Attribute-driven Disentangled Representation Learning for Multimodal Recommendation

0

Sign in to get full access
Overview
- This paper proposes a new approach for multimodal recommendation called Attribute-driven Disentangled Representation Learning (ADRL).
- ADRL learns disentangled representations from user attributes and item features, which can capture the underlying factors that influence user preferences.
- The authors demonstrate that ADRL outperforms state-of-the-art multimodal recommendation methods on several real-world datasets.
Plain English Explanation
The paper introduces a new way to make multimodal recommendations - recommendations that use multiple types of data, like text and images. The key idea is to learn disentangled representations from user attributes (like age and gender) and item features (like product descriptions and photos).
These disentangled representations capture the underlying factors that influence what a user likes, without getting the different factors mixed together. For example, the model might learn separate representations for a user's age, their personal style, and the type of products they tend to prefer.
By learning these disentangled representations, the model can make better recommendations that are tailored to each user's unique preferences. The authors show that their approach, called Attribute-driven Disentangled Representation Learning (ADRL), outperforms other state-of-the-art multimodal recommendation methods on real-world data.
Technical Explanation
The ADRL model works by first learning disentangled representations of user attributes and item features. It does this using a variational autoencoder (VAE) architecture, where the latent space is structured to capture the underlying factors that influence user preferences.
Specifically, the model learns separate latent representations for user attributes (e.g. age, gender) and item features (e.g. product descriptions, images). These disentangled representations are then used to predict user-item interactions in a collaborative filtering framework.
The authors evaluate ADRL on several real-world datasets for movie, book, and e-commerce recommendations. They show that ADRL significantly outperforms state-of-the-art multimodal recommendation methods, such as graph-based unsupervised disentangled representation learning and triple disentangled representation learning.
Critical Analysis
One limitation of the ADRL model is that it assumes the underlying factors influencing user preferences can be neatly separated into user attributes and item features. In reality, these factors may be more complex and intertwined. Additionally, the model relies on having access to rich user and item metadata, which may not always be available in real-world scenarios.
The authors do not explore how ADRL's performance might scale with larger and more diverse datasets, or how it might handle dynamic user preferences and evolving item catalogs. Further research is needed to understand the model's robustness and generalizability.
While the results are promising, it's important to consider potential privacy and fairness concerns associated with using personal user attributes to drive recommendation systems. Careful consideration of these ethical implications would be valuable.
Conclusion
The ADRL model presents a novel approach to multimodal recommendation that leverages disentangled representations of user attributes and item features. By learning these underlying factors separately, the model can make more personalized and effective recommendations.
The promising results demonstrate the potential of disentangled representation learning for improving recommendation systems. Further research is needed to address the model's limitations and explore its broader applicability and implications. Overall, this work contributes to the ongoing efforts to create more sophisticated and user-centric recommendation technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Attribute-driven Disentangled Representation Learning for Multimodal Recommendation
Zhenyang Li, Fan Liu, Yinwei Wei, Zhiyong Cheng, Liqiang Nie, Mohan Kankanhalli
Recommendation algorithms forecast user preferences by correlating user and item representations derived from historical interaction patterns. In pursuit of enhanced performance, many methods focus on learning robust and independent representations by disentangling the intricate factors within interaction data across various modalities in an unsupervised manner. However, such an approach obfuscates the discernment of how specific factors (e.g., category or brand) influence the outcomes, making it challenging to regulate their effects. In response to this challenge, we introduce a novel method called Attribute-Driven Disentangled Representation Learning (short for AD-DRL), which explicitly incorporates attributes from different modalities into the disentangled representation learning process. By assigning a specific attribute to each factor in multimodal features, AD-DRL can disentangle the factors at both attribute and attribute-value levels. To obtain robust and independent representations for each factor associated with a specific attribute, we first disentangle the representations of features both within and across different modalities. Moreover, we further enhance the robustness of the representations by fusing the multimodal features of the same factor. Empirical evaluations conducted on three public real-world datasets substantiate the effectiveness of AD-DRL, as well as its interpretability and controllability.
Read more8/1/2024
0
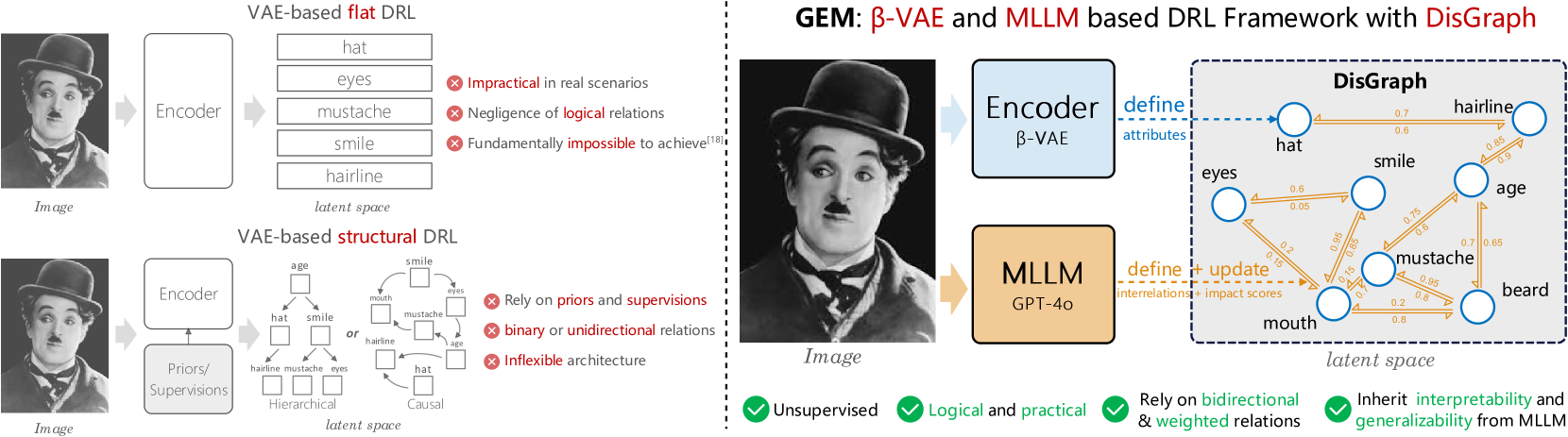
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, Wenjun Zeng
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
Read more7/30/2024
❗
0
Disentangled Representation Learning
Xin Wang, Hong Chen, Si'ao Tang, Zihao Wu, Wenwu Zhu
Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form. The process of separating underlying factors of variation into variables with semantic meaning benefits in learning explainable representations of data, which imitates the meaningful understanding process of humans when observing an object or relation. As a general learning strategy, DRL has demonstrated its power in improving the model explainability, controlability, robustness, as well as generalization capacity in a wide range of scenarios such as computer vision, natural language processing, and data mining. In this article, we comprehensively investigate DRL from various aspects including motivations, definitions, methodologies, evaluations, applications, and model designs. We first present two well-recognized definitions, i.e., Intuitive Definition and Group Theory Definition for disentangled representation learning. We further categorize the methodologies for DRL into four groups from the following perspectives, the model type, representation structure, supervision signal, and independence assumption. We also analyze principles to design different DRL models that may benefit different tasks in practical applications. Finally, we point out challenges in DRL as well as potential research directions deserving future investigations. We believe this work may provide insights for promoting the DRL research in the community.
