ATOM: Attention Mixer for Efficient Dataset Distillation

0
Sign in to get full access
Overview
- The paper introduces ATOM, a novel attention-based approach for efficient dataset distillation.
- Dataset distillation aims to compress a large training dataset into a small synthetic dataset that can be used to train models effectively.
- ATOM uses an attention mechanism to selectively mix and combine data from the original dataset, creating a compact yet informative synthetic dataset.
Plain English Explanation
ATOM is a new technique for dataset distillation. The goal of dataset distillation is to take a large, complicated dataset and create a much smaller, simplified version of it. This smaller dataset can then be used to train machine learning models just as effectively as the original, large dataset.
The key innovation in ATOM is the use of an "attention" mechanism. Attention allows the algorithm to selectively focus on and combine the most important parts of the original dataset, rather than just randomly sampling or simplifying it. This helps ensure the synthetic dataset captures the essential patterns and information needed to train effective models, even though it is much smaller than the original.
By creating a compact, informative synthetic dataset, ATOM can make the process of training machine learning models more efficient and accessible. Instead of needing vast amounts of raw training data, models can be trained on the distilled dataset, saving time and computational resources.
Technical Explanation
The core of ATOM is an attention-based module that learns to effectively combine and remix data from the original training dataset. The attention mechanism allows ATOM to selectively focus on and emphasize the most important and informative parts of the data when constructing the synthetic dataset.
ATOM's architecture consists of an encoder that processes the original training data, and a decoder that generates the synthetic dataset. The attention module sits between the encoder and decoder, using a learned attention strategy to selectively blend and remix the encoded data features. This attention-based "mixing" process allows ATOM to create a compact synthetic dataset that retains the essential characteristics of the original, larger dataset.
The authors evaluate ATOM on a range of image classification benchmarks, demonstrating that the synthetic datasets produced by ATOM can achieve comparable performance to training on the full original datasets, while using a fraction of the data. This suggests ATOM is an effective and efficient approach to dataset distillation.
Critical Analysis
The paper provides a thorough evaluation of ATOM's performance on standard image classification tasks, showing its effectiveness at dataset distillation. However, the authors acknowledge that ATOM's attention mechanism introduces additional complexity compared to simpler distillation methods.
It would be valuable to explore how ATOM's attention-based approach compares to other recent advancements in dataset distillation, such as contrastive approaches or techniques that explicitly model global structure and local details. Analyzing the trade-offs between ATOM's performance and its added complexity could help further understand the merits of attention-based distillation.
Additionally, while the paper focuses on image classification, it would be valuable to explore how ATOM's attention-based approach might extend to other domains, such as text-to-image generation or other types of structured data. Demonstrating the versatility of the approach could broaden its applicability and impact.
Conclusion
ATOM introduces an innovative attention-based approach to dataset distillation, allowing for the creation of compact synthetic datasets that can effectively train machine learning models. By selectively combining and remixing data features using a learned attention strategy, ATOM can produce informative distilled datasets that achieve strong performance while using a fraction of the original training data.
