Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models

0
Sign in to get full access
Overview
- This paper presents a novel approach for learning disentangled representations from multimodal data using large language models and graph neural networks.
- The key idea is to leverage the complementary strengths of language models and graph-based methods to discover the underlying factors that generate the observed data.
- The method is unsupervised, meaning it can learn meaningful representations without requiring labeled training data.
Plain English Explanation
The paper introduces a new way to learn disentangled representations from data that comes in multiple formats, like text and images. This is done by combining the power of large language models with graph neural networks.
The key insight is that language models are great at capturing high-level semantic information, while graph networks can discover the underlying structure and relationships in the data. By bringing these two approaches together, the method can learn representations that are disentangled - meaning the learned features correspond to the independent factors that generated the observed data.
This is useful because disentangled representations are more interpretable and can generalize better to new tasks and datasets. The method is also "unsupervised", which means it can discover these meaningful representations without requiring any manual labeling of the training data.
Technical Explanation
The core of the proposed approach is a graph-based autoencoder that learns disentangled representations from multimodal data. The encoder maps the input data (e.g. images, text) into a graph-structured latent space, where each node represents a disentangled factor of variation.
The graph structure is learned in an unsupervised way by leveraging the inductive biases of large pretrained language models. Specifically, the method constructs a graph from the language model's attention patterns, which capture semantic relationships between different concepts.
This graph-structured latent representation is then used by a decoder to reconstruct the original input. The training objective encourages the learned representations to be both informative (i.e. allow accurate reconstruction) and disentangled (i.e. the latent factors capture independent generative factors).
Experiments on various multimodal benchmarks demonstrate the effectiveness of the proposed approach in learning disentangled and interpretable representations without supervision. The learned representations are shown to achieve strong performance on downstream tasks like few-shot classification and out-of-distribution generalization.
Critical Analysis
One limitation of the work is that it relies on the availability of large pretrained language models, which may not always be feasible, especially in low-resource settings. Additionally, the graph construction process, while unsupervised, could potentially be sensitive to the choice of language model and hyperparameters.
The paper also does not provide a detailed analysis of the learned disentangled factors and how they correspond to the underlying generative factors of the data. Further investigation into the interpretability and semantics of the learned representations could strengthen the claims about disentanglement.
Moreover, the experiments are primarily focused on evaluating the representations on supervised downstream tasks. It would be valuable to see assessments of the representations' unsupervised properties, such as their ability to discover meaningful structures or clusters in the data without any task-specific labels.
Conclusion
This paper presents an innovative approach for learning disentangled representations from multimodal data by combining the strengths of large language models and graph neural networks. The key insight is to leverage the semantic relationships captured by language models to construct a graph-structured latent space that can discover the independent factors underlying the observed data.
The unsupervised nature of the method and its strong performance on various benchmarks suggest that it could be a valuable tool for representation learning in a wide range of applications, from few-shot learning to out-of-distribution generalization. Further research into the interpretability and generative properties of the learned representations could help unlock their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, Wenjun Zeng
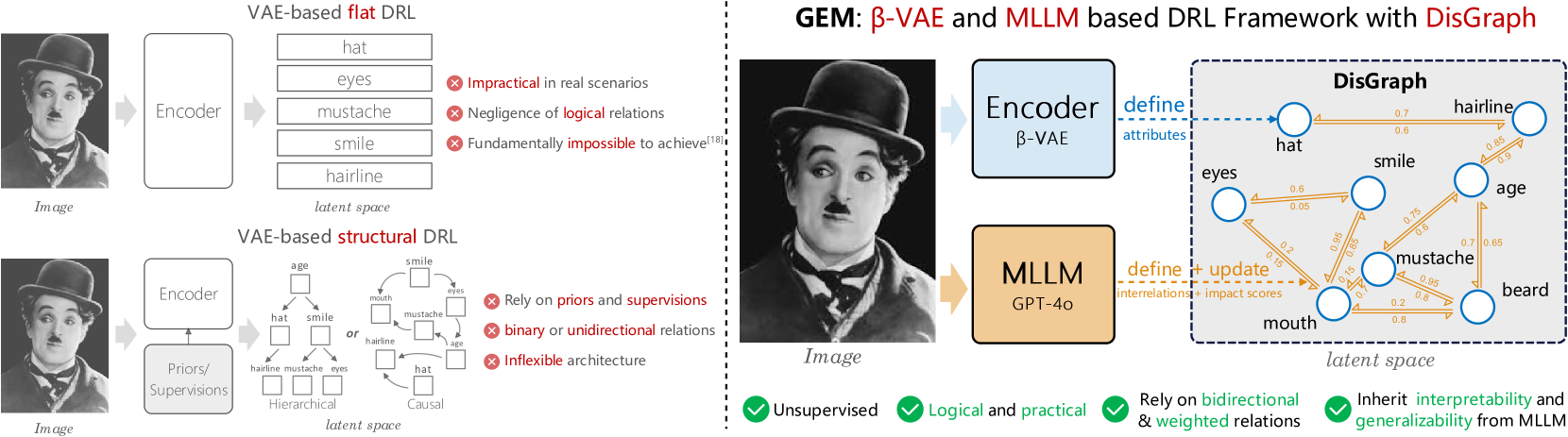
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
Read more7/30/2024

