Vision Transformers for End-to-End Vision-Based Quadrotor Obstacle Avoidance
2405.10391
0
0

Abstract
We demonstrate the capabilities of an attention-based end-to-end approach for high-speed quadrotor obstacle avoidance in dense, cluttered environments, with comparison to various state-of-the-art architectures. Quadrotor unmanned aerial vehicles (UAVs) have tremendous maneuverability when flown fast; however, as flight speed increases, traditional vision-based navigation via independent mapping, planning, and control modules breaks down due to increased sensor noise, compounding errors, and increased processing latency. Thus, learning-based, end-to-end planning and control networks have shown to be effective for online control of these fast robots through cluttered environments. We train and compare convolutional, U-Net, and recurrent architectures against vision transformer models for depth-based end-to-end control, in a photorealistic, high-physics-fidelity simulator as well as in hardware, and observe that the attention-based models are more effective as quadrotor speeds increase, while recurrent models with many layers provide smoother commands at lower speeds. To the best of our knowledge, this is the first work to utilize vision transformers for end-to-end vision-based quadrotor control.
Create account to get full access
Overview
- This paper presents a Vision Transformer (ViT) model for end-to-end vision-based quadrotor obstacle avoidance.
- The proposed approach aims to enable quadrotors to navigate through cluttered environments using only onboard camera inputs, without the need for additional sensors or external infrastructure.
- The authors demonstrate the effectiveness of their ViT-based solution on challenging obstacle avoidance tasks and compare its performance to other deep learning architectures.
Plain English Explanation
The researchers have developed a new way for quadrotor drones to avoid obstacles using only the information from their onboard cameras, without needing any additional sensors or external systems. Traditionally, drones have relied on a combination of cameras, sensors, and complex control algorithms to navigate safely through cluttered environments. However, this can be expensive and require specialized hardware.
The key innovation in this paper is the use of a Vision Transformer (ViT) model, which is a type of deep learning architecture that is particularly well-suited for processing visual information. The ViT model is trained end-to-end, meaning it takes in raw camera images and directly outputs the control signals the drone needs to avoid obstacles, without any intermediate steps.
This approach has several advantages over traditional drone navigation systems. By using only the onboard camera, it eliminates the need for additional sensors, which can simplify the drone's hardware and reduce its overall cost. The ViT model is also highly efficient, allowing the drone to make rapid decisions and react quickly to changes in its environment.
The researchers have tested their ViT-based solution on challenging obstacle avoidance tasks and found that it outperforms other deep learning architectures, such as C2FDrone and collision avoidance algorithms. This suggests that their approach could be a promising solution for enabling safe and reliable drone navigation in a wide range of real-world applications, from traffic monitoring to search and rescue operations.
Technical Explanation
The researchers propose a Vision Transformer (ViT) model for end-to-end vision-based quadrotor obstacle avoidance. The ViT architecture is a type of deep learning model that has been shown to be highly effective for processing visual information, particularly in tasks like image classification and object detection.
In this work, the authors adapt the ViT model for the specific task of drone navigation, training it to take in raw camera images from the quadrotor and directly output the control signals needed to avoid obstacles. This end-to-end approach eliminates the need for additional sensors or complex control algorithms, simplifying the drone's hardware and control system.
To train and evaluate their ViT-based solution, the researchers leveraged a dataset of simulated drone flights in cluttered environments. They compared the performance of their ViT model to other deep learning architectures, such as C2FDrone and collision avoidance algorithms, and found that the ViT model outperformed these baselines on a variety of metrics, including success rate, distance traveled, and energy efficiency.
The authors attribute the strong performance of their ViT-based approach to the model's ability to effectively capture and process the visual information from the drone's camera, allowing it to make rapid and accurate decisions about how to navigate through the environment. They also note that the ViT model is highly efficient, enabling it to run in real-time on the drone's onboard hardware.
Critical Analysis
The research presented in this paper is a promising step towards enabling safe and reliable drone navigation using only onboard camera inputs. The authors have demonstrated the effectiveness of their ViT-based approach on challenging obstacle avoidance tasks, and their results suggest that this technique could be a valuable tool for a wide range of drone applications.
However, it's important to note that the experiments were conducted in a simulated environment, and further testing will be needed to evaluate the performance of the ViT model in real-world conditions. Additionally, the authors do not address potential issues such as the model's robustness to variations in lighting, weather, or camera quality, which could impact its practical deployment.
