Attention-guided Feature Distillation for Semantic Segmentation

0
✨
Sign in to get full access
Overview
- Proposes a simple yet powerful method called Attention-guided Feature Distillation (AttnFD) for transferring attention from a teacher model to a student model
- AttnFD uses the Convolutional Block Attention Module (CBAM) to refine feature maps, capturing both channel-specific and spatial information
- Demonstrates state-of-the-art performance in semantic segmentation tasks on popular datasets like PascalVoc 2012, Cityscapes, COCO, and CamVid
Plain English Explanation
When training a machine learning model, it's often helpful to have a more capable "teacher" model that can share its knowledge with a less capable "student" model. This process is called knowledge distillation. However, existing methods for knowledge distillation can be quite complex and difficult to implement.
The paper introduces a simple yet powerful technique called Attention-guided Feature Distillation (AttnFD) that uses a special module called Convolutional Block Attention Module (CBAM) to transfer attention information from the teacher model to the student model. This attention information helps the student model focus on the most important parts of the input, leading to improved performance on dense prediction tasks like semantic segmentation.
The key insight is that by using a simple mean squared error (MSE) loss function to match the refined feature maps between the teacher and student models, the student can learn to mimic the teacher's attention patterns without needing complicated distillation methods. The results show that this simple approach outperforms more complex knowledge distillation techniques on several popular computer vision datasets.
Technical Explanation
The proposed Attention-guided Feature Distillation (AttnFD) method uses the Convolutional Block Attention Module (CBAM) to refine the feature maps of both the teacher and student models. CBAM takes into account both channel-specific and spatial information to highlight the most important features.
The core of the AttnFD method is to use a simple mean squared error (MSE) loss function to match the refined feature maps of the teacher and student models. This encourages the student model to learn the attention patterns of the more capable teacher model, leading to improved performance on dense prediction tasks like semantic segmentation.
The paper evaluates the AttnFD method on several popular computer vision datasets, including PascalVoc 2012, Cityscapes, COCO, and CamVid. The results show that this simple approach outperforms more complex knowledge distillation techniques, achieving state-of-the-art performance in terms of the mean Intersection over Union (mIoU) metric for the student network.
Critical Analysis
The paper provides a compelling solution to the challenge of knowledge distillation, offering a simple yet effective method for transferring attention information from a teacher model to a student model. The use of the Convolutional Block Attention Module (CBAM) is a clever way to capture both channel-specific and spatial information, which is crucial for dense prediction tasks like semantic segmentation.
One potential limitation of the approach is that it may not be as effective for tasks that don't rely heavily on attention mechanisms, as the method is specifically designed to transfer attention information. Additionally, the paper does not explore the impact of different architectural choices or hyperparameter settings on the performance of the AttnFD method.
Further research could investigate the applicability of the AttnFD method to other dense prediction tasks, as well as explore ways to combine it with other knowledge distillation techniques to achieve even greater performance gains. It would also be interesting to see how the method compares to state-of-the-art attention-based architectures that don't rely on knowledge distillation.
Conclusion
The proposed Attention-guided Feature Distillation (AttnFD) method offers a simple yet powerful approach to knowledge distillation, using the Convolutional Block Attention Module (CBAM) to transfer attention information from a teacher model to a student model. The results demonstrate that this simple technique can outperform more complex distillation methods on challenging semantic segmentation tasks, making it a promising tool for improving the performance of student models in a wide range of computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Attention-guided Feature Distillation for Semantic Segmentation
Amir M. Mansourian, Arya Jalali, Rozhan Ahmadi, Shohreh Kasaei
In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, this paper showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, employs the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. Simply using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student, AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of improving the mean Intersection over Union (mIoU) of the student network on the PascalVoc 2012, Cityscapes, COCO, and CamVid datasets.
