Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
2403.04654
0
0

Abstract
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
Create account to get full access
Overview
- This paper proposes a novel audio-visual person verification system that utilizes recursive fusion of joint cross-attention between audio and visual modalities.
- The key innovations include a dynamic cross-attention mechanism, a multi-layer cross-attention fusion approach, and a recursive joint cross-modal attention fusion strategy.
- The system is designed to effectively leverage the complementary information in audio and visual cues for robust person verification.
Plain English Explanation
This research paper describes a new system for verifying a person's identity using a combination of audio (voice) and visual (face) information. The key idea is to have the audio and visual components of the system pay attention to each other in a recursive, or repeating, manner.
Specifically, the system first extracts features from the audio (voice) and visual (face) inputs. It then uses a "dynamic cross-attention" mechanism to have the audio and visual components focus on the relevant parts of each other's information. This allows the system to combine the audio and visual cues in an intelligent way.
The researchers also use a "multi-layer cross-attention fusion" approach, which means they apply this cross-attention process multiple times, at different levels of the system. This helps the audio and visual information to be integrated more thoroughly.
Finally, the system employs a "recursive joint cross-modal attention" strategy. This means the cross-attention process is repeated multiple times, allowing the audio and visual information to influence each other back and forth. This recursive approach helps the system arrive at a more robust and reliable person verification decision.
The key advantage of this system is that it can leverage the complementary strengths of audio and visual cues to achieve more accurate person verification, compared to using just audio or just visual information alone.
Technical Explanation
The proposed audio-visual person verification system consists of several key components:
-
Feature Extraction: The system separately extracts audio and visual features from the input signals using pre-trained neural networks.
-
Dynamic Cross-Attention: A dynamic cross-attention mechanism is used to allow the audio and visual feature representations to attend to each other, capturing the complementary information between the modalities.
-
Multi-Layer Cross-Attention Fusion: The cross-attention process is applied at multiple layers of the network, enabling a more comprehensive integration of audio-visual cues.
-
Recursive Joint Cross-Modal Attention: The cross-attention mechanism is applied recursively, allowing the audio and visual features to influence each other in an iterative manner, leading to more robust multimodal fusion.
-
Classification: The fused audio-visual representation is passed through a final classification layer to output the person verification decision.
The innovations in this work, such as the dynamic cross-attention, multi-layer fusion, and recursive joint cross-modal attention, enable the system to effectively leverage the complementary strengths of audio and visual modalities. This results in improved person verification performance compared to previous approaches that treat the modalities independently or use simpler fusion techniques.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed audio-visual person verification system. The researchers compare their approach to several baselines and state-of-the-art methods, demonstrating significant performance improvements.
However, the paper does not discuss potential limitations or failure cases of the system. For example, it would be interesting to understand how the system might perform in noisy environments or with low-quality audio/visual inputs. Additionally, the computational complexity and inference time of the recursive cross-attention mechanism could be further analyzed.
While the paper provides a strong technical contribution, there are opportunities to explore the societal implications and ethical considerations of such person verification systems, especially in the context of privacy and surveillance. Addressing these aspects could further strengthen the overall impact of the research.
Conclusion
This paper introduces an innovative audio-visual person verification system that leverages the complementary strengths of audio and visual modalities through a recursive fusion of joint cross-attention. The key technical innovations, including dynamic cross-attention, multi-layer fusion, and recursive joint cross-modal attention, enable the system to achieve state-of-the-art performance on person verification tasks.
