Learning Spatial Features from Audio-Visual Correspondence in Egocentric Videos
2307.04760
0
0

Abstract
We propose a self-supervised method for learning representations based on spatial audio-visual correspondences in egocentric videos. Our method uses a masked auto-encoding framework to synthesize masked binaural (multi-channel) audio through the synergy of audio and vision, thereby learning useful spatial relationships between the two modalities. We use our pretrained features to tackle two downstream video tasks requiring spatial understanding in social scenarios: active speaker detection and spatial audio denoising. Through extensive experiments, we show that our features are generic enough to improve over multiple state-of-the-art baselines on both tasks on two challenging egocentric video datasets that offer binaural audio, EgoCom and EasyCom. Project: http://vision.cs.utexas.edu/projects/ego_av_corr.
Create account to get full access
Overview
- This paper presents a novel approach to learning spatial features from the correspondence between audio and visual cues in egocentric videos.
- The proposed method leverages the inherent synchronization between sound and visual events to learn a robust representation of the spatial layout of the environment.
- This research builds upon previous work on audio-visual correspondence in egocentric videos and learning how actions sound.
Plain English Explanation
When we watch videos from a first-person perspective (like those captured by a camera on someone's head), the sounds and visual cues are naturally synchronized. For example, if someone is walking, the sound of their footsteps will match up with the movement of their legs in the video. The researchers in this paper found a way to use this connection between sound and vision to learn about the spatial layout of the environment.
By training a machine learning model to recognize the relationships between audio and visual features in the egocentric videos, the researchers were able to extract information about the 3D structure of the scene. This could be useful for applications like text-guided visual sound source localization or unified audio-visual perception.
The key insight is that the synchronization between sound and vision provides a natural "label" for learning about the spatial layout, without the need for additional human annotations. This allows the model to learn these spatial features in a more scalable and efficient way compared to other approaches that require more manual effort.
Technical Explanation
The paper proposes a novel self-supervised learning framework to extract spatial features from egocentric videos by exploiting the audio-visual correspondence. The core idea is to leverage the inherent synchronization between sound and visual events to learn a robust representation of the 3D spatial layout of the environment.
The proposed method consists of two main components:
- Audio-Visual Encoder: This module takes in the video and audio streams and learns a joint embedding that captures the correspondence between the two modalities.
- Spatial Prediction Head: This component uses the learned audio-visual features to predict the 3D spatial location of objects and surfaces in the scene.
The training process involves minimizing a contrastive loss that encourages the model to associate the correct audio-visual pairs while pushing apart unrelated ones. This allows the audio-visual encoder to learn meaningful correspondences between the two modalities.
The learned spatial features were evaluated on various downstream tasks, including video object segmentation and depth estimation, demonstrating the effectiveness of the approach in capturing the 3D structure of the environment.
Critical Analysis
The paper presents a compelling approach to leveraging audio-visual correspondence for learning spatial features in egocentric videos. The key strength of the method is its ability to learn these spatial representations in a self-supervised manner, without the need for manual 3D annotations or complex sensor setups.
However, the paper does mention some limitations of the current approach. For instance, the model may struggle to generalize to scenarios with significant audio-visual asynchrony, such as videos with heavy editing or post-production. Additionally, the spatial prediction accuracy could be further improved by incorporating more advanced architectural designs or incorporating additional cues (e.g., object segmentation, motion patterns).
An interesting direction for future research would be to explore how the learned spatial features could be used to enable multimodal perception for tasks like audio-visual event localization or action recognition. Integrating the spatial understanding with other modalities could lead to more holistic and robust scene understanding capabilities.
Conclusion
This paper presents a novel self-supervised approach to learning spatial features from the audio-visual correspondence in egocentric videos. By exploiting the inherent synchronization between sound and vision, the proposed method can extract a robust representation of the 3D spatial layout without the need for manual annotations.
