Cross-view Action Recognition Understanding From Exocentric to Egocentric Perspective
2305.15699
0
0
👁️
Abstract
Understanding action recognition in egocentric videos has emerged as a vital research topic with numerous practical applications. With the limitation in the scale of egocentric data collection, learning robust deep learning-based action recognition models remains difficult. Transferring knowledge learned from the large-scale exocentric data to the egocentric data is challenging due to the difference in videos across views. Our work introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from the exocentric to the selfish view. First, we present a novel geometric-based constraint into the self-attention mechanism in Transformer based on analyzing the camera positions between two views. Then, we propose a new cross-view self-attention loss learned on unpaired cross-view data to enforce the self-attention mechanism learning to transfer knowledge across views. Finally, to further improve the performance of our cross-view learning approach, we present the metrics to measure the correlations in videos and attention maps effectively. Experimental results on standard egocentric action recognition benchmarks, i.e., Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100, have shown our approach's effectiveness and state-of-the-art performance.
Create account to get full access
Overview
- This paper introduces a novel cross-view learning approach to action recognition (CVAR) that effectively transfers knowledge from exocentric (third-person) to egocentric (first-person) video data.
- The key innovations include a geometric-based constraint in the Transformer self-attention mechanism and a cross-view self-attention loss to enable knowledge transfer across views.
- Experiments on standard egocentric action recognition benchmarks show the effectiveness and state-of-the-art performance of the proposed CVAR approach.
Plain English Explanation
Understanding human actions in first-person or "egocentric" videos has become an important research area with many practical applications, such as augmented reality and video summarization. However, collecting large-scale egocentric video datasets is challenging, making it difficult to train robust deep learning models for action recognition.
To address this, the researchers propose a novel approach that learns from more abundant third-person or "exocentric" video data and transfers that knowledge to the egocentric domain. This is done by incorporating a geometric-based constraint into the Transformer's self-attention mechanism, which helps the model better understand the differences in camera viewpoints between the two domains. Additionally, they introduce a new cross-view self-attention loss that further encourages the model to learn features that can effectively transfer across views.
By leveraging these innovations, the researchers demonstrate state-of-the-art performance on standard egocentric action recognition benchmarks, such as Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100. This research highlights the potential of cross-view learning to overcome the data scarcity challenge in the egocentric action recognition domain.
Technical Explanation
The paper introduces a novel Cross-View Action Recognition (CVAR) approach that effectively transfers knowledge from exocentric to egocentric video data for action recognition. The key technical contributions are:
-
Geometric-based Constraint in Transformer Self-Attention: The researchers analyze the differences in camera positions between the exocentric and egocentric views and incorporate this geometric information into the self-attention mechanism of the Transformer model. This helps the model better understand the spatial relationships between the two viewpoints.
-
Cross-View Self-Attention Loss: The authors propose a new cross-view self-attention loss that is learned on unpaired cross-view data. This loss function encourages the self-attention mechanism to learn features that can be effectively transferred across the exocentric and egocentric domains.
-
Cross-View Video and Attention Map Correlation Metrics: To further improve the performance of the cross-view learning approach, the researchers present new metrics to measure the correlations between the videos and attention maps across the two views. These metrics are used to guide the training process and enhance the transfer of knowledge.
The researchers evaluate their CVAR approach on standard egocentric action recognition benchmarks, including Charades-Ego, EPIC-Kitchens-55, and EPIC-Kitchens-100. The experimental results demonstrate the effectiveness of their approach and its state-of-the-art performance compared to other methods.
Critical Analysis
The proposed CVAR approach addresses an important challenge in the field of egocentric action recognition by leveraging the abundant exocentric video data to improve model performance. The incorporation of geometric constraints and the cross-view self-attention loss are novel and well-justified contributions that help bridge the gap between the two video domains.
However, the paper does not discuss the potential limitations of the approach, such as the reliance on the availability of exocentric data that matches the egocentric data in terms of actions and contexts. It would be valuable to understand the scenarios where the cross-view learning approach may not be as effective, and how the researchers plan to address these limitations in future work.
