Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach for open-world compositional zero-shot learning (CZSL) using attention-based simple primitives.
- The key idea is to learn a set of simple primitives that can be combined in an attention-based manner to represent and recognize unseen compositions of visual concepts.
- The model is designed to be adaptable and generalizable, allowing it to handle the challenges of open-world CZSL, where the set of compositions encountered during deployment may be different from those seen during training.
Plain English Explanation
The researchers in this paper are trying to solve a problem called "open-world compositional zero-shot learning." This is a mouthful, but it basically means teaching an AI system to recognize and understand new combinations of visual concepts, even if it hasn't seen those specific combinations before.
Imagine you've trained an AI to recognize individual objects like "dog," "chair," and "tree." Now you want it to be able to recognize new combinations of those objects, like a "dog sitting on a chair next to a tree." This is the challenge of compositional zero-shot learning.
The key innovation in this paper is the use of "attention-based simple primitives." The researchers create a set of basic building blocks or "primitives" that the AI can use to represent and recognize different visual concepts. By combining these primitives in an attention-based way, the AI can learn to understand new compositions it hasn't seen before.
The advantage of this approach is that it allows the AI to be more adaptable and generalize better to new situations. Instead of trying to memorize every possible combination of visual concepts, the AI can use its understanding of the underlying primitives to figure out new combinations on the fly.
Technical Explanation
The paper proposes a novel attention-based simple primitives model for open-world CZSL. The key idea is to learn a set of simple primitives that can be combined in an attention-based manner to represent and recognize unseen compositions of visual concepts.
The model consists of three main components:
- Primitive Encoder: This module encodes the input image into a set of primitive representations, which capture the basic visual elements present in the image.
- Primitive Attention: This component learns to attend to the relevant primitives when recognizing a particular composition, allowing the model to dynamically combine the primitives to represent unseen compositions.
- Composition Classifier: This final module takes the attended primitive representations and classifies the input image into the appropriate composition category.
The model is trained using a novel compositional training objective that encourages the primitives to be reusable and the attention mechanism to be flexible. This allows the model to generalize to new compositions not seen during training.
The researchers evaluate their approach on the MAC benchmark for CZSL, as well as a new dataset they introduce called Eyes of a Hawk, Ears of a Fox. The results demonstrate the effectiveness of the attention-based simple primitives model in achieving state-of-the-art performance on these challenging open-world CZSL tasks.
Critical Analysis
The paper presents a compelling approach to open-world CZSL, leveraging the core idea of attention-based simple primitives to enable flexible and generalizable composition understanding. The experimental results on the MAC benchmark and the new Eyes of a Hawk, Ears of a Fox dataset are promising, showcasing the model's ability to handle the challenges of this task.
However, the paper does not address some potential limitations of the approach. For instance, it's unclear how the model would scale to larger and more complex composition spaces, or how robust it would be to noise or ambiguity in the input images. Additionally, the paper does not provide a deep analysis of the learned primitives and attention mechanisms, which could yield valuable insights into the inner workings of the model.
Future research could explore ways to further improve the model's interpretability and robustness, as well as investigating its applicability to other domains beyond visual recognition, such as language understanding or multi-modal reasoning. Nonetheless, the attention-based simple primitives approach represents an important step forward in the field of open-world CZSL and could have significant implications for the development of more flexible and adaptable AI systems.
Conclusion
This paper introduces a novel attention-based simple primitives model for open-world compositional zero-shot learning. The key innovation is the use of a set of reusable primitives that can be dynamically combined via an attention mechanism to represent and recognize unseen compositions of visual concepts.
The experimental results demonstrate the effectiveness of this approach, which achieves state-of-the-art performance on challenging CZSL benchmarks. The paper's attention-based simple primitives model represents an important step towards more flexible and generalizable AI systems, with potential applications in areas like computer vision, natural language processing, and beyond.