The learned spatial features have shown promising results on various downstream tasks, highlighting their potential to enable more advanced multimodal perception capabilities. While the current approach has some limitations, the research demonstrates the value of leveraging audio-visual cues for scene understanding, opening up exciting avenues for future work in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
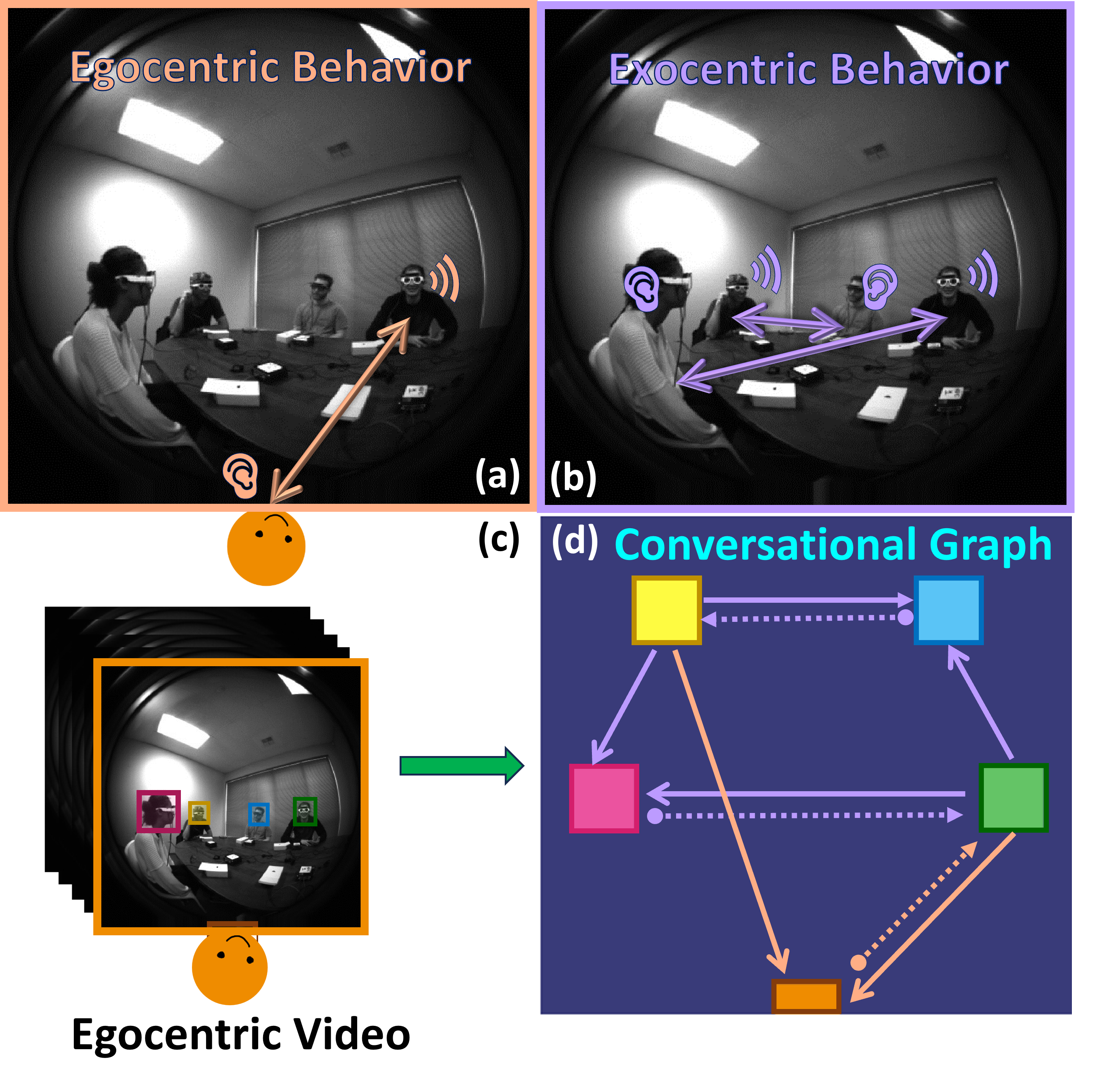
The Audio-Visual Conversational Graph: From an Egocentric-Exocentric Perspective
Wenqi Jia, Miao Liu, Hao Jiang, Ishwarya Ananthabhotla, James M. Rehg, Vamsi Krishna Ithapu, Ruohan Gao
0
0
In recent years, the thriving development of research related to egocentric videos has provided a unique perspective for the study of conversational interactions, where both visual and audio signals play a crucial role. While most prior work focus on learning about behaviors that directly involve the camera wearer, we introduce the Ego-Exocentric Conversational Graph Prediction problem, marking the first attempt to infer exocentric conversational interactions from egocentric videos. We propose a unified multi-modal framework -- Audio-Visual Conversational Attention (AV-CONV), for the joint prediction of conversation behaviors -- speaking and listening -- for both the camera wearer as well as all other social partners present in the egocentric video. Specifically, we adopt the self-attention mechanism to model the representations across-time, across-subjects, and across-modalities. To validate our method, we conduct experiments on a challenging egocentric video dataset that includes multi-speaker and multi-conversation scenarios. Our results demonstrate the superior performance of our method compared to a series of baselines. We also present detailed ablation studies to assess the contribution of each component in our model. Check our project page at https://vjwq.github.io/AV-CONV/.