Additionally, the paper could have explored the interpretability and explainability of the learned cross-view features, which could provide valuable insights into the underlying mechanisms of the knowledge transfer process. Incorporating explainability techniques could further enhance the understanding and trustworthiness of the CVAR approach.
Overall, the paper presents a promising direction for addressing the data scarcity challenge in egocentric action recognition, and the proposed CVAR approach demonstrates strong performance on benchmark datasets. Further research investigating the limitations and exploring the interpretability of the cross-view learning process could further strengthen the contributions of this work.
Conclusion
This paper introduces a novel Cross-View Action Recognition (CVAR) approach that effectively transfers knowledge from exocentric to egocentric video data for action recognition. The key innovations include a geometric-based constraint in the Transformer self-attention mechanism and a cross-view self-attention loss to enable knowledge transfer across views.
The experimental results on standard egocentric action recognition benchmarks show the effectiveness and state-of-the-art performance of the CVAR approach, highlighting its potential to overcome the data scarcity challenge in the egocentric domain. This research demonstrates the value of cross-view learning techniques in advancing action recognition capabilities, with applications in areas like augmented reality, video summarization, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Retrieval-Augmented Egocentric Video Captioning
Jilan Xu, Yifei Huang, Junlin Hou, Guo Chen, Yuejie Zhang, Rui Feng, Weidi Xie
0
0
