Retrieval-Augmented Egocentric Video Captioning
2401.00789
0
0

Abstract
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
Create account to get full access
Overview
- This paper proposes a Retrieval-Augmented Egocentric Video Captioning (RAEVC) model that leverages external information to improve video captioning for egocentric (first-person) video.
- The model retrieves relevant video clips from a large database and uses the retrieved information to enhance the generation of captions for the target egocentric video.
- The approach aims to address the challenges of egocentric video captioning, such as the limited field of view and the need for context to understand the actions and interactions.
Plain English Explanation
The paper describes a system that can generate descriptions for videos recorded from a person's perspective (known as "egocentric" videos). Typically, these types of videos can be difficult to caption accurately because they have a limited viewpoint and lack broader context. To address this, the researchers developed a model that can retrieve relevant video clips from a database and use the information from those clips to enhance the captions for the target egocentric video.
The key idea is that by bringing in additional information from similar videos, the model can better understand the actions, objects, and interactions happening in the egocentric video, leading to more accurate and informative captions. This approach aims to address the challenges of limited viewpoint and lack of broader context that are common in egocentric videos.
Technical Explanation
The Retrieval-Augmented Egocentric Video Captioning (RAEVC) model consists of two main components:
-
Cross-view Visual Representation Alignment: This component aligns the visual representations of the target egocentric video and the retrieved exocentric (third-person) video clips, allowing for effective information transfer between the two domains.
-
Retrieval-Augmented Caption Generation: This component takes the aligned visual representations and generates captions for the target egocentric video, using the retrieved information to enhance the captioning process.
The key technical innovations include:
- Multimodal Retrieval and Alignment: The model retrieves relevant video clips from a large database and aligns their visual representations with the target egocentric video.
- Retrieval-Augmented Caption Generation: The caption generation module leverages the aligned visual representations to generate more accurate and informative captions for the egocentric video.
Critical Analysis
The paper presents a promising approach to addressing the challenges of egocentric video captioning. By incorporating information from related exocentric videos, the RAEVC model can potentially overcome the limitations of the egocentric viewpoint and provide more context-rich captions.
However, the paper does not discuss the potential limitations of the retrieval-based approach, such as the quality and relevance of the retrieved video clips, or the impact of errors in the cross-view alignment on the final captioning performance. Additionally, the paper does not explore the generalizability of the approach to different types of egocentric videos or the computational efficiency of the model.