Overall, this research highlights the value of learning modular and composable representations to tackle open-world challenges, and could inspire further advancements in the field of zero-shot and compositional learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attention Based Simple Primitives for Open World Compositional Zero-Shot Learning
Ans Munir, Faisal Z. Qureshi, Muhammad Haris Khan, Mohsen Ali
Compositional Zero-Shot Learning (CZSL) aims to predict unknown compositions made up of attribute and object pairs. Predicting compositions unseen during training is a challenging task. We are exploring Open World Compositional Zero-Shot Learning (OW-CZSL) in this study, where our test space encompasses all potential combinations of attributes and objects. Our approach involves utilizing the self-attention mechanism between attributes and objects to achieve better generalization from seen to unseen compositions. Utilizing a self-attention mechanism facilitates the model's ability to identify relationships between attribute and objects. The similarity between the self-attended textual and visual features is subsequently calculated to generate predictions during the inference phase. The potential test space may encompass implausible object-attribute combinations arising from unrestricted attribute-object pairings. To mitigate this issue, we leverage external knowledge from ConceptNet to restrict the test space to realistic compositions. Our proposed model, Attention-based Simple Primitives (ASP), demonstrates competitive performance, achieving results comparable to the state-of-the-art.
Read more7/19/2024

0
Contextual Interaction via Primitive-based Adversarial Training For Compositional Zero-shot Learning
Suyi Li, Chenyi Jiang, Shidong Wang, Yang Long, Zheng Zhang, Haofeng Zhang
Compositional Zero-shot Learning (CZSL) aims to identify novel compositions via known attribute-object pairs. The primary challenge in CZSL tasks lies in the significant discrepancies introduced by the complex interaction between the visual primitives of attribute and object, consequently decreasing the classification performance towards novel compositions. Previous remarkable works primarily addressed this issue by focusing on disentangling strategy or utilizing object-based conditional probabilities to constrain the selection space of attributes. Unfortunately, few studies have explored the problem from the perspective of modeling the mechanism of visual primitive interactions. Inspired by the success of vanilla adversarial learning in Cross-Domain Few-Shot Learning, we take a step further and devise a model-agnostic and Primitive-Based Adversarial training (PBadv) method to deal with this problem. Besides, the latest studies highlight the weakness of the perception of hard compositions even under data-balanced conditions. To this end, we propose a novel over-sampling strategy with object-similarity guidance to augment target compositional training data. We performed detailed quantitative analysis and retrieval experiments on well-established datasets, such as UT-Zappos50K, MIT-States, and C-GQA, to validate the effectiveness of our proposed method, and the state-of-the-art (SOTA) performance demonstrates the superiority of our approach. The code is available at https://github.com/lisuyi/PBadv_czsl.