Understanding human actions from videos of first-person view poses significant challenges. Most prior approaches explore representation learning on egocentric videos only, while overlooking the potential benefit of exploiting existing large-scale third-person videos. In this paper, (1) we develop EgoInstructor, a retrieval-augmented multimodal captioning model that automatically retrieves semantically relevant third-person instructional videos to enhance the video captioning of egocentric videos. (2) For training the cross-view retrieval module, we devise an automatic pipeline to discover ego-exo video pairs from distinct large-scale egocentric and exocentric datasets. (3) We train the cross-view retrieval module with a novel EgoExoNCE loss that pulls egocentric and exocentric video features closer by aligning them to shared text features that describe similar actions. (4) Through extensive experiments, our cross-view retrieval module demonstrates superior performance across seven benchmarks. Regarding egocentric video captioning, EgoInstructor exhibits significant improvements by leveraging third-person videos as references. Project page is available at: https://jazzcharles.github.io/Egoinstructor/
6/21/2024
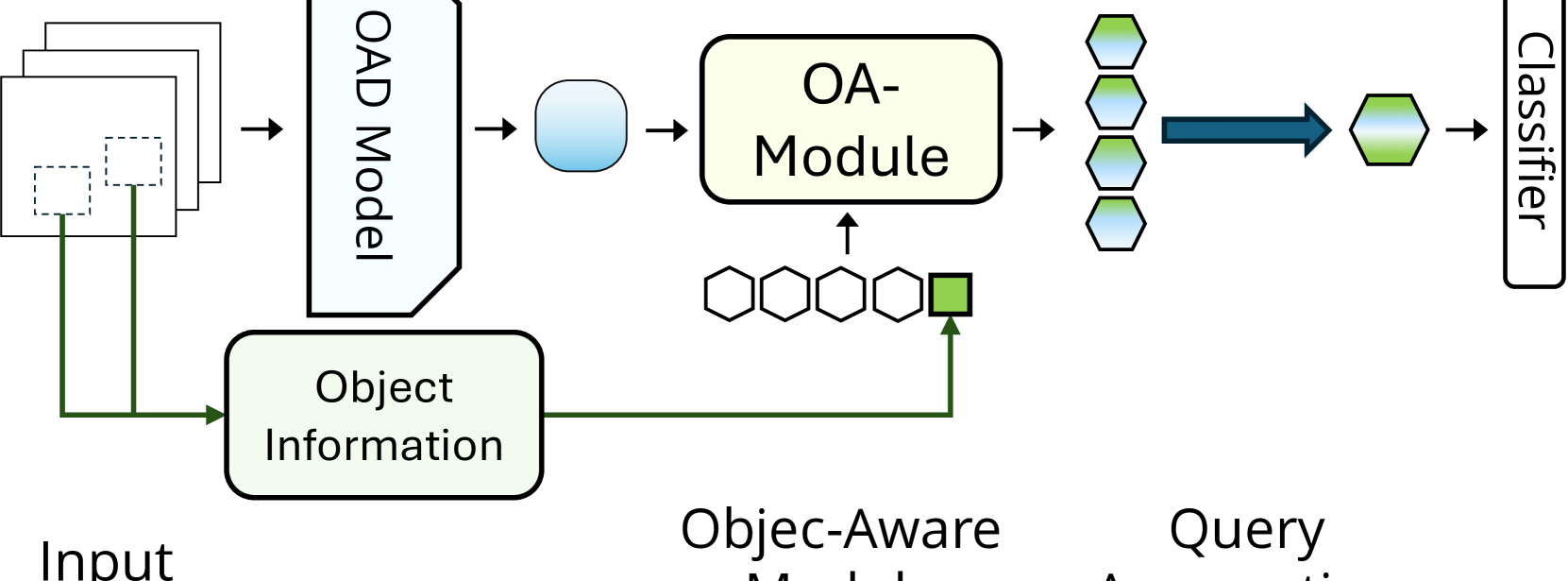
Object Aware Egocentric Online Action Detection
Joungbin An, Yunsu Park, Hyolim Kang, Seon Joo Kim
0
0
Advancements in egocentric video datasets like Ego4D, EPIC-Kitchens, and Ego-Exo4D have enriched the study of first-person human interactions, which is crucial for applications in augmented reality and assisted living. Despite these advancements, current Online Action Detection methods, which efficiently detect actions in streaming videos, are predominantly designed for exocentric views and thus fail to capitalize on the unique perspectives inherent to egocentric videos. To address this gap, we introduce an Object-Aware Module that integrates egocentric-specific priors into existing OAD frameworks, enhancing first-person footage interpretation. Utilizing object-specific details and temporal