`Eyes of a Hawk and Ears of a Fox': Part Prototype Network for Generalized Zero-Shot Learning
2404.08761
0
0

Abstract
Current approaches in Generalized Zero-Shot Learning (GZSL) are built upon base models which consider only a single class attribute vector representation over the entire image. This is an oversimplification of the process of novel category recognition, where different regions of the image may have properties from different seen classes and thus have different predominant attributes. With this in mind, we take a fundamentally different approach: a pre-trained Vision-Language detector (VINVL) sensitive to attribute information is employed to efficiently obtain region features. A learned function maps the region features to region-specific attribute attention used to construct class part prototypes. We conduct experiments on a popular GZSL benchmark consisting of the CUB, SUN, and AWA2 datasets where our proposed Part Prototype Network (PPN) achieves promising results when compared with other popular base models. Corresponding ablation studies and analysis show that our approach is highly practical and has a distinct advantage over global attribute attention when localized proposals are available.
Create account to get full access
Overview
- This paper proposes a "Part Prototype Network" (PPN) for generalized zero-shot learning (GZSL) - the task of recognizing objects belonging to classes not seen during training.
- The key idea is to learn part-level prototypes that capture the discriminative features of each class, allowing the model to recognize unseen classes by composing these prototypes.
- The authors show that this part-level approach outperforms previous holistic approaches on standard GZSL benchmarks, demonstrating the value of learning fine-grained visual representations for this challenging task.
Plain English Explanation
The researchers have developed a new machine learning model called the "Part Prototype Network" (PPN) that is designed to recognize objects belonging to classes that the model has never seen before during training. This task, known as generalized zero-shot learning (GZSL), is challenging because the model needs to learn to identify new classes without any examples of them.
The key insight behind the PPN is that rather than trying to learn a single representation for each class, the model instead learns to recognize the individual parts or components that make up each class. For example, instead of just learning what a car looks like as a whole, the model would learn to recognize the wheels, doors, headlights, and other distinctive parts of a car.
By breaking down the classes into these part-level prototypes, the model can then learn to combine these building blocks in new ways to recognize objects from classes it has never seen before. This part-based approach allows the model to be more flexible and adaptable, leveraging its knowledge of individual components to identify novel combinations.
The researchers show that this part-level representation learning outperforms previous "holistic" approaches to GZSL, where the model tries to learn a single, overall representation for each class. The PPN's ability to focus on the fine-grained, discriminative features of each class gives it an advantage in recognizing unseen objects.
Technical Explanation
The key innovation of the proposed Part Prototype Network (PPN) is its part-level representation learning for GZSL. Rather than learning a single prototype per class, PPN learns multiple part-level prototypes that capture the discriminative visual features of each class.
The architecture consists of a feature extraction backbone, a part detection module, and a part prototype learning module. The feature extraction backbone produces image-level features, while the part detection module identifies salient regions corresponding to the object parts. The part prototype learning module then learns a set of part-level prototypes for each class by clustering the part features.
During inference, the model composes the part-level prototypes to classify both seen and unseen classes. This part-based composition allows PPN to recognize novel object compositions, overcoming the limitations of previous holistic approaches to GZSL.
The authors evaluate PPN on standard GZSL benchmarks, including CUB, AWA2, and ImageNet. They demonstrate significant improvements over state-of-the-art GZSL methods, validating the effectiveness of the part-level representation learning approach.
Critical Analysis
The authors provide a thorough experimental evaluation of PPN, highlighting its strengths compared to previous GZSL methods. However, the paper does not deeply explore the limitations or potential issues with the approach.
For example, the part detection module relies on pre-trained part detectors, which may not generalize well to diverse object categories. Additionally, the part-level prototypes are learned in an unsupervised manner, which could lead to suboptimal representations for the GZSL task.
Further research is needed to understand the failure modes of PPN and explore ways to make the part-level representation learning more robust and generalizable. Investigating the interpretability and reliability of the part-based compositions would also be an important direction for future work.
Conclusion
This paper presents a novel "Part Prototype Network" approach for generalized zero-shot learning. By learning part-level prototypes that capture the discriminative visual features of each class, the model is able to compose these building blocks to recognize unseen object categories.
The empirical results demonstrate the effectiveness of this part-based representation learning approach, outperforming state-of-the-art GZSL methods on standard benchmarks. This work highlights the value of fine-grained visual understanding for the challenging task of recognizing novel object classes.
As machine learning systems are increasingly deployed in real-world applications, the ability to handle unseen classes will be crucial. The proposed PPN represents an important step towards more flexible and adaptable object recognition models, with potential impacts across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Evolutionary Generalized Zero-Shot Learning
Dubing Chen, Chenyi Jiang, Haofeng Zhang
0
0
Attribute-based Zero-Shot Learning (ZSL) has revolutionized the ability of models to recognize new classes not seen during training. However, with the advancement of large-scale models, the expectations have risen. Beyond merely achieving zero-shot generalization, there is a growing demand for universal models that can continually evolve in expert domains using unlabeled data. To address this, we introduce a scaled-down instantiation of this challenge: Evolutionary Generalized Zero-Shot Learning (EGZSL). This setting allows a low-performing zero-shot model to adapt to the test data stream and evolve online. We elaborate on three challenges of this special task, ie, catastrophic forgetting, initial prediction bias, and evolutionary data class bias. Moreover, we propose targeted solutions for each challenge, resulting in a generic method capable of continuous evolution from a given initial IGZSL model. Experiments on three popular GZSL benchmark datasets demonstrate that our model can learn from the test data stream while other baselines fail. Codes are available at url{https://github.com/cdb342/EGZSL}.
5/14/2024
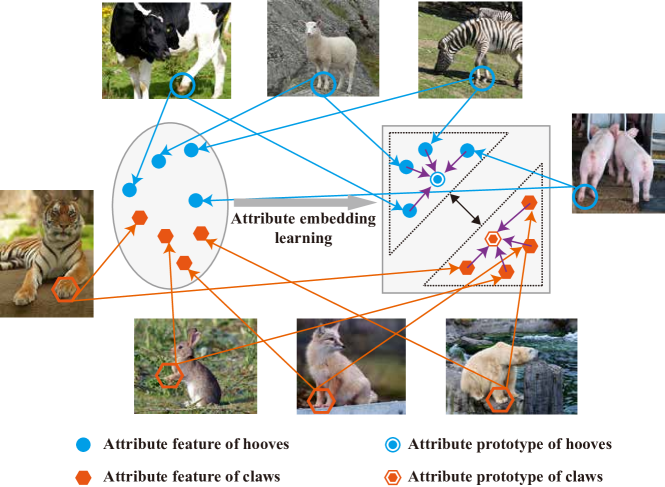
High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning
Yu Lei, Guoshuai Sheng, Fangfang Li, Quanxue Gao, Cheng Deng, Qin Li
0
0
Zero-shot learning(ZSL) aims to recognize new classes without prior exposure to their samples, relying on semantic knowledge from observed classes. However, current attention-based models may overlook the transferability of visual features and the distinctiveness of attribute localization when learning regional features in images. Additionally, they often overlook shared attributes among different objects. Highly discriminative attribute features are crucial for identifying and distinguishing unseen classes. To address these issues, we propose an innovative approach called High-Discriminative Attribute Feature Learning for Generalized Zero-Shot Learning (HDAFL). HDAFL optimizes visual features by learning attribute features to obtain discriminative visual embeddings. Specifically, HDAFL utilizes multiple convolutional kernels to automatically learn discriminative regions highly correlated with attributes in images, eliminating irrelevant interference in image features. Furthermore, we introduce a Transformer-based attribute discrimination encoder to enhance the discriminative capability among attributes. Simultaneously, the method employs contrastive loss to alleviate dataset biases and enhance the transferability of visual features, facilitating better semantic transfer between seen and unseen classes. Experimental results demonstrate the effectiveness of HDAFL across three widely used datasets.
4/9/2024

Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
Shiming Chen, Wenjin Hou, Salman Khan, Fahad Shahbaz Khan
0
0
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
4/12/2024

Dual Expert Distillation Network for Generalized Zero-Shot Learning
Zhijie Rao, Jingcai Guo, Xiaocheng Lu, Jingming Liang, Jie Zhang, Haozhao Wang, Kang Wei, Xiaofeng Cao
0
0
Zero-shot learning has consistently yielded remarkable progress via modeling nuanced one-to-one visual-attribute correlation. Existing studies resort to refining a uniform mapping function to align and correlate the sample regions and subattributes, ignoring two crucial issues: 1) the inherent asymmetry of attributes; and 2) the unutilized channel information. This paper addresses these issues by introducing a simple yet effective approach, dubbed Dual Expert Distillation Network (DEDN), where two experts are dedicated to coarse- and fine-grained visual-attribute modeling, respectively. Concretely, one coarse expert, namely cExp, has a complete perceptual scope to coordinate visual-attribute similarity metrics across dimensions, and moreover, another fine expert, namely fExp, consists of multiple specialized subnetworks, each corresponds to an exclusive set of attributes. Two experts cooperatively distill from each other to reach a mutual agreement during training. Meanwhile, we further equip DEDN with a newly designed backbone network, i.e., Dual Attention Network (DAN), which incorporates both region and channel attention information to fully exploit and leverage visual semantic knowledge. Experiments on various benchmark datasets indicate a new state-of-the-art.
4/30/2024