The proposed approach represents a significant advancement in multimodal fusion techniques and has the potential to impact various applications, such as biometric authentication, surveillance, and human-computer interaction. As the field of multimodal learning continues to evolve, this research contributes valuable insights and lays the groundwork for further exploration of robust and efficient audio-visual fusion strategies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
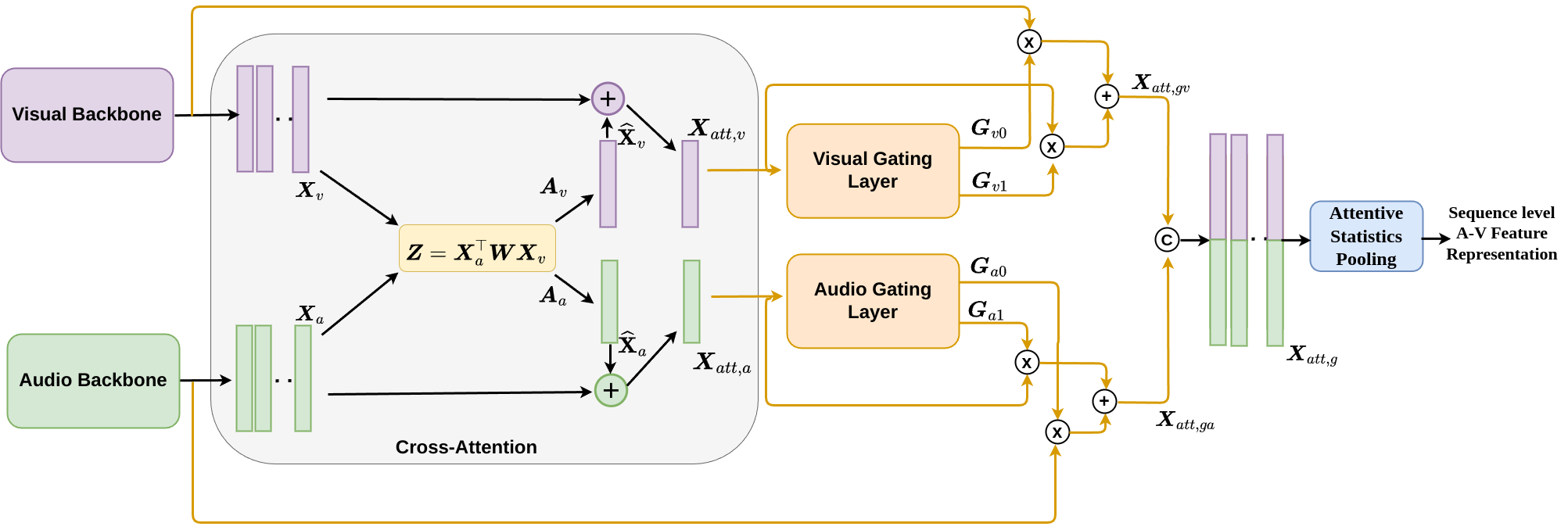
Dynamic Cross Attention for Audio-Visual Person Verification
R. Gnana Praveen, Jahangir Alam
0
0
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
4/23/2024
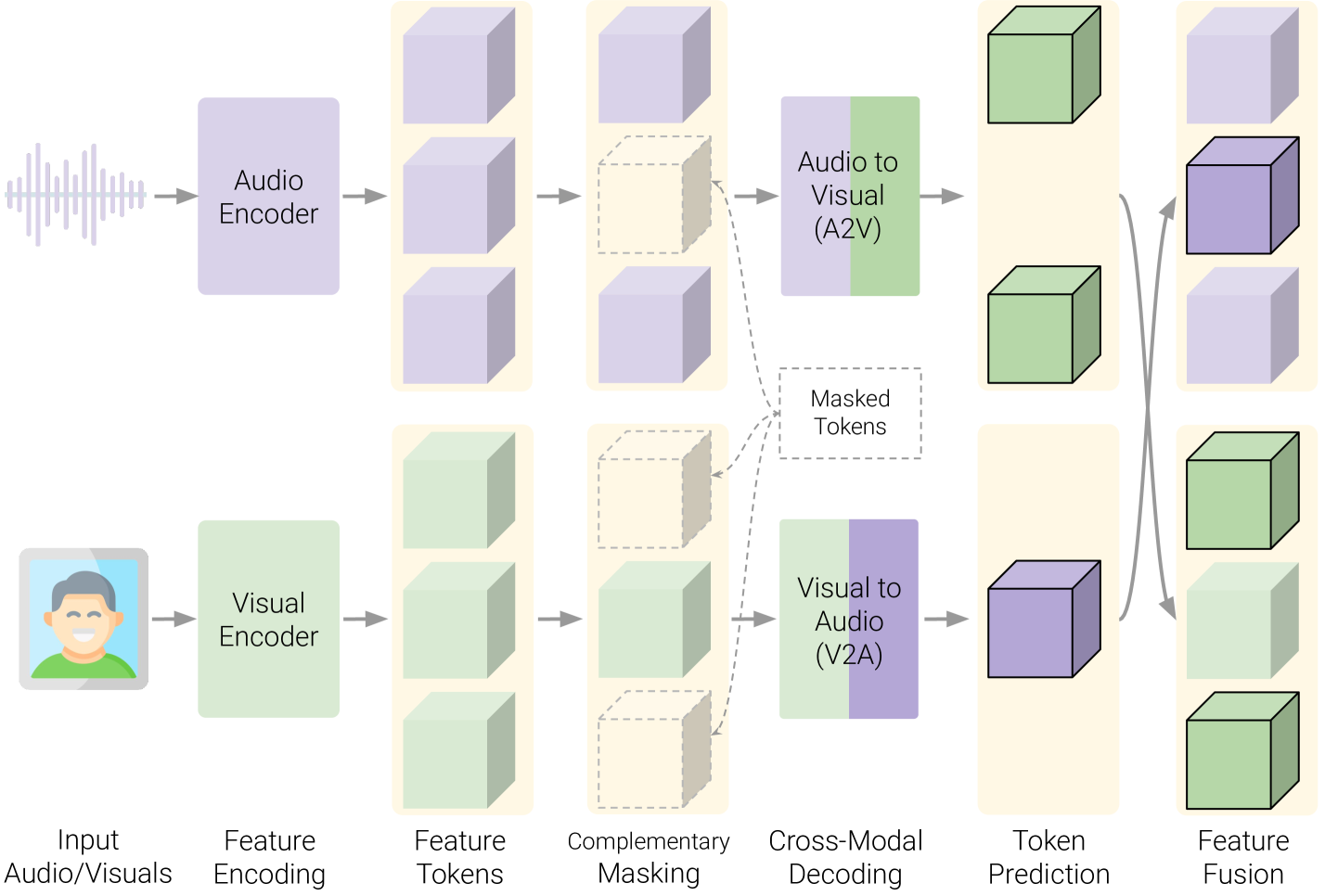
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024

MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition
He Wang, Pengcheng Guo, Pan Zhou, Lei Xie
0
0
While automatic speech recognition (ASR) systems degrade significantly in noisy environments, audio-visual speech recognition (AVSR) systems aim to complement the audio stream with