Read more8/27/2024
0
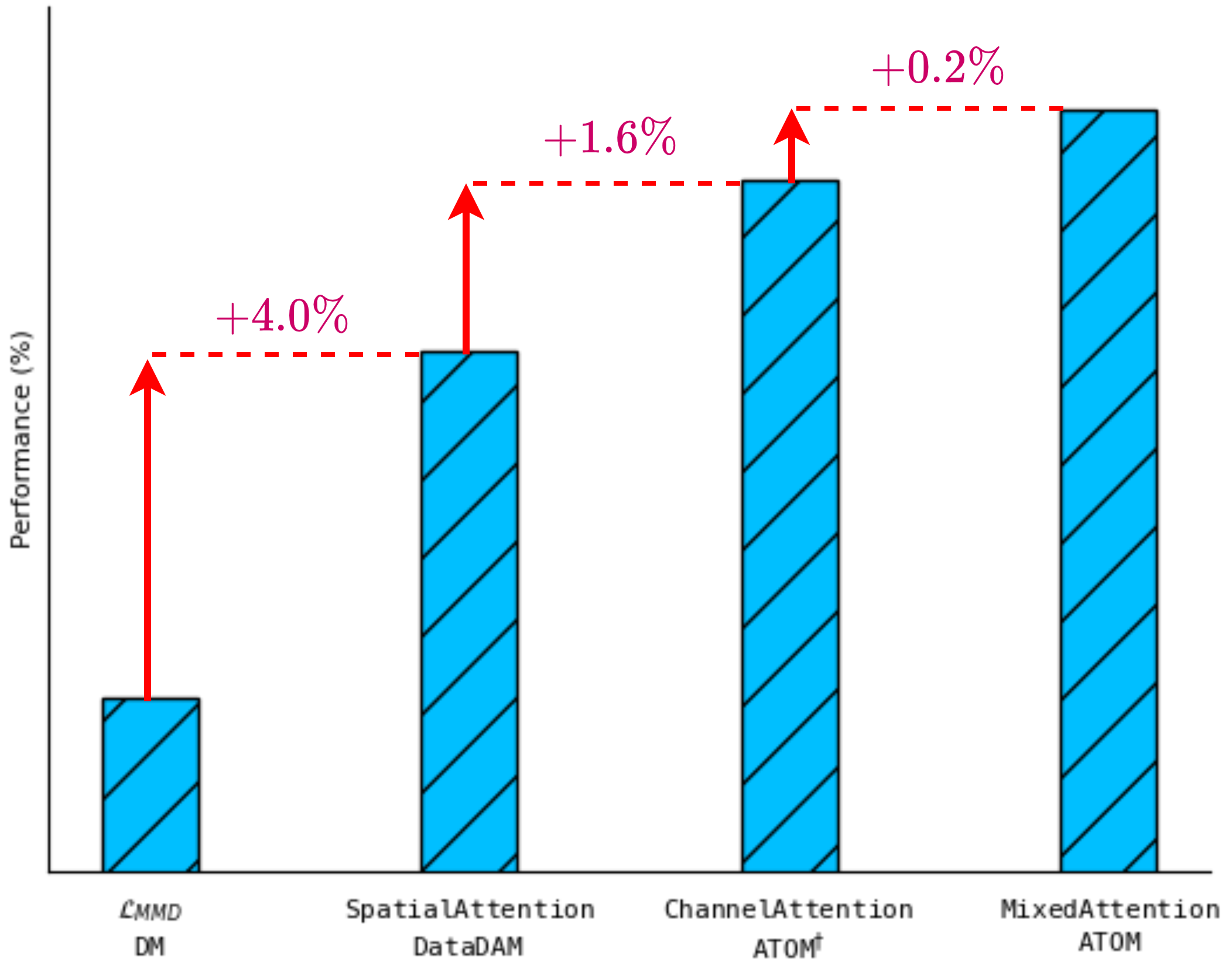
ATOM: Attention Mixer for Efficient Dataset Distillation
Samir Khaki, Ahmad Sajedi, Kai Wang, Lucy Z. Liu, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.
Read more5/3/2024
0
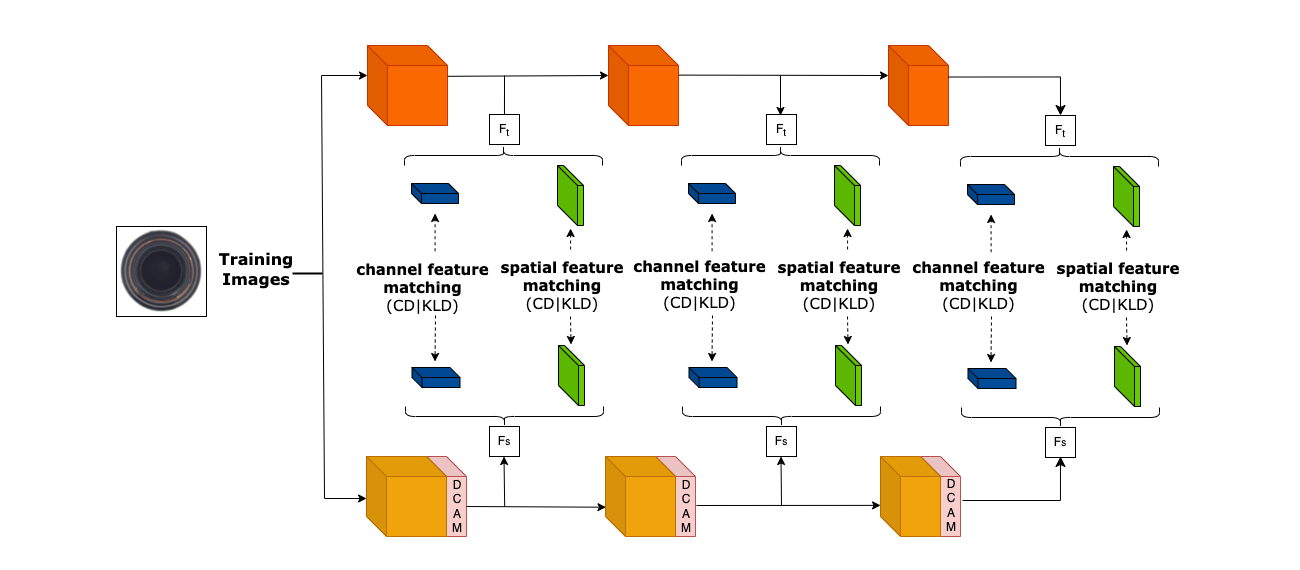
Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
Sushovan Jena, Vishwas Saini, Ujjwal Shaw, Pavitra Jain, Abhay Singh Raihal, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Arnav Bhavsar
Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the cross-class interference problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.