4/4/2024
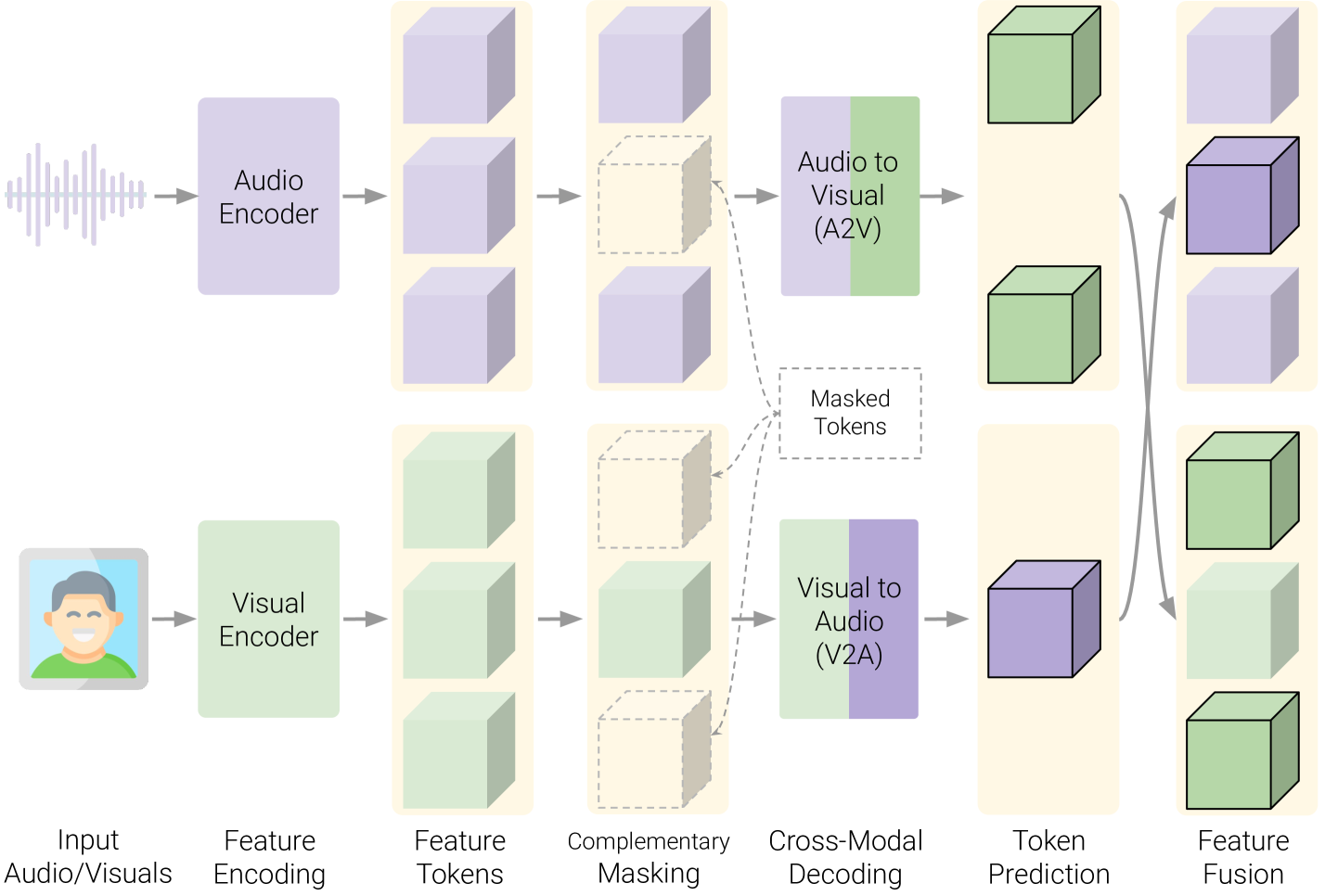
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024
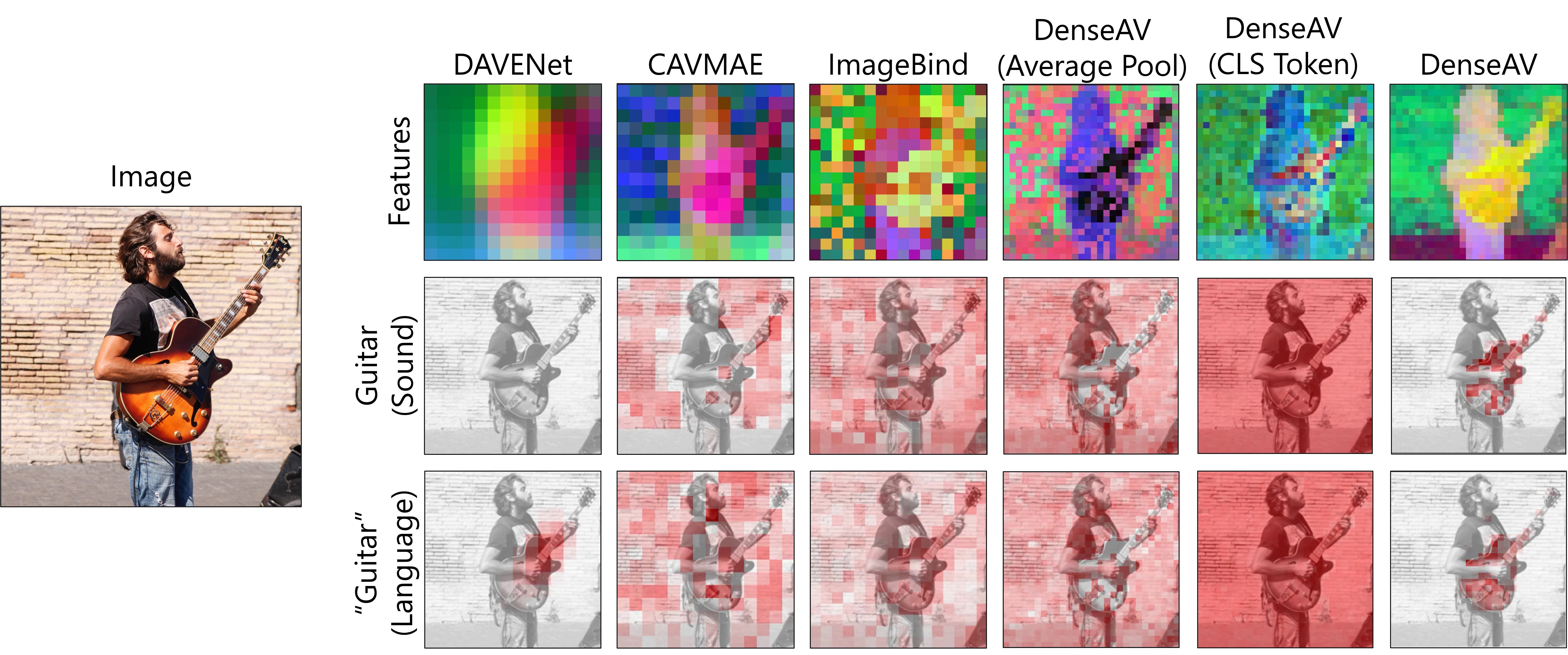
Separating the Chirp from the Chat: Self-supervised Visual Grounding of Sound and Language
Mark Hamilton, Andrew Zisserman, John R. Hershey, William T. Freeman
0
0
We present DenseAV, a novel dual encoder grounding architecture that learns high-resolution, semantically meaningful, and audio-visually aligned features solely through watching videos. We show that DenseAV can discover the ``meaning'' of words and the ``location'' of sounds