO.
Read more8/9/2024

0
Advancing Pre-trained Teacher: Towards Robust Feature Discrepancy for Anomaly Detection
Canhui Tang, Sanping Zhou, Yizhe Li, Yonghao Dong, Le Wang
With the wide application of knowledge distillation between an ImageNet pre-trained teacher model and a learnable student model, industrial anomaly detection has witnessed a significant achievement in the past few years. The success of knowledge distillation mainly relies on how to keep the feature discrepancy between the teacher and student model, in which it assumes that: (1) the teacher model can jointly represent two different distributions for the normal and abnormal patterns, while (2) the student model can only reconstruct the normal distribution. However, it still remains a challenging issue to maintain these ideal assumptions in practice. In this paper, we propose a simple yet effective two-stage industrial anomaly detection framework, termed as AAND, which sequentially performs Anomaly Amplification and Normality Distillation to obtain robust feature discrepancy. In the first anomaly amplification stage, we propose a novel Residual Anomaly Amplification (RAA) module to advance the pre-trained teacher encoder. With the exposure of synthetic anomalies, it amplifies anomalies via residual generation while maintaining the integrity of pre-trained model. It mainly comprises a Matching-guided Residual Gate and an Attribute-scaling Residual Generator, which can determine the residuals' proportion and characteristic, respectively. In the second normality distillation stage, we further employ a reverse distillation paradigm to train a student decoder, in which a novel Hard Knowledge Distillation (HKD) loss is built to better facilitate the reconstruction of normal patterns. Comprehensive experiments on the MvTecAD, VisA, and MvTec3D-RGB datasets show that our method achieves state-of-the-art performance.
Read more5/6/2024
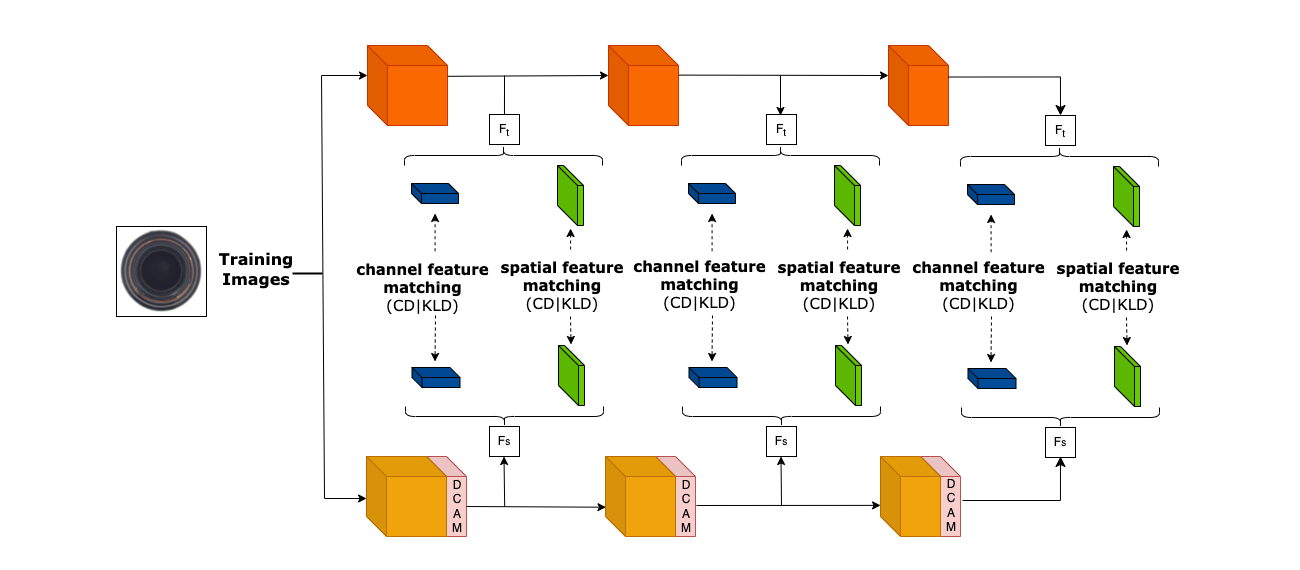
0
Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
Sushovan Jena, Vishwas Saini, Ujjwal Shaw, Pavitra Jain, Abhay Singh Raihal, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Arnav Bhavsar
Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the cross-class interference problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.
Read more5/13/2024

0
DFMSD: Dual Feature Masking Stage-wise Knowledge Distillation for Object Detection
Zhourui Zhang, Jun Li, Zhijian Wu, Jifeng Shen, Jianhua Xu
In recent years, current mainstream feature masking distillation methods mainly function by reconstructing selectively masked regions of a student network from the feature maps of a teacher network. In these methods, attention mechanisms can help to identify spatially important regions and crucial object-aware channel clues, such that the reconstructed features are encoded with sufficient discriminative and representational power similar to teacher features. However, previous feature-masking distillation methods mainly address homogeneous knowledge distillation without fully taking into account the heterogeneous knowledge distillation scenario. In particular, the huge discrepancy between the teacher and the student frameworks within the heterogeneous distillation paradigm is detrimental to feature masking, leading to deteriorating reconstructed student features. In this study, a novel dual feature-masking heterogeneous distillation framework termed DFMSD is proposed for object detection. More specifically, a stage-wise adaptation learning module is incorporated into the dual feature-masking framework, and thus the student model can be progressively adapted to the teacher models for bridging the gap between heterogeneous networks. Furthermore, a masking enhancement strategy is combined with stage-wise learning such that object-aware masking regions are adaptively strengthened to improve feature-masking reconstruction. In addition, semantic alignment is performed at each Feature Pyramid Network (FPN) layer between the teacher and the student networks for generating consistent feature distributions. Our experiments for the object detection task demonstrate the promise of our approach, suggesting that DFMSD outperforms both the state-of-the-art heterogeneous and homogeneous distillation methods.
Read more7/19/2024