Another area for further research could be the integration of the ViT-based obstacle avoidance system with other drone capabilities, such as traffic monitoring or multi-drone coordination. Combining the ViT's vision-based navigation with other AI-powered functionalities could unlock new applications and further enhance the utility of drone technology.
Conclusion
This paper presents a novel approach to enabling end-to-end vision-based quadrotor obstacle avoidance using a Vision Transformer (ViT) model. The researchers have demonstrated the effectiveness of their ViT-based solution on challenging simulated tasks, showing that it outperforms other deep learning architectures in terms of success rate, distance traveled, and energy efficiency.
The key advantages of the ViT-based approach are its simplicity, efficiency, and reliance on only onboard camera inputs, which can simplify the drone's hardware and control system. This could make drone technology more accessible and cost-effective, potentially enabling a wider range of applications, from traffic monitoring to search and rescue operations.
While further testing in real-world conditions will be necessary, this research represents an important step forward in the development of safe and reliable drone navigation systems, with the potential to significantly advance the field of autonomous aerial vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
An Attention-Based Deep Learning Architecture for Real-Time Monocular Visual Odometry: Applications to GPS-free Drone Navigation
Olivier Brochu Dufour, Abolfazl Mohebbi, Sofiane Achiche
0
0
Drones are increasingly used in fields like industry, medicine, research, disaster relief, defense, and security. Technical challenges, such as navigation in GPS-denied environments, hinder further adoption. Research in visual odometry is advancing, potentially solving GPS-free navigation issues. Traditional visual odometry methods use geometry-based pipelines which, while popular, often suffer from error accumulation and high computational demands. Recent studies utilizing deep neural networks (DNNs) have shown improved performance, addressing these drawbacks. Deep visual odometry typically employs convolutional neural networks (CNNs) and sequence modeling networks like recurrent neural networks (RNNs) to interpret scenes and deduce visual odometry from video sequences. This paper presents a novel real-time monocular visual odometry model for drones, using a deep neural architecture with a self-attention module. It estimates the ego-motion of a camera on a drone, using consecutive video frames. An inference utility processes the live video feed, employing deep learning to estimate the drone's trajectory. The architecture combines a CNN for image feature extraction and a long short-term memory (LSTM) network with a multi-head attention module for video sequence modeling. Tested on two visual odometry datasets, this model converged 48% faster than a previous RNN model and showed a 22% reduction in mean translational drift and a 12% improvement in mean translational absolute trajectory error, demonstrating enhanced robustness to noise.
4/30/2024
🔎
C2FDrone: Coarse-to-Fine Drone-to-Drone Detection using Vision Transformer Networks
Sairam VC Rebbapragada, Pranoy Panda, Vineeth N Balasubramanian
0
0
A vision-based drone-to-drone detection system is crucial for various applications like collision avoidance, countering hostile drones, and search-and-rescue operations. However, detecting drones presents unique challenges, including small object sizes, distortion, occlusion, and real-time processing requirements. Current methods integrating multi-scale feature fusion and temporal information have limitations in handling extreme blur and minuscule objects. To address this, we propose a novel coarse-to-fine detection strategy based on vision transformers. We evaluate our approach on three challenging drone-to-drone detection datasets, achieving F1 score enhancements of 7%, 3%, and 1% on the FL-Drones, AOT, and NPS-Drones datasets, respectively. Additionally, we demonstrate real-time processing capabilities by deploying our model on an edge-computing device. Our code will be made publicly available.
