The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
2312.12870
0
1
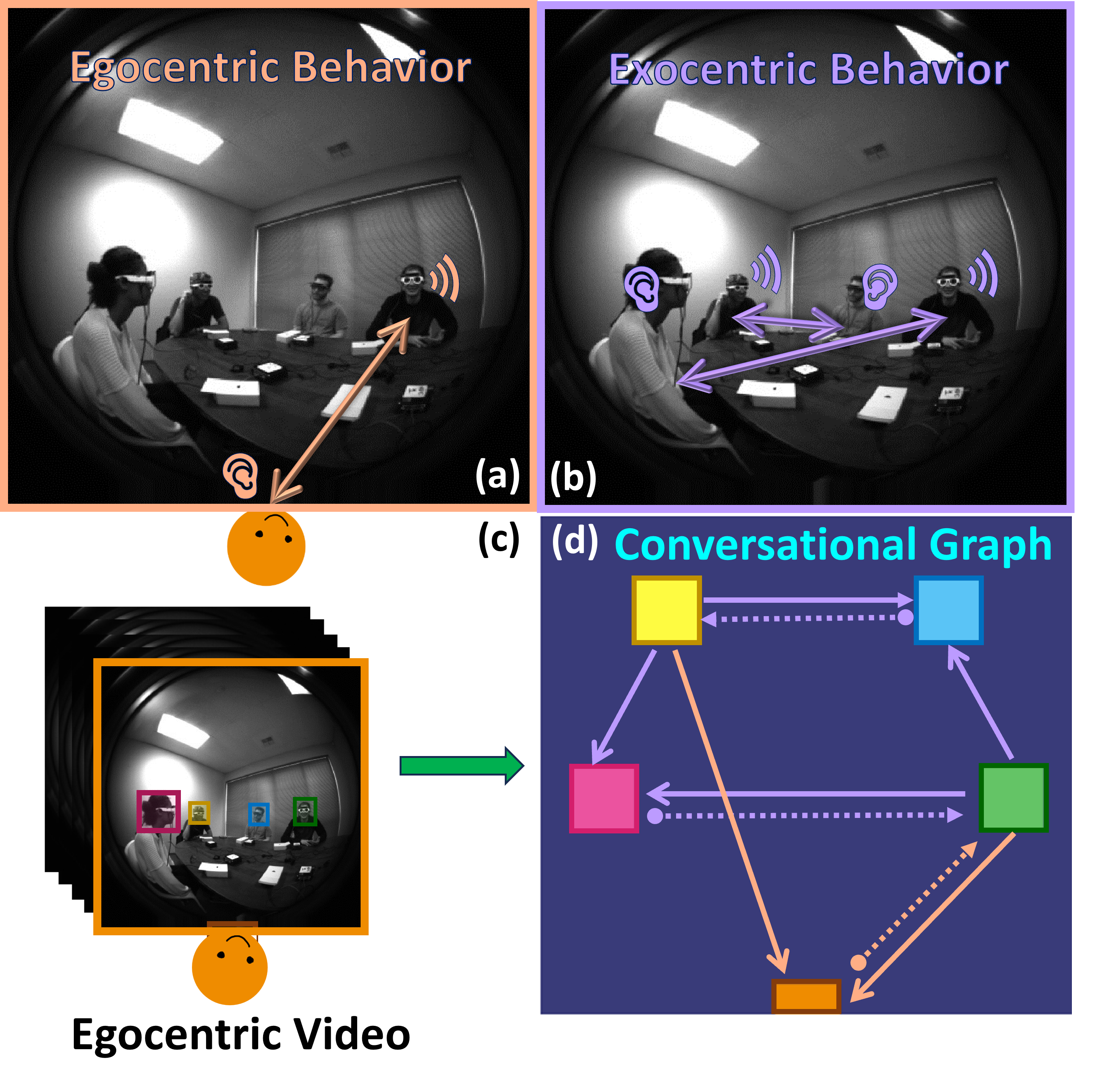
Abstract
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal framework -- Audio-Visual Conversational Attention (AV-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we adopt the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes multi-speaker and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Check our project page at https://vjwq.github.io/AV-CONV/.
Create account to get full access
Overview
- This paper introduces the "Audio-Visual Conversational Graph" - a framework for analyzing multi-modal conversations from both an egocentric (participant) and exocentric (observer) perspective.
- The approach aims to capture the complex interactions and dynamics within conversations by representing them as a graph structure with audio-visual cues.
- The authors demonstrate how this framework can be used to gain insights into conversational behaviors and dynamics.