dynamics, our module improves scene understanding in detecting actions. Validated extensively on the Epic-Kitchens 100 dataset, our work can be seamlessly integrated into existing models with minimal overhead and bring consistent performance enhancements, marking an important step forward in adapting action detection systems to egocentric video analysis.
6/4/2024
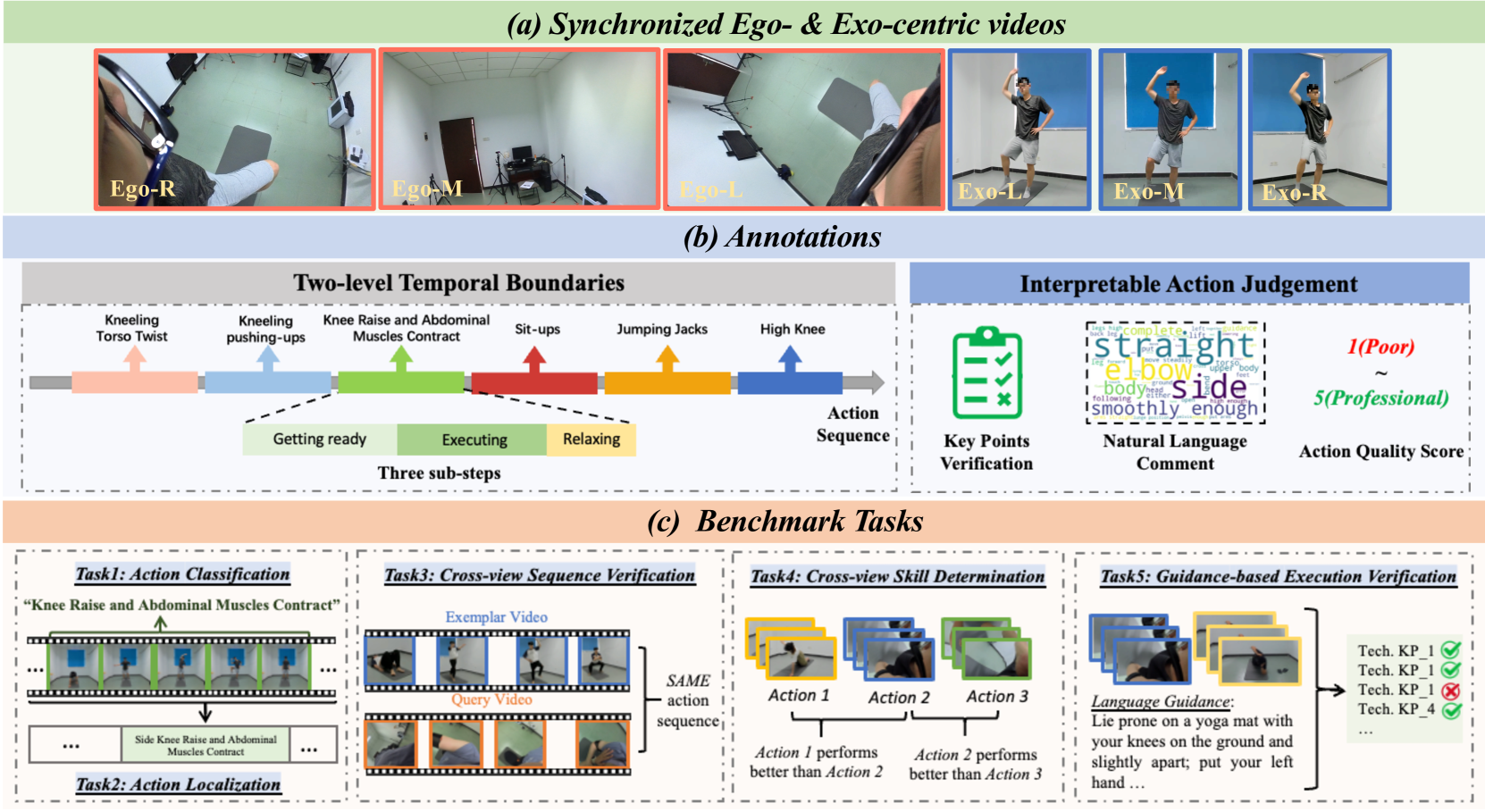
EgoExo-Fitness: Towards Egocentric and Exocentric Full-Body Action Understanding
Yuan-Ming Li, Wei-Jin Huang, An-Lan Wang, Ling-An Zeng, Jing-Ke Meng, Wei-Shi Zheng
0
0
We present EgoExo-Fitness, a new full-body action understanding dataset, featuring fitness sequence videos recorded from synchronized egocentric and fixed exocentric (third-person) cameras. Compared with existing full-body action understanding datasets, EgoExo-Fitness not only contains videos from first-person perspectives, but also provides rich annotations. Specifically, two-level temporal boundaries are provided to localize single action videos along with sub-steps of each action. More importantly, EgoExo-Fitness introduces innovative annotations for interpretable action judgement--including technical keypoint verification, natural language comments on action execution, and action quality scores. Combining all of these, EgoExo-Fitness provides new resources to study egocentric and exocentric full-body action understanding across dimensions of what, when, and how well. To facilitate research on egocentric and exocentric full-body action understanding, we construct benchmarks on a suite of tasks (i.e., action classification, action localization, cross-view sequence verification, cross-view skill determination, and a newly proposed task of guidance-based execution verification), together with detailed analysis. Code and data will be available at https://github.com/iSEE-Laboratory/EgoExo-Fitness/tree/main.
