Attention-aware Post-training Quantization without Backpropagation

0

Sign in to get full access
Overview
- This paper introduces a novel post-training quantization method called Attention-aware Post-training Quantization (APTQ) that does not require backpropagation.
- APTQ leverages the attention mechanism in deep learning models to identify important weights and quantize them more precisely, while coarsely quantizing less important weights.
- The authors demonstrate the effectiveness of APTQ on various computer vision and natural language processing tasks, showing significant improvements in model performance compared to existing post-training quantization methods.
Plain English Explanation
Attention-aware Post-training Quantization without Backpropagation presents a new way to make deep learning models smaller and more efficient without sacrificing too much accuracy. Deep learning models can be very large and complex, which makes them difficult to deploy on devices with limited resources, like smartphones or edge devices.
One way to make these models smaller is through a process called quantization, which involves reducing the precision of the numbers used to represent the model's parameters. This can dramatically reduce the model's size, but it can also hurt its performance. The authors of this paper have come up with a clever solution that uses the model's attention mechanism to determine which parts of the model are more important and should be quantized more precisely, while less important parts can be quantized more coarsely.
The key insight is that the attention mechanism, which is a core component of many state-of-the-art deep learning models, can provide valuable information about the relative importance of different parts of the model. By leveraging this information, the authors' method, APTQ, is able to achieve better performance compared to other post-training quantization methods that don't take attention into account.
Technical Explanation
Attention-aware Post-training Quantization without Backpropagation presents a novel post-training quantization (PTQ) method that leverages the attention mechanism in deep learning models to achieve more effective quantization without the need for backpropagation.
The key idea behind APTQ is to use the attention scores generated by the model to guide the quantization process. Attention scores indicate the relative importance of different parts of the input for a given prediction, and the authors hypothesize that weights associated with more important parts of the model (i.e., those with higher attention scores) should be quantized more precisely to preserve model performance.
To implement APTQ, the authors first extract the attention scores for each weight in the model. They then use these scores to partition the weights into high-attention and low-attention groups, and apply different quantization schemes to each group. The high-attention weights are quantized using a finer precision, while the low-attention weights are quantized more coarsely.
The authors evaluate APTQ on a variety of computer vision and natural language processing tasks, including image classification, object detection, and language modeling. They show that APTQ consistently outperforms existing PTQ methods, often by a significant margin, without requiring any fine-tuning or retraining of the original model.
One key advantage of APTQ is that it does not require any backpropagation or iterative optimization, unlike many other quantization techniques. This makes it more efficient and easier to apply in practical settings, where the ability to quickly quantize a pre-trained model is important.
Critical Analysis
The Attention-aware Post-training Quantization without Backpropagation paper presents a compelling approach to post-training quantization that leverages the attention mechanism in deep learning models. The authors demonstrate the effectiveness of their APTQ method across a range of tasks, which is a notable strength of the work.
However, one potential limitation of the approach is that it assumes the attention mechanism in the original model is well-calibrated and provides accurate information about the relative importance of different weights. In practice, attention mechanisms can sometimes be biased or unreliable, which could negatively impact the quantization process.
Additionally, the paper does not provide a deep analysis of the underlying reasons why the attention-aware quantization strategy is effective. While the authors offer some intuitive explanations, a more thorough investigation of the theoretical foundations could strengthen the work and provide additional insights.
It would also be interesting to see how APTQ performs on more complex, state-of-the-art models, such as large language models (Low-Rank Quantization-Aware Training for Large Language Models) or vision transformers. Applying the technique to a wider range of architectures could further demonstrate its generalizability and potential impact.
Overall, the Attention-aware Post-training Quantization without Backpropagation paper presents a novel and promising approach to post-training quantization that warrants further investigation and refinement.
Conclusion
Attention-aware Post-training Quantization without Backpropagation introduces a novel post-training quantization method that leverages the attention mechanism in deep learning models to achieve more effective quantization without the need for backpropagation. The authors demonstrate the effectiveness of their APTQ approach on a range of computer vision and natural language processing tasks, showing significant improvements over existing post-training quantization techniques.
The key innovation of APTQ is its ability to use attention scores to identify important weights and quantize them more precisely, while coarsely quantizing less important weights. This attention-aware quantization strategy allows APTQ to achieve better model performance compared to other post-training quantization methods that do not take attention information into account.
The Attention-aware Post-training Quantization without Backpropagation paper represents an important contribution to the field of model compression and deployment, as it provides a practical and efficient way to reduce the size and computational requirements of deep learning models without sacrificing too much accuracy. This could have significant implications for the deployment of AI systems on resource-constrained devices, such as smartphones or edge devices, and help make AI more accessible and ubiquitous in our everyday lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attention-aware Post-training Quantization without Backpropagation
Junhan Kim, Ho-young Kim, Eulrang Cho, Chungman Lee, Joonyoung Kim, Yongkweon Jeon
Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Read more6/21/2024
0
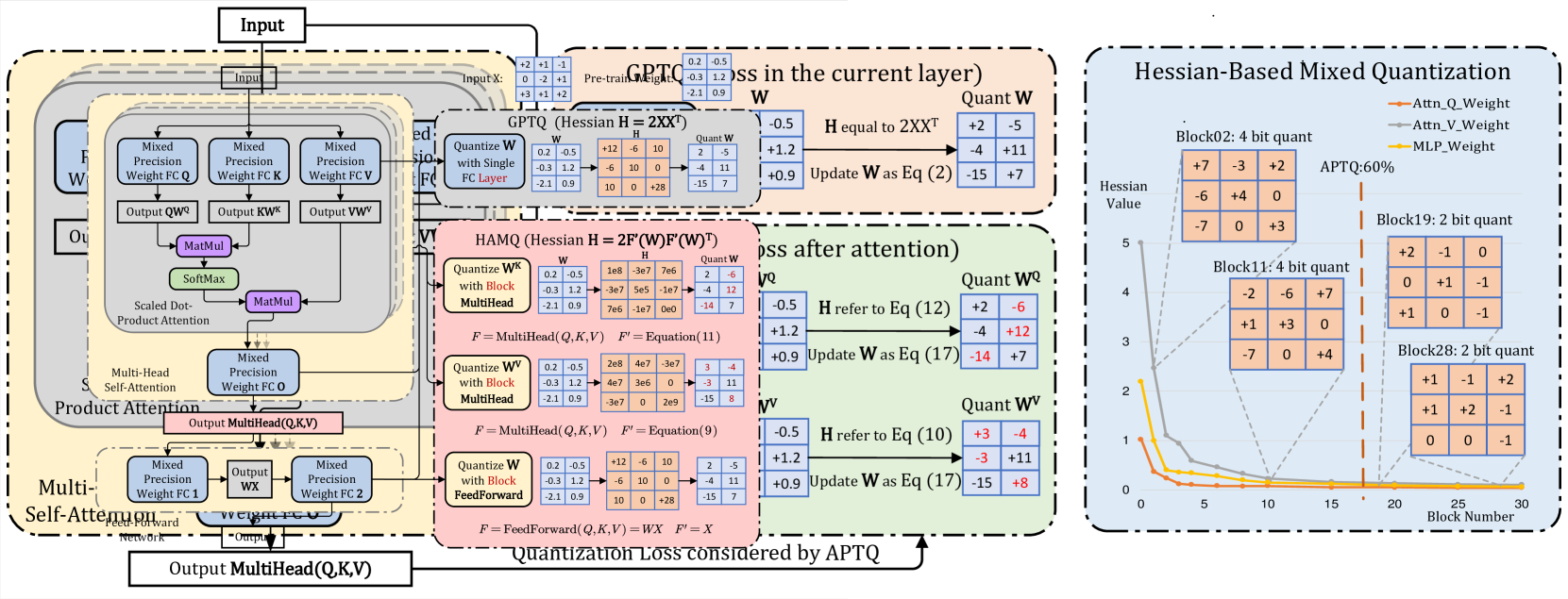
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
Read more4/17/2024