5/1/2024

Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Zhehui Huang, Zhaojing Yang, Rahul Krupani, Bask{i}n c{S}enbac{s}lar, Sumeet Batra, Gaurav S. Sukhatme
0
0
End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
5/7/2024
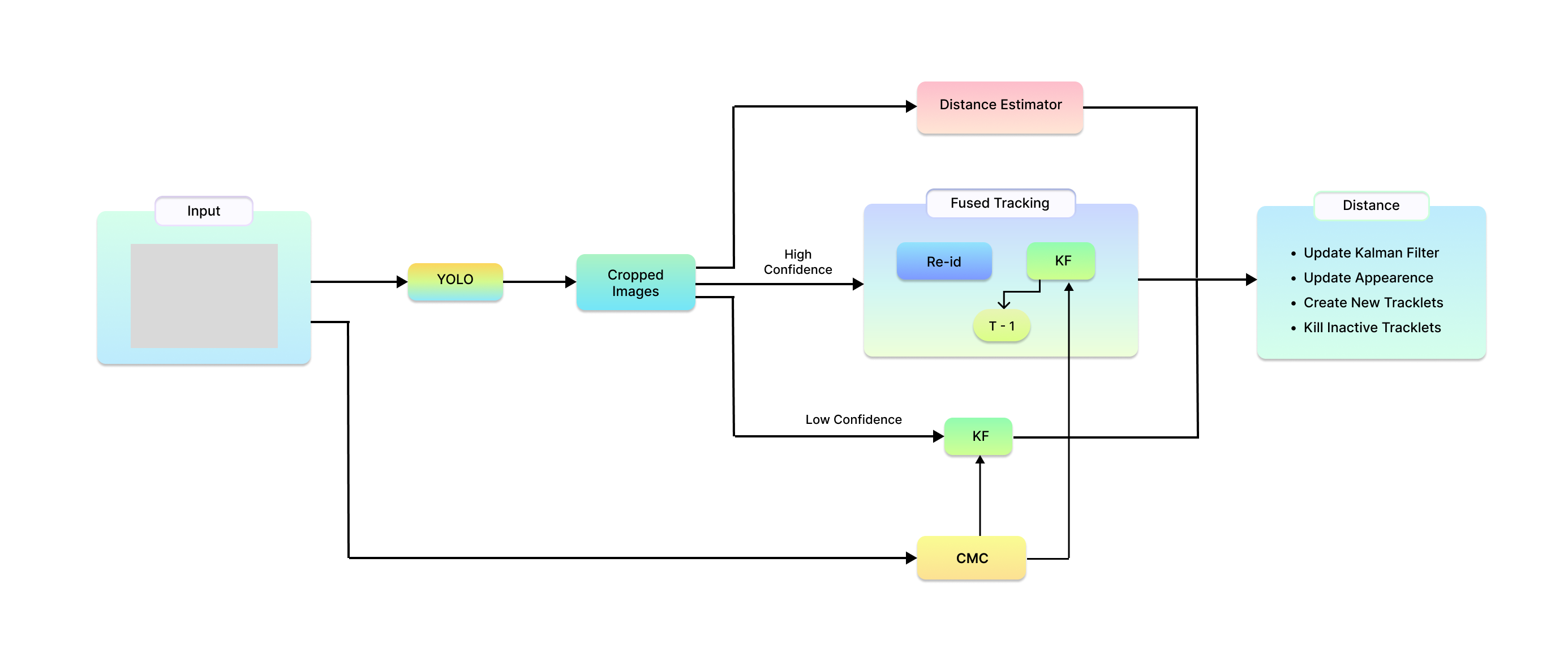
Ensuring UAV Safety: A Vision-only and Real-time Framework for Collision Avoidance Through Object Detection, Tracking, and Distance Estimation
Vasileios Karampinis, Anastasios Arsenos, Orfeas Filippopoulos, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
0
0
In the last twenty years, unmanned aerial vehicles (UAVs) have garnered growing interest due to their expanding applications in both military and civilian domains. Detecting non-cooperative aerial vehicles with efficiency and estimating collisions accurately are pivotal for achieving fully autonomous aircraft and facilitating Advanced Air Mobility (AAM). This paper presents a deep-learning framework that utilizes optical sensors for the detection, tracking, and distance estimation of non-cooperative aerial vehicles. In implementing this comprehensive sensing framework, the availability of depth information is essential for enabling autonomous aerial vehicles to perceive and navigate around obstacles. In this work, we propose a method for estimating the distance information of a detected aerial object in real time using only the input of a monocular camera. In order to train our deep learning components for the object detection, tracking and depth estimation tasks we utilize the Amazon Airborne Object Tracking (AOT) Dataset. In contrast to previous approaches that integrate the depth estimation module into the object detector, our method formulates the problem as image-to-image translation. We employ a separate lightweight encoder-decoder network for efficient and robust depth estimation. In a nutshell, the object detection module identifies and localizes obstacles, conveying this information to both the tracking module for monitoring obstacle movement and the depth estimation module for calculating distances. Our approach is evaluated on the Airborne Object Tracking (AOT) dataset which is the largest (to the best of our knowledge) air-to-air airborne object dataset.
5/17/2024