0
Attribute-driven Disentangled Representation Learning for Multimodal Recommendation
Zhenyang Li, Fan Liu, Yinwei Wei, Zhiyong Cheng, Liqiang Nie, Mohan Kankanhalli
Recommendation algorithms forecast user preferences by correlating user and item representations derived from historical interaction patterns. In pursuit of enhanced performance, many methods focus on learning robust and independent representations by disentangling the intricate factors within interaction data across various modalities in an unsupervised manner. However, such an approach obfuscates the discernment of how specific factors (e.g., category or brand) influence the outcomes, making it challenging to regulate their effects. In response to this challenge, we introduce a novel method called Attribute-Driven Disentangled Representation Learning (short for AD-DRL), which explicitly incorporates attributes from different modalities into the disentangled representation learning process. By assigning a specific attribute to each factor in multimodal features, AD-DRL can disentangle the factors at both attribute and attribute-value levels. To obtain robust and independent representations for each factor associated with a specific attribute, we first disentangle the representations of features both within and across different modalities. Moreover, we further enhance the robustness of the representations by fusing the multimodal features of the same factor. Empirical evaluations conducted on three public real-world datasets substantiate the effectiveness of AD-DRL, as well as its interpretability and controllability.
Read more8/1/2024
❗
0
Disentangled Representation Learning
Xin Wang, Hong Chen, Si'ao Tang, Zihao Wu, Wenwu Zhu
Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form. The process of separating underlying factors of variation into variables with semantic meaning benefits in learning explainable representations of data, which imitates the meaningful understanding process of humans when observing an object or relation. As a general learning strategy, DRL has demonstrated its power in improving the model explainability, controlability, robustness, as well as generalization capacity in a wide range of scenarios such as computer vision, natural language processing, and data mining. In this article, we comprehensively investigate DRL from various aspects including motivations, definitions, methodologies, evaluations, applications, and model designs. We first present two well-recognized definitions, i.e., Intuitive Definition and Group Theory Definition for disentangled representation learning. We further categorize the methodologies for DRL into four groups from the following perspectives, the model type, representation structure, supervision signal, and independence assumption. We also analyze principles to design different DRL models that may benefit different tasks in practical applications. Finally, we point out challenges in DRL as well as potential research directions deserving future investigations. We believe this work may provide insights for promoting the DRL research in the community.
Read more6/28/2024

0
Disentangled Generative Graph Representation Learning
Xinyue Hu, Zhibin Duan, Xinyang Liu, Yuxin Li, Bo Chen, Mingyuan Zhou
Recently, generative graph models have shown promising results in learning graph representations through self-supervised methods. However, most existing generative graph representation learning (GRL) approaches rely on random masking across the entire graph, which overlooks the entanglement of learned representations. This oversight results in non-robustness and a lack of explainability. Furthermore, disentangling the learned representations remains a significant challenge and has not been sufficiently explored in GRL research. Based on these insights, this paper introduces DiGGR (Disentangled Generative Graph Representation Learning), a self-supervised learning framework. DiGGR aims to learn latent disentangled factors and utilizes them to guide graph mask modeling, thereby enhancing the disentanglement of learned representations and enabling end-to-end joint learning. Extensive experiments on 11 public datasets for two different graph learning tasks demonstrate that DiGGR consistently outperforms many previous self-supervised methods, verifying the effectiveness of the proposed approach.
Read more8/27/2024