EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization

0

Sign in to get full access
Overview
- Enhanced Post-Training Quantization (EPTQ) is a method for efficiently compressing deep neural networks without significantly impacting their performance.
- It leverages the Hessian matrix, which captures information about the curvature of the loss function, to guide the quantization process in a label-free manner.
- EPTQ can achieve competitive or better accuracy compared to existing post-training quantization techniques, while being computationally efficient.
Plain English Explanation
EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian describes a method for making deep neural networks smaller and faster, without sacrificing too much of their performance.
The key idea is to use information about the "curvature" of the neural network's loss function, which is captured in the Hessian matrix. This Hessian-based approach allows the method to figure out the best way to quantize (compress) the network's weights and activations, without needing any labeled data.
Compared to other post-training quantization techniques, EPTQ can achieve similar or even better accuracy, while being computationally efficient. This makes it a promising approach for deploying high-performance deep learning models on resource-constrained devices, like smartphones or embedded systems.
Technical Explanation
EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian presents a new method for efficiently compressing deep neural networks through post-training quantization.
The key innovation is the use of the Hessian matrix, which captures information about the curvature of the network's loss function. By analyzing the Hessian, the method can identify the most important weights and activations that should be preserved during quantization, without requiring any labeled data.
The EPTQ algorithm consists of three main steps:
- Hessian Computation: The Hessian matrix is computed for the pre-trained neural network using a label-free approach, which avoids the need for costly backpropagation.
- Quantization Parameter Optimization: The quantization parameters (e.g., bit-widths) are optimized by minimizing a loss function that incorporates the Hessian information, ensuring that the most important aspects of the network are preserved.
- Network Quantization: The network weights and activations are quantized using the optimized parameters, resulting in a compressed model.
Experiments on various computer vision and natural language processing tasks show that EPTQ can achieve competitive or better accuracy compared to existing post-training quantization methods, while being computationally efficient. This makes it a promising approach for deploying high-performance deep learning models on resource-constrained devices.
Critical Analysis
The EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian paper presents a novel and effective method for post-training quantization of deep neural networks. However, there are a few potential limitations and areas for further research:
-
Hessian Computation Complexity: The computation of the Hessian matrix can be computationally expensive, especially for large-scale neural networks. The authors address this by using a label-free approximation, but further improvements in efficiency may be needed for real-world deployment.
-
Generalization to Diverse Architectures: While the authors demonstrate the effectiveness of EPTQ on several common neural network architectures, it would be valuable to evaluate its performance on a wider range of model types, including more recent and specialized architectures.
-
Hardware-Aware Optimization: The current approach optimizes the quantization parameters solely based on the Hessian information. Incorporating hardware-specific constraints and characteristics (e.g., memory access patterns, computation costs) into the optimization process could lead to even more efficient compressed models.
-
Exploration of Adaptive Quantization: The paper focuses on static, uniform quantization. Exploring adaptive or non-uniform quantization schemes that can further exploit the Hessian information could potentially yield even better results.
Despite these potential areas for improvement, the EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian paper presents a significant advance in the field of post-training quantization, demonstrating the value of leveraging Hessian-based information to guide the compression process effectively.
Conclusion
EPTQ: Enhanced Post-Training Quantization via Label-Free Hessian introduces a novel post-training quantization method that utilizes the Hessian matrix to guide the compression of deep neural networks in a label-free manner.
The key advantages of EPTQ are its ability to achieve competitive or better accuracy compared to existing techniques, while being computationally efficient. This makes it a promising approach for deploying high-performance deep learning models on resource-constrained devices, such as smartphones or embedded systems.
While the paper highlights several exciting results, there are also opportunities for further research and improvements, such as addressing the computational complexity of Hessian computation, exploring more diverse neural network architectures, and incorporating hardware-aware optimization strategies.
Overall, the EPTQ method represents an important step forward in the field of efficient deep learning, and its label-free Hessian-based approach could inspire future advancements in post-training quantization and model compression techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!EPTQ: Enhanced Post-Training Quantization via Hessian-guided Network-wise Optimization
Ofir Gordon, Elad Cohen, Hai Victor Habi, Arnon Netzer
Quantization is a key method for deploying deep neural networks on edge devices with limited memory and computation resources. Recent improvements in Post-Training Quantization (PTQ) methods were achieved by an additional local optimization process for learning the weight quantization rounding policy. However, a gap exists when employing network-wise optimization with small representative datasets. In this paper, we propose a new method for enhanced PTQ (EPTQ) that employs a network-wise quantization optimization process, which benefits from considering cross-layer dependencies during optimization. EPTQ enables network-wise optimization with a small representative dataset using a novel sample-layer attention score based on a label-free Hessian matrix upper bound. The label-free approach makes our method suitable for the PTQ scheme. We give a theoretical analysis for the said bound and use it to construct a knowledge distillation loss that guides the optimization to focus on the more sensitive layers and samples. In addition, we leverage the Hessian upper bound to improve the weight quantization parameters selection by focusing on the more sensitive elements in the weight tensors. Empirically, by employing EPTQ we achieve state-of-the-art results on various models, tasks, and datasets, including ImageNet classification, COCO object detection, and Pascal-VOC for semantic segmentation.
Read more9/27/2024