6/14/2024
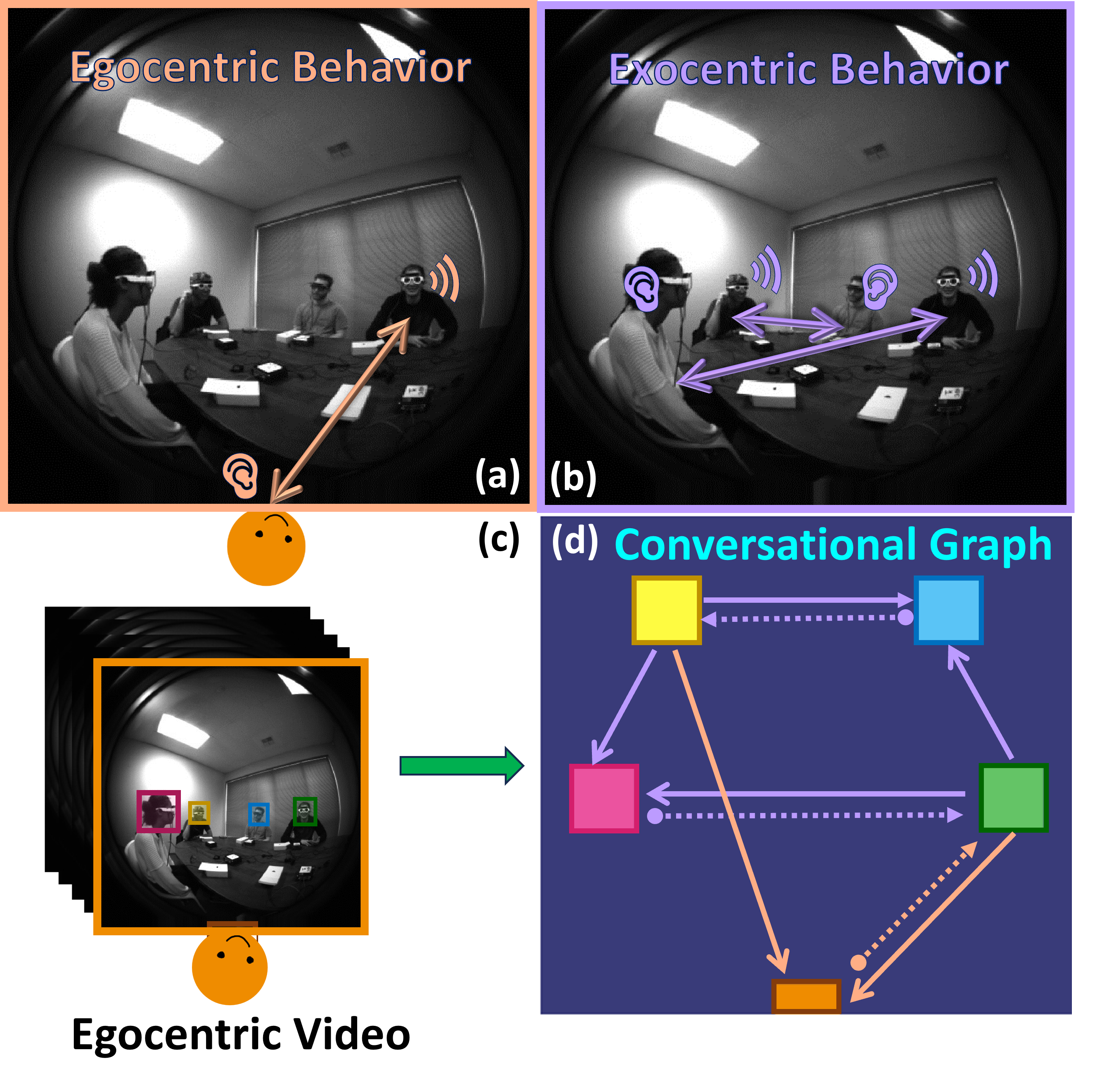
The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Wenqi Jia, Miao Liu, Hao Jiang, Ishwarya Ananthabhotla, James M. Rehg, Vamsi Krishna Ithapu, Ruohan Gao
0
0
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal framework -- Audio-Visual Conversational Attention (AV-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we adopt the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes multi-speaker and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Check our project page at https://vjwq.github.io/AV-CONV/.
4/4/2024