noise-invariant visual cues and improve the system's robustness. However, current studies mainly focus on fusing the well-learned modality features, like the output of modality-specific encoders, without considering the contextual relationship during the modality feature learning. In this study, we propose a multi-layer cross-attention fusion based AVSR (MLCA-AVSR) approach that promotes representation learning of each modality by fusing them at different levels of audio/visual encoders. Experimental results on the MISP2022-AVSR Challenge dataset show the efficacy of our proposed system, achieving a concatenated minimum permutation character error rate (cpCER) of 30.57% on the Eval set and yielding up to 3.17% relative improvement compared with our previous system which ranked the second place in the challenge. Following the fusion of multiple systems, our proposed approach surpasses the first-place system, establishing a new SOTA cpCER of 29.13% on this dataset.
4/9/2024
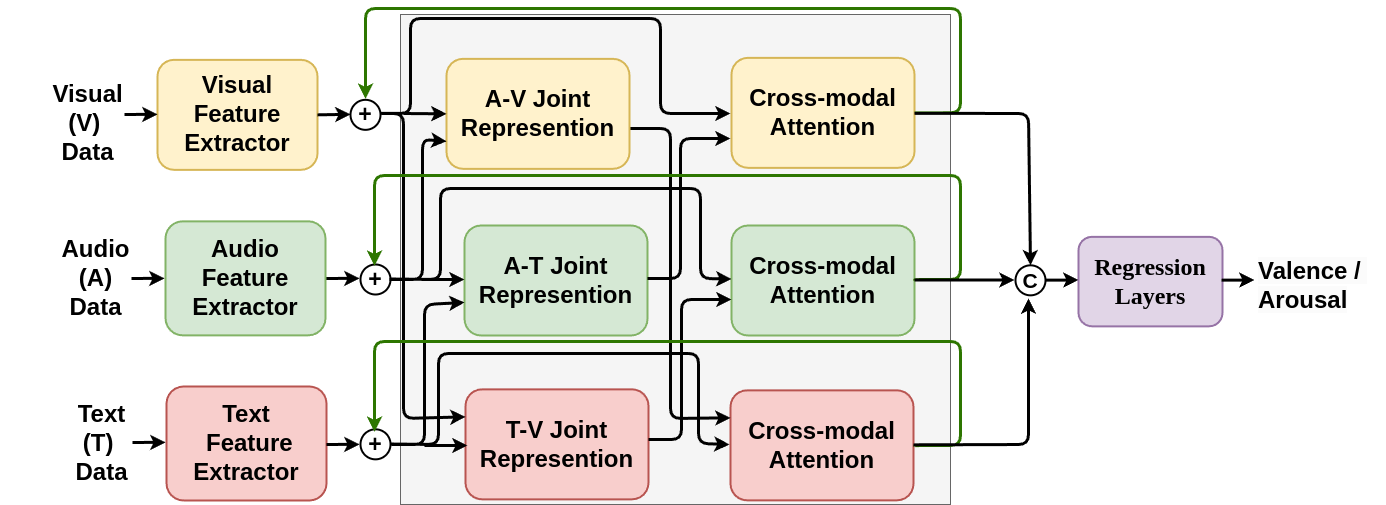
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024