Read more6/28/2024
0
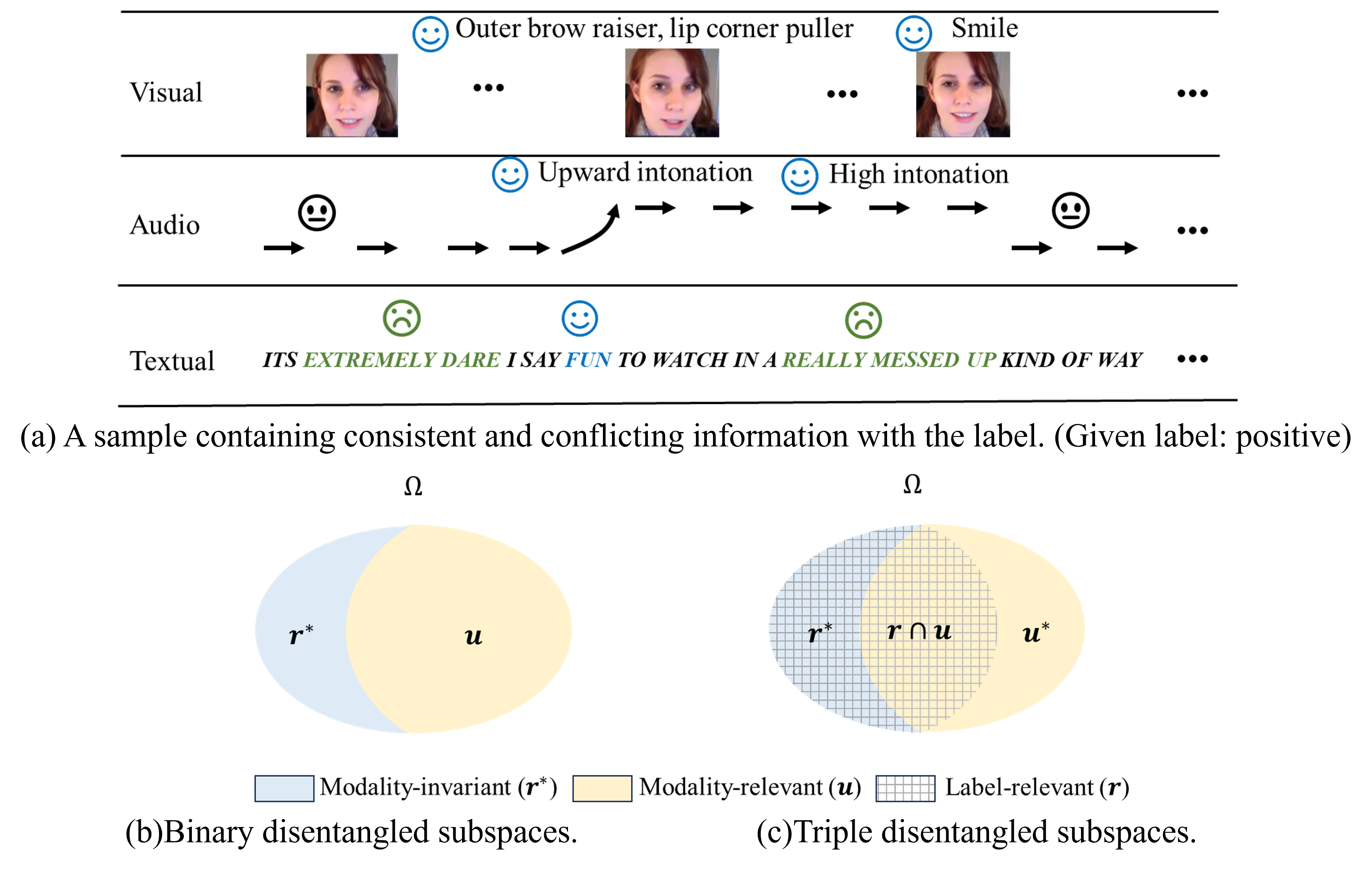
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Ying Zhou, Xuefeng Liang, Han Chen, Yin Zhao, Xin Chen, Lida Yu
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Read more4/9/2024