0
Attention-aware Post-training Quantization without Backpropagation
Junhan Kim, Ho-young Kim, Eulrang Cho, Chungman Lee, Joonyoung Kim, Yongkweon Jeon
Quantization is a promising solution for deploying large-scale language models (LLMs) on resource-constrained devices. Existing quantization approaches, however, rely on gradient-based optimization, regardless of it being post-training quantization (PTQ) or quantization-aware training (QAT), which becomes problematic for hyper-scale LLMs with billions of parameters. This overhead can be alleviated via recently proposed backpropagation-free PTQ methods; however, their performance is somewhat limited by their lack of consideration of inter-layer dependencies. In this paper, we thus propose a novel PTQ algorithm that considers inter-layer dependencies without relying on backpropagation. The fundamental concept involved is the development of attention-aware Hessian matrices, which facilitates the consideration of inter-layer dependencies within the attention module. Extensive experiments demonstrate that the proposed algorithm significantly outperforms conventional PTQ methods, particularly for low bit-widths.
Read more6/21/2024

0
MetaAug: Meta-Data Augmentation for Post-Training Quantization
Cuong Pham, Hoang Anh Dung, Cuong C. Nguyen, Trung Le, Dinh Phung, Gustavo Carneiro, Thanh-Toan Do
Post-Training Quantization (PTQ) has received significant attention because it requires only a small set of calibration data to quantize a full-precision model, which is more practical in real-world applications in which full access to a large training set is not available. However, it often leads to overfitting on the small calibration dataset. Several methods have been proposed to address this issue, yet they still rely on only the calibration set for the quantization and they do not validate the quantized model due to the lack of a validation set. In this work, we propose a novel meta-learning based approach to enhance the performance of post-training quantization. Specifically, to mitigate the overfitting problem, instead of only training the quantized model using the original calibration set without any validation during the learning process as in previous PTQ works, in our approach, we both train and validate the quantized model using two different sets of images. In particular, we propose a meta-learning based approach to jointly optimize a transformation network and a quantized model through bi-level optimization. The transformation network modifies the original calibration data and the modified data will be used as the training set to learn the quantized model with the objective that the quantized model achieves a good performance on the original calibration data. Extensive experiments on the widely used ImageNet dataset with different neural network architectures demonstrate that our approach outperforms the state-of-the-art PTQ methods.
Read more7/30/2024
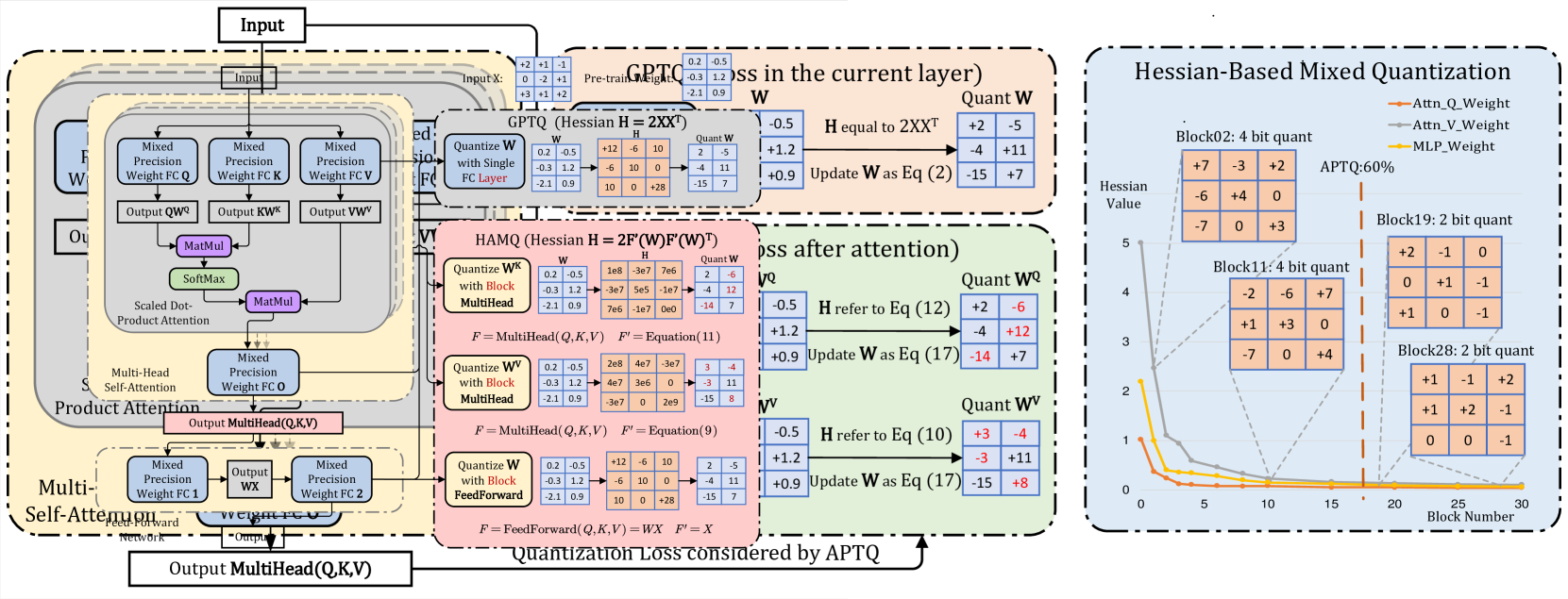
0
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
Read more4/17/2024