Salient Sparse Visual Odometry With Pose-Only Supervision
2404.04677
0
0

Abstract
Visual Odometry (VO) is vital for the navigation of autonomous systems, providing accurate position and orientation estimates at reasonable costs. While traditional VO methods excel in some conditions, they struggle with challenges like variable lighting and motion blur. Deep learning-based VO, though more adaptable, can face generalization problems in new environments. Addressing these drawbacks, this paper presents a novel hybrid visual odometry (VO) framework that leverages pose-only supervision, offering a balanced solution between robustness and the need for extensive labeling. We propose two cost-effective and innovative designs: a self-supervised homographic pre-training for enhancing optical flow learning from pose-only labels and a random patch-based salient point detection strategy for more accurate optical flow patch extraction. These designs eliminate the need for dense optical flow labels for training and significantly improve the generalization capability of the system in diverse and challenging environments. Our pose-only supervised method achieves competitive performance on standard datasets and greater robustness and generalization ability in extreme and unseen scenarios, even compared to dense optical flow-supervised state-of-the-art methods.
Create account to get full access
Overview
- This paper introduces a novel approach for sparse visual odometry using pose-only supervision.
- It focuses on developing a salient sparse visual odometry system that can accurately estimate camera poses from images, without requiring dense depth or 3D reconstruction.
- The proposed method leverages self-supervision and sparse keypoints to enable pose estimation from monocular images, avoiding the need for expensive depth sensors or complex 3D reconstruction.
Plain English Explanation
Sparse visual odometry is a technique used to estimate the position and orientation (pose) of a camera as it moves through an environment, using only the information from the camera itself. This is useful for applications like augmented reality, robot navigation, and self-driving cars.
Traditionally, sparse visual odometry systems have required either depth information from additional sensors or complex 3D reconstruction algorithms. This paper presents a new approach that can estimate camera poses using only the 2D images from a monocular camera, without needing any depth data. The key innovation is the use of "salient" sparse keypoints - important visual features that are automatically identified in the images. By tracking these keypoints over time, the system can infer the camera's movement and estimate its pose.
The main benefit of this approach is that it is less resource-intensive and more widely applicable than traditional visual odometry methods. It can be used in scenarios where depth sensors are not available or where 3D reconstruction is too computationally expensive. The authors demonstrate the effectiveness of their technique on several benchmark datasets, showing that it can achieve accurate pose estimation using only 2D image data.
Technical Explanation
The authors propose a sparse visual odometry system that leverages "salient" sparse keypoints to estimate camera poses from monocular images, without requiring depth information or 3D reconstruction.
The core of their approach is a neural network architecture that consists of several components:
- A feature extraction module that identifies salient keypoints in the input images.
- A pose estimation module that predicts the 6-DoF camera pose from the detected keypoints.
- A self-supervision module that trains the system end-to-end using only ground-truth camera poses, without any depth or 3D information.
The feature extraction module is trained to detect keypoints that are "salient" - i.e., visually distinctive and stable over time. By tracking these salient keypoints across frames, the pose estimation module can infer the camera's movement and estimate its 6-DoF pose (position and orientation).
Crucially, the system is trained using only ground-truth camera poses, without any access to depth data or 3D reconstructions. This "pose-only supervision" enables the model to learn effective visual odometry capabilities from 2D image data alone, avoiding the need for expensive depth sensors or complex 3D pipelines.
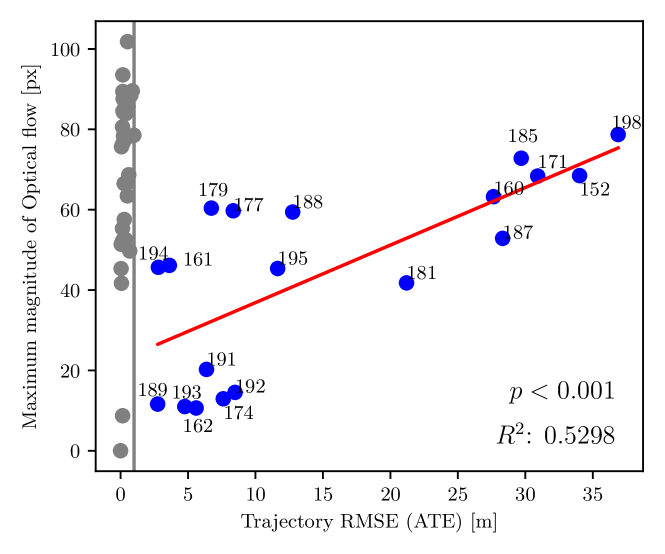
The authors evaluate their approach on several benchmark datasets for visual odometry and show that it can achieve competitive performance compared to traditional methods that rely on depth or 3D information. They also analyze the types of keypoints detected by their system and demonstrate the importance of saliency for accurate pose estimation.
Critical Analysis
The key innovation of this work is the ability to perform sparse visual odometry using only 2D image data and pose-only supervision, without requiring depth information or 3D reconstruction. This is a significant advancement over traditional visual odometry techniques, as it reduces the hardware and computational requirements, making the method more widely applicable.
However, the paper does not fully address the potential limitations of this approach. For example, the reliance on salient keypoints may make the system vulnerable to changes in lighting, viewpoint, or scene content, which could affect the reliability of the pose estimates. Additionally, the authors do not explore the impact of sensor noise or other real-world challenges that may arise in practical applications.
Furthermore, while the experimental results are promising, the paper would benefit from a more comprehensive evaluation, including comparisons to a broader range of state-of-the-art visual odometry and SLAM methods. This would help to better understand the strengths and weaknesses of the proposed approach and its potential advantages over alternative techniques.
Overall, this paper presents an interesting and potentially impactful contribution to the field of visual odometry. However, further research is needed to fully understand the limitations and real-world applicability of the proposed method.
Conclusion
This paper introduces a novel approach for sparse visual odometry that can accurately estimate camera poses from monocular images, without requiring depth information or 3D reconstruction. The key innovation is the use of "salient" sparse keypoints and a self-supervised training process that leverages only ground-truth camera poses.
The proposed method has several potential benefits, including reduced hardware and computational requirements, and improved applicability to a wider range of scenarios compared to traditional visual odometry techniques. The experimental results demonstrate the effectiveness of the approach on benchmark datasets, but further research is needed to fully understand its limitations and real-world performance.
Overall, this work represents an important step forward in the field of visual odometry, paving the way for more accessible and versatile camera pose estimation systems that can be deployed in a variety of applications, from augmented reality to robot navigation and self-driving cars.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Supervised Geometry-Guided Initialization for Robust Monocular Visual Odometry
Takayuki Kanai, Igor Vasiljevic, Vitor Guizilini, Kazuhiro Shintani
0
0
Monocular visual odometry is a key technology in a wide variety of autonomous systems. Relative to traditional feature-based methods, that suffer from failures due to poor lighting, insufficient texture, large motions, etc., recent learning-based SLAM methods exploit iterative dense bundle adjustment to address such failure cases and achieve robust accurate localization in a wide variety of real environments, without depending on domain-specific training data. However, despite its potential, learning-based SLAM still struggles with scenarios involving large motion and object dynamics. In this paper, we diagnose key weaknesses in a popular learning-based SLAM model (DROID-SLAM) by analyzing major failure cases on outdoor benchmarks and exposing various shortcomings of its optimization process. We then propose the use of self-supervised priors leveraging a frozen large-scale pre-trained monocular depth estimation to initialize the dense bundle adjustment process, leading to robust visual odometry without the need to fine-tune the SLAM backbone. Despite its simplicity, our proposed method demonstrates significant improvements on KITTI odometry, as well as the challenging DDAD benchmark. Code and pre-trained models will be released upon publication.
6/4/2024