This work contributes to the growing body of research on efficient data utilization, which is crucial for making machine learning more accessible and practical, particularly in resource-constrained environments. ATOM's attention-based distillation technique represents a promising step forward in this direction, and its potential applications across diverse domains warrant further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ATOM: Attention Mixer for Efficient Dataset Distillation
Samir Khaki, Ahmad Sajedi, Kai Wang, Lucy Z. Liu, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
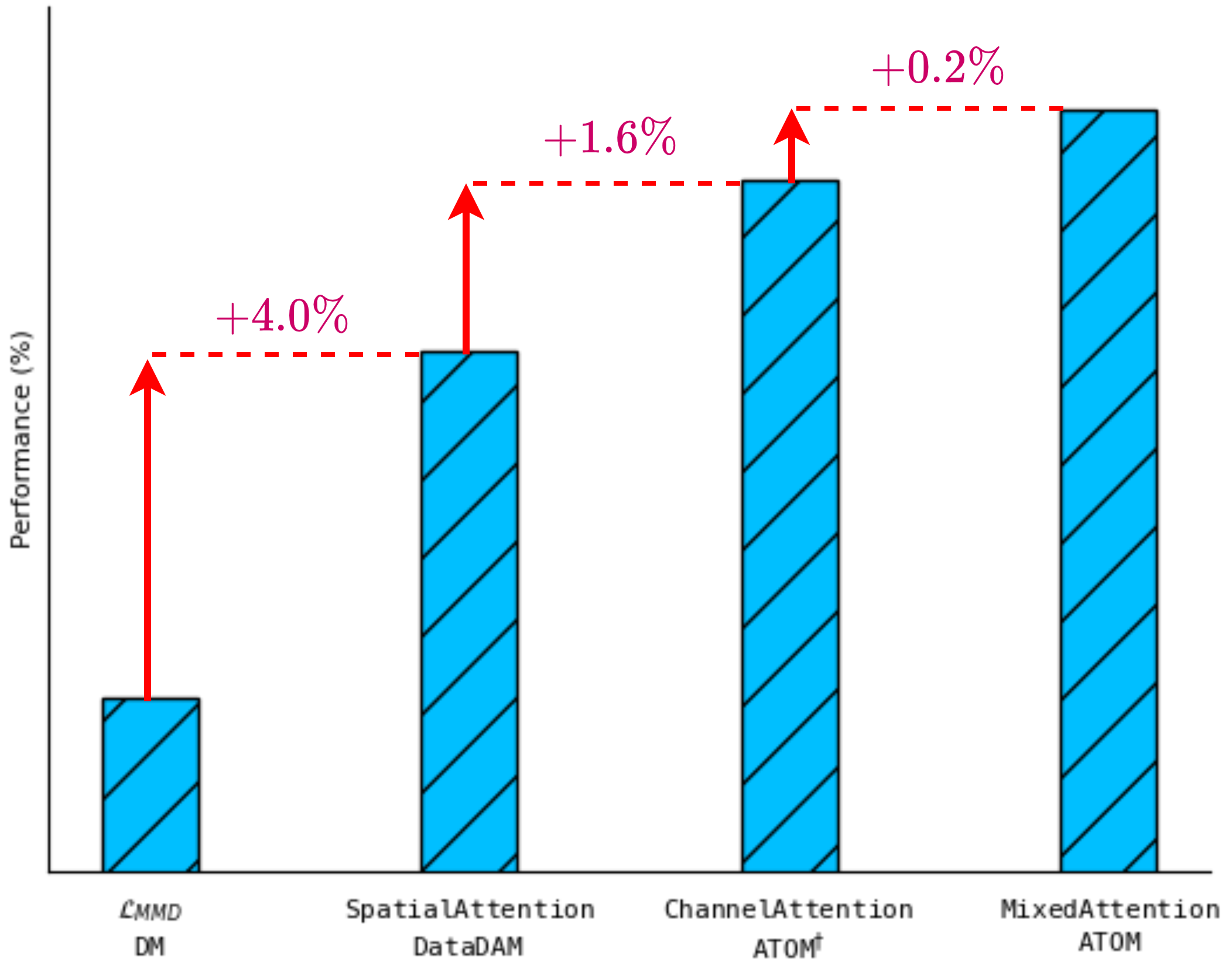
Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.
Read more5/3/2024
✨
0
Attention-guided Feature Distillation for Semantic Segmentation
Amir M. Mansourian, Arya Jalali, Rozhan Ahmadi, Shohreh Kasaei
In contrast to existing complex methodologies commonly employed for distilling knowledge from a teacher to a student, this paper showcases the efficacy of a simple yet powerful method for utilizing refined feature maps to transfer attention. The proposed method has proven to be effective in distilling rich information, outperforming existing methods in semantic segmentation as a dense prediction task. The proposed Attention-guided Feature Distillation (AttnFD) method, employs the Convolutional Block Attention Module (CBAM), which refines feature maps by taking into account both channel-specific and spatial information content. Simply using the Mean Squared Error (MSE) loss function between the refined feature maps of the teacher and the student, AttnFD demonstrates outstanding performance in semantic segmentation, achieving state-of-the-art results in terms of improving the mean Intersection over Union (mIoU) of the student network on the PascalVoc 2012, Cityscapes, COCO, and CamVid datasets.
Read more8/27/2024
0
Attend, Distill, Detect: Attention-aware Entropy Distillation for Anomaly Detection
Sushovan Jena, Vishwas Saini, Ujjwal Shaw, Pavitra Jain, Abhay Singh Raihal, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Arnav Bhavsar
Unsupervised anomaly detection encompasses diverse applications in industrial settings where a high-throughput and precision is imperative. Early works were centered around one-class-one-model paradigm, which poses significant challenges in large-scale production environments. Knowledge-distillation based multi-class anomaly detection promises a low latency with a reasonably good performance but with a significant drop as compared to one-class version. We propose a DCAM (Distributed Convolutional Attention Module) which improves the distillation process between teacher and student networks when there is a high variance among multiple classes or objects. Integrated multi-scale feature matching strategy to utilise a mixture of multi-level knowledge from the feature pyramid of the two networks, intuitively helping in detecting anomalies of varying sizes which is also an inherent problem in the multi-class scenario. Briefly, our DCAM module consists of Convolutional Attention blocks distributed across the feature maps of the student network, which essentially learns to masks the irrelevant information during student learning alleviating the cross-class interference problem. This process is accompanied by minimizing the relative entropy using KL-Divergence in Spatial dimension and a Channel-wise Cosine Similarity between the same feature maps of teacher and student. The losses enables to achieve scale-invariance and capture non-linear relationships. We also highlight that the DCAM module would only be used during training and not during inference as we only need the learned feature maps and losses for anomaly scoring and hence, gaining a performance gain of 3.92% than the multi-class baseline with a preserved latency.
Read more5/13/2024
✨
0
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
Read more4/9/2024