Further research could investigate the robustness of the RAEVC model, its performance on more diverse egocentric video datasets, and potential ways to address the limitations identified in the paper.
Conclusion
The Retrieval-Augmented Egocentric Video Captioning (RAEVC) model proposed in this paper represents a novel approach to enhancing video captioning for egocentric videos. By leveraging external information through a retrieval-based mechanism and aligning visual representations across views, the model aims to generate more accurate and informative captions. This work highlights the potential of leveraging multimodal data to address the challenges inherent in egocentric video understanding and could have important implications for applications such as assistive technology and human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
Thanh-Dat Truong, Khoa Luu
0
0
Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the selfish view. First, we present a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
5/16/2024
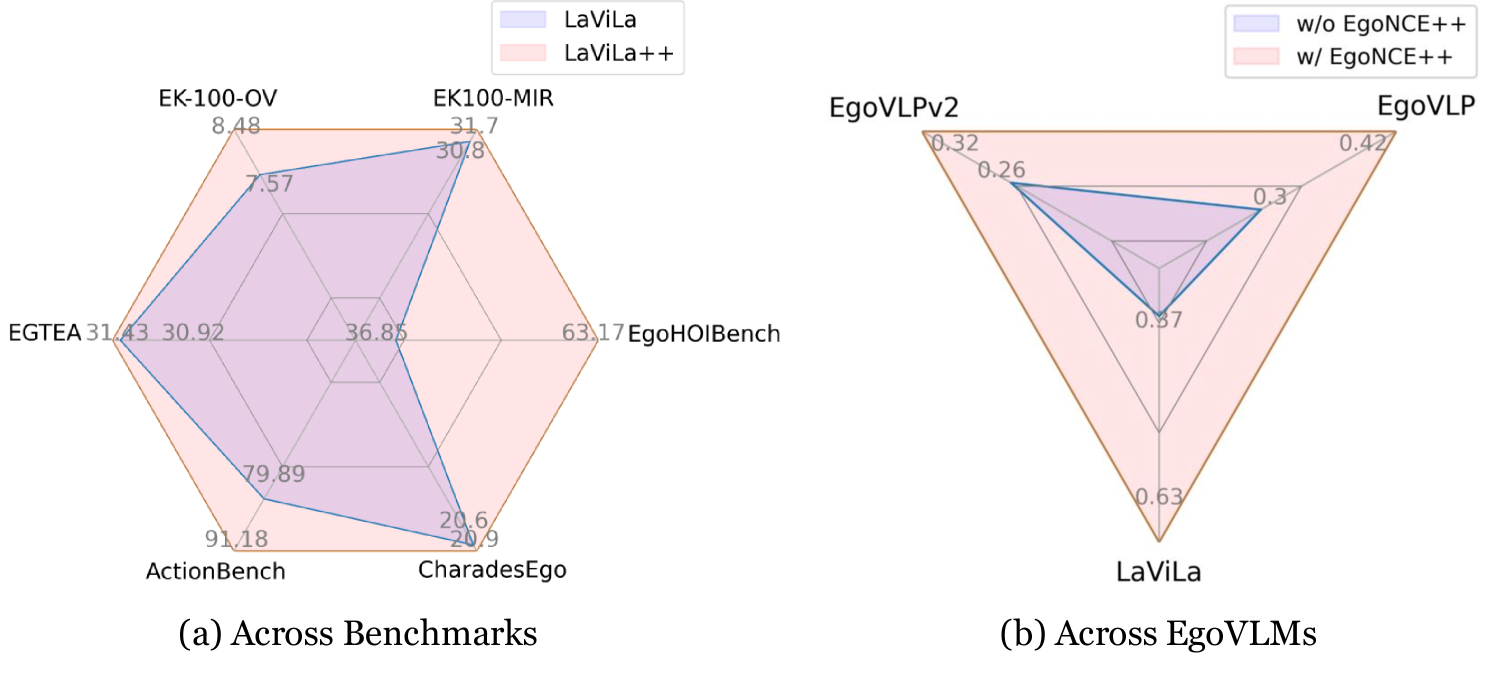
EgoNCE++: Do Egocentric Video-Language Models Really Understand Hand-Object Interactions?
Boshen Xu, Ziheng Wang, Yang Du, Zhinan Song, Sipeng Zheng, Qin Jin
0
0
Egocentric video-language pretraining is a crucial paradigm to advance the learning of egocentric hand-object interactions (EgoHOI). Despite the great success on existing testbeds, these benchmarks focus more on closed-set visual concepts or limited scenarios. Due to the occurrence of diverse EgoHOIs in the real world, we propose an open-vocabulary benchmark named EgoHOIBench to reveal the diminished performance of current egocentric video-language models (EgoVLM) on fined-grained concepts, indicating that these models still lack a full spectrum of egocentric understanding. We attribute this performance gap to insufficient fine-grained supervision and strong bias towards understanding objects rather than temporal dynamics in current methods. To tackle these issues, we introduce a novel asymmetric contrastive objective for EgoHOI named EgoNCE++. For video-to-text loss, we enhance text supervision through the generation of negative captions by leveraging the in-context learning of large language models to perform HOI-related word substitution. For text-to-video loss, we propose an object-centric positive video sampling strategy that aggregates video representations by the same nouns. Our extensive experiments demonstrate that EgoNCE++ significantly boosts open-vocabulary HOI recognition, multi-instance retrieval, and action recognition tasks across various egocentric models, with improvements of up to +26.55%. Our code is available at https://github.com/xuboshen/EgoNCEpp.
6/4/2024
🏷️
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
0
0
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
5/16/2024

AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Alessandro Suglia, Claudio Greco, Katie Baker, Jose L. Part, Ioannis Papaioannou, Arash Eshghi, Ioannis Konstas, Oliver Lemon
0
0
AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI.
6/24/2024