0
New!EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization
Ofir Gordon, Elad Cohen, Hai Victor Habi, Arnon Netzer
Quantization is a key method for deploying deep neural networks on edge devices with limited memory and computation resources. Recent improvements in Post-Training Quantization (PTQ) methods were achieved by an additional local optimization process for learning the weight quantization rounding policy. However, a gap exists when employing network-wise optimization with small representative datasets. In this paper, we propose a new method for enhanced PTQ (EPTQ) that employs a network-wise quantization optimization process, which benefits from considering cross-layer dependencies during optimization. EPTQ enables network-wise optimization with a small representative dataset using a novel sample-layer attention score based on a label-free Hessian matrix upper bound. The label-free approach makes our method suitable for the PTQ scheme. We give a theoretical analysis for the said bound and use it to construct a knowledge distillation loss that guides the optimization to focus on the more sensitive layers and samples. In addition, we leverage the Hessian upper bound to improve the weight quantization parameters selection by focusing on the more sensitive elements in the weight tensors. Empirically, by employing EPTQ we achieve state-of-the-art results on various models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation.
Read more9/27/2024

0
Low-Rank Quantization-Aware Training for LLMs
Yelysei Bondarenko, Riccardo Del Chiaro, Markus Nagel
Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to LLaMA-1/2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory. Our source code is available at https://github.com/qualcomm-ai-research/LR-QAT
Read more9/4/2024