Read more6/24/2024
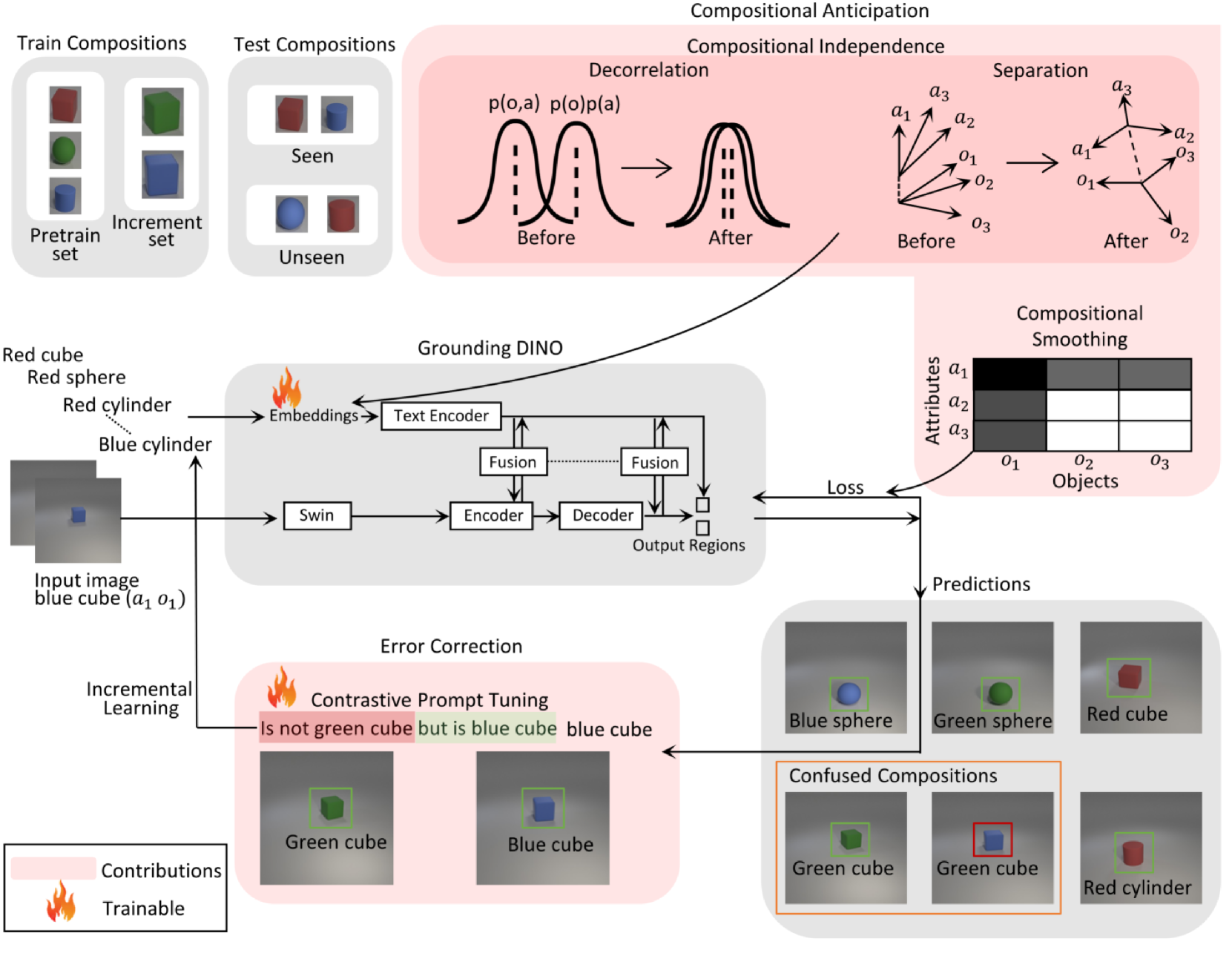
0
Anticipating Future Object Compositions without Forgetting
Youssef Zahran, Gertjan Burghouts, Yke Bauke Eisma
Despite the significant advancements in computer vision models, their ability to generalize to novel object-attribute compositions remains limited. Existing methods for Compositional Zero-Shot Learning (CZSL) mainly focus on image classification. This paper aims to enhance CZSL in object detection without forgetting prior learned knowledge. We use Grounding DINO and incorporate Compositional Soft Prompting (CSP) into it and extend it with Compositional Anticipation. We achieve a 70.5% improvement over CSP on the harmonic mean (HM) between seen and unseen compositions on the CLEVR dataset. Furthermore, we introduce Contrastive Prompt Tuning to incrementally address model confusion between similar compositions. We demonstrate the effectiveness of this method and achieve an increase of 14.5% in HM across the pretrain, increment, and unseen sets. Collectively, these methods provide a framework for learning various compositions with limited data, as well as improving the performance of underperforming compositions when additional data becomes available.
Read more9/4/2024

0
Cross-composition Feature Disentanglement for Compositional Zero-shot Learning
Yuxia Geng, Runkai Zhu, Jiaoyan Chen, Jintai Chen, Zhuo Chen, Xiang Chen, Can Xu, Yuxiang Wang, Xiaoliang Xu
Disentanglement of visual features of primitives (i.e., attributes and objects) has shown exceptional results in Compositional Zero-shot Learning (CZSL). However, due to the feature divergence of an attribute (resp. object) when combined with different objects (resp. attributes), it is challenging to learn disentangled primitive features that are general across different compositions. To this end, we propose the solution of cross-composition feature disentanglement, which takes multiple primitive-sharing compositions as inputs and constrains the disentangled primitive features to be general across these compositions. More specifically, we leverage a compositional graph to define the overall primitive-sharing relationships between compositions, and build a task-specific architecture upon the recently successful large pre-trained vision-language model (VLM) CLIP, with dual cross-composition disentangling adapters (called L-Adapter and V-Adapter) inserted into CLIP's frozen text and image encoders, respectively. Evaluation on three popular CZSL benchmarks shows that our proposed solution significantly improves the performance of CZSL, and its components have been verified by solid ablation studies.
Read more8/20/2024