Plain English Explanation
The paper discusses a new way of analyzing conversations that happen in the real world. Conversations involve not just the words people say, but also things like their body language, facial expressions, and tone of voice. The researchers created a system that can capture all of these different aspects of a conversation and represent them visually as a "graph."
This graph shows how the participants in a conversation are interacting with each other, both from their own perspective (egocentric) and from an outside observer's perspective (exocentric). By looking at the graph, the researchers can get a better understanding of the dynamics and flow of the conversation.
For example, the graph might show that one person is doing most of the talking, while others are mostly listening. Or it could reveal subtle cues, like one person frequently nodding or making eye contact with another. These insights can be useful for applications like improving communication skills, analyzing business meetings, or even understanding social dynamics.
Technical Explanation
The key components of the Audio-Visual Conversational Graph framework are:
-
Audio-Visual Cues: The system captures a range of audio-visual signals from the conversation, including speech, gaze, head pose, and body posture. These cues are extracted using computer vision and audio processing techniques.
-
Egocentric and Exocentric Perspectives: The framework represents the conversation from both the perspective of each individual participant (egocentric) and an external observer (exocentric). This allows analysis of the conversation at both the individual and group levels.
-
Graph Representation: The audio-visual cues are used to construct a dynamic graph structure, where nodes represent the conversation participants and edges capture the interactions between them over time. The edge weights and dynamics reflect the strength and patterns of the audio-visual interactions.
-
Graph Analysis: The researchers demonstrate how various graph-based analysis techniques can be applied to the conversational graph to gain insights, such as identifying dominant speakers, detecting engagement patterns, and characterizing the overall conversational dynamics.
The paper validates the framework through experiments on both simulated and real-world conversational datasets, showing its ability to capture meaningful patterns that align with human observations.
Critical Analysis
The audio-visual conversational graph framework proposed in this paper is a novel and promising approach for analyzing complex multi-modal interactions. By jointly considering audio and visual cues, and representing the conversation from multiple perspectives, the framework provides a more comprehensive understanding of conversational dynamics compared to approaches that focus on a single modality or perspective.
However, the paper does not address some potential limitations and areas for further research. For instance, the framework currently relies on accurate extraction of audio-visual signals, which can be challenging in real-world settings with noise, occlusions, and varying environmental conditions. Exploring the robustness of the framework to these factors would be an important next step.
Additionally, the paper focuses primarily on demonstrating the feasibility and potential of the approach, but does not delve deeply into the practical applications and implications. Further research could investigate how the insights gained from the conversational graph analysis can be leveraged to improve communication, collaboration, and social understanding in various domains.
Conclusion
The Audio-Visual Conversational Graph presented in this paper represents a significant advancement in the field of conversation analysis. By capturing the rich audio-visual cues of a conversation and representing them in a graph structure, the framework enables a more holistic and nuanced understanding of conversational dynamics.
The ability to analyze conversations from both egocentric and exocentric perspectives opens up new avenues for applications in areas such as communication skills training, meeting analysis, and social interaction understanding. As the framework is further refined and tested in real-world settings, it has the potential to become a powerful tool for enhancing human-to-human and human-to-machine interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024

Identification of Conversation Partners from Egocentric Video
Tobias Dorszewski, S{o}ren A. Fuglsang, Jens Hjortkj{ae}r
0
0
Communicating in noisy, multi-talker environments is challenging, especially for people with hearing impairments. Egocentric video data can potentially be used to identify a user's conversation partners, which could be used to inform selective acoustic amplification of relevant speakers. Recent introduction of datasets and tasks in computer vision enable progress towards analyzing social interactions from an egocentric perspective. Building on this, we focus on the task of identifying conversation partners from egocentric video and describe a suitable dataset. Our dataset comprises 69 hours of egocentric video of diverse multi-conversation scenarios where each individual was assigned one or more conversation partners, providing the labels for our computer vision task. This dataset enables the development and assessment of algorithms for identifying conversation partners and evaluating related approaches. Here, we describe the dataset alongside initial baseline results of this ongoing work, aiming to contribute to the exciting advancements in egocentric video analysis for social settings.
6/13/2024
👁️
Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
Thanh-Dat Truong, Khoa Luu
0
0
Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the selfish view. First, we present a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
5/16/2024

Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
Sagnik Majumder, Ziad Al-Halah, Kristen Grauman
0
0
We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. Our method uses a masked auto-encoding framework to synthesize masked binaural (multi-channel) audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. Through extensive experiments, we show that our features are generic enough to improve over multiple state-of-the-art baselines on both tasks on two challenging egocentric video datasets that offer binaural audio, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
5/7/2024