Self-supervised Pretraining and Finetuning for Monocular Depth and Visual Odometry
Boris Chidlovskii, Leonid Antsfeld
0
0
For the task of simultaneous monocular depth and visual odometry estimation, we propose learning self-supervised transformer-based models in two steps. Our first step consists in a generic pretraining to learn 3D geometry, using cross-view completion objective (CroCo), followed by self-supervised finetuning on non-annotated videos. We show that our self-supervised models can reach state-of-the-art performance 'without bells and whistles' using standard components such as visual transformers, dense prediction transformers and adapters. We demonstrate the effectiveness of our proposed method by running evaluations on six benchmark datasets, both static and dynamic, indoor and outdoor, with synthetic and real images. For all datasets, our method outperforms state-of-the-art methods, in particular for depth prediction task.
6/18/2024
🗣️
Visual Odometry with Neuromorphic Resonator Networks
Alpha Renner, Lazar Supic, Andreea Danielescu, Giacomo Indiveri, E. Paxon Frady, Friedrich T. Sommer, Yulia Sandamirskaya
0
0
Visual Odometry (VO) is a method to estimate self-motion of a mobile robot using visual sensors. Unlike odometry based on integrating differential measurements that can accumulate errors, such as inertial sensors or wheel encoders, visual odometry is not compromised by drift. However, image-based VO is computationally demanding, limiting its application in use cases with low-latency, -memory, and -energy requirements. Neuromorphic hardware offers low-power solutions to many vision and AI problems, but designing such solutions is complicated and often has to be assembled from scratch. Here we propose to use Vector Symbolic Architecture (VSA) as an abstraction layer to design algorithms compatible with neuromorphic hardware. Building from a VSA model for scene analysis, described in our companion paper, we present a modular neuromorphic algorithm that achieves state-of-the-art performance on two-dimensional VO tasks. Specifically, the proposed algorithm stores and updates a working memory of the presented visual environment. Based on this working memory, a resonator network estimates the changing location and orientation of the camera. We experimentally validate the neuromorphic VSA-based approach to VO with two benchmarks: one based on an event camera dataset and the other in a dynamic scene with a robotic task.
6/27/2024

Adaptive VIO: Deep Visual-Inertial Odometry with Online Continual Learning
Youqi Pan, Wugen Zhou, Yingdian Cao, Hongbin Zha
0
0
Visual-inertial odometry (VIO) has demonstrated remarkable success due to its low-cost and complementary sensors. However, existing VIO methods lack the generalization ability to adjust to different environments and sensor attributes. In this paper, we propose Adaptive VIO, a new monocular visual-inertial odometry that combines online continual learning with traditional nonlinear optimization. Adaptive VIO comprises two networks to predict visual correspondence and IMU bias. Unlike end-to-end approaches that use networks to fuse the features from two modalities (camera and IMU) and predict poses directly, we combine neural networks with visual-inertial bundle adjustment in our VIO system. The optimized estimates will be fed back to the visual and IMU bias networks, refining the networks in a self-supervised manner. Such a learning-optimization-combined framework and feedback mechanism enable the system to perform online continual learning. Experiments demonstrate that our Adaptive VIO manifests adaptive capability on EuRoC and TUM-VI datasets. The overall performance exceeds the currently known learning-based VIO methods and is comparable to the state-of-the-art optimization-based methods.
5/28/2024