without explicit localization supervision. Furthermore, it automatically discovers and distinguishes between these two types of associations without supervision. We show that DenseAV's localization abilities arise from a new multi-head feature aggregation operator that directly compares dense image and audio representations for contrastive learning. In contrast, many other systems that learn ``global'' audio and video representations cannot localize words and sound. Finally, we contribute two new datasets to improve the evaluation of AV representations through speech and sound prompted semantic segmentation. On these and other datasets we show DenseAV dramatically outperforms the prior art on speech and sound prompted semantic segmentation. DenseAV outperforms the previous state-of-the-art, ImageBind, on cross-modal retrieval using fewer than half of the parameters. Project Page: href{https://aka.ms/denseav}{https://aka.ms/denseav}
6/11/2024
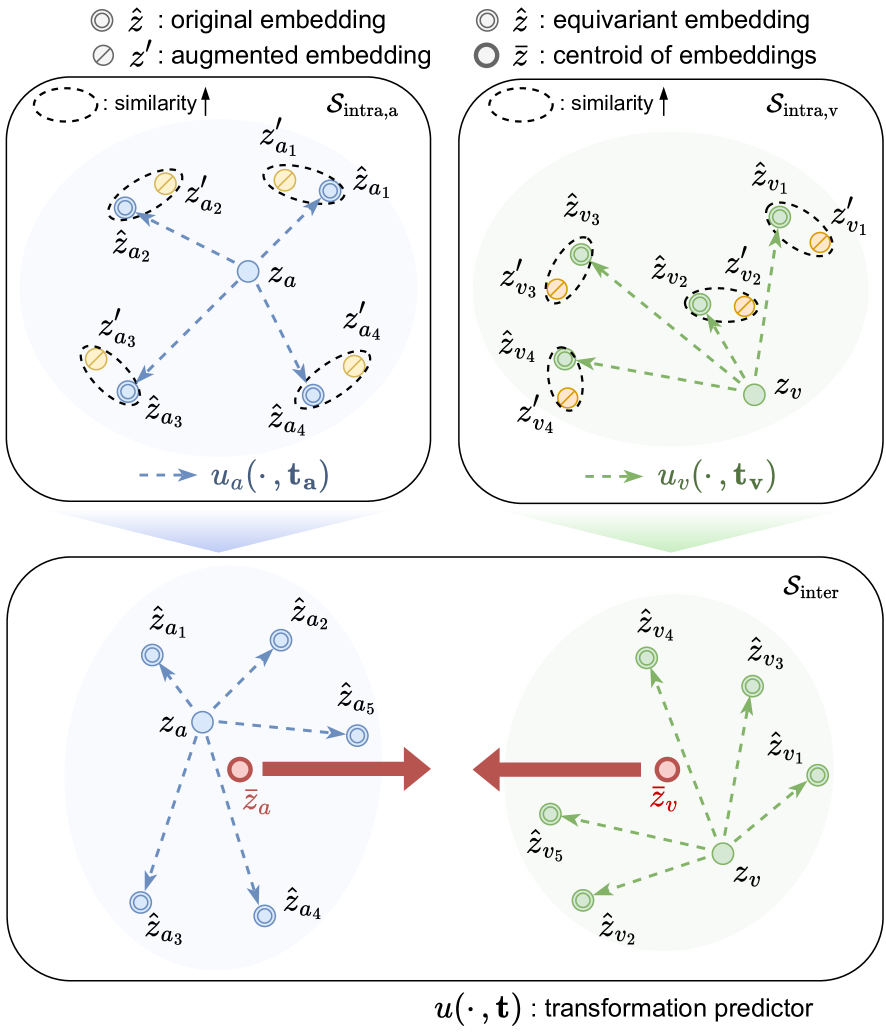
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Jongsuk Kim, Hyeongkeun Lee, Kyeongha Rho, Junmo Kim, Joon Son Chung
0
0
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
6/21/2024