Read more5/13/2024
0
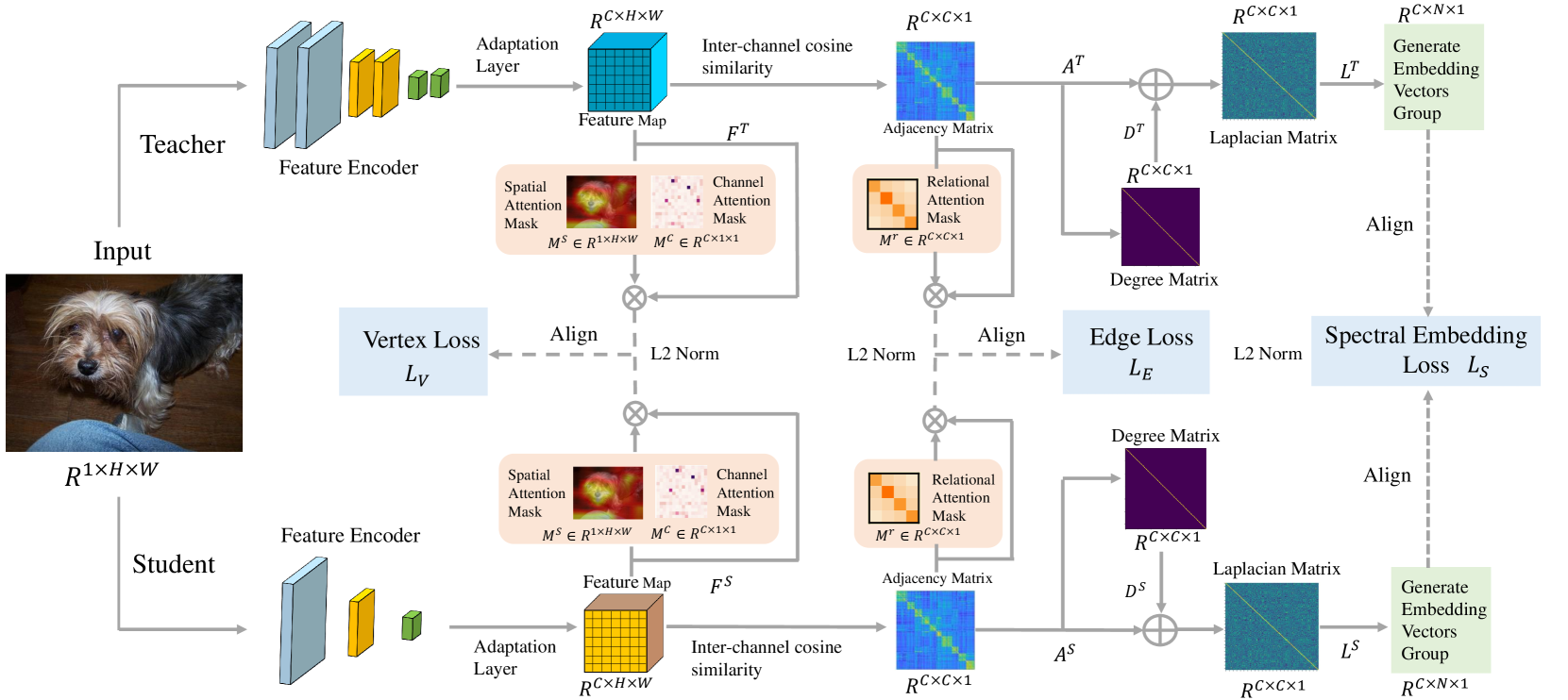
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
Read more5/17/2024