Dynamic Cross Attention for Audio-Visual Person Verification
2403.04661
0
0
Abstract
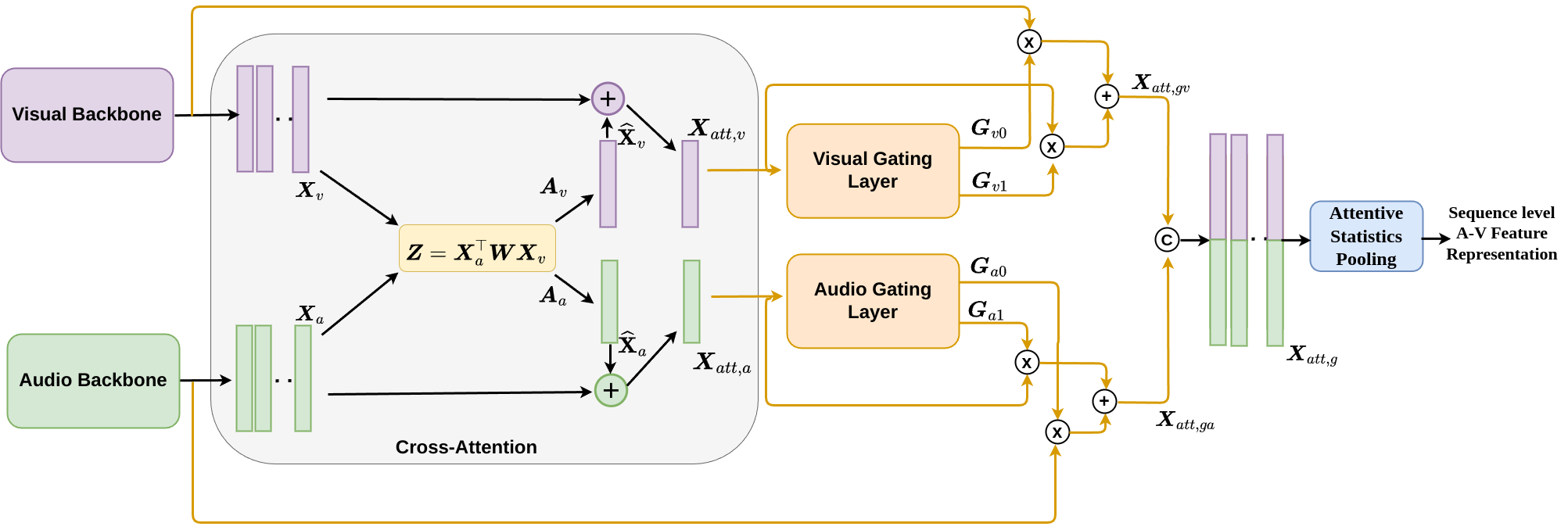
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
Create account to get full access
Overview
- The paper proposes a dynamic cross-attention mechanism for audio-visual person verification, which aims to improve the performance of biometric authentication systems that use both audio and visual inputs.
- The approach dynamically attends to relevant parts of the audio and visual signals to improve the fusion of these modalities.
- Experiments on standard benchmarks show the proposed method outperforms previous audio-visual fusion techniques.
Plain English Explanation
The paper introduces a new way to combine audio and visual information for the task of person verification. In biometric authentication systems, you might use a combination of voice and face recognition to confirm a person's identity. However, simply taking the audio and video signals and combining them doesn't always work well.
The Dynamic Cross Attention for Audio-Visual Person Verification method aims to solve this by dynamically focusing on the most relevant parts of the audio and visual inputs. It learns to pay attention to the specific aspects of the voice and face that are most useful for verifying the person's identity.
This is like how a person might focus on certain features of your face and voice when trying to recognize you, rather than just considering everything at once. The model adaptively combines the audio and visual information in a smart way, leading to better performance on standard person verification benchmarks compared to previous approaches.
Technical Explanation
The proposed method uses a neural network architecture with two main components: audio and visual feature extractors, followed by a dynamic cross-attention module.
The audio and visual features are first computed independently using pre-trained models. Then, the dynamic cross-attention mechanism learns to selectively attend to the most relevant parts of the audio and visual inputs for the person verification task.
This is done by computing attention weights that indicate which parts of the audio and visual features should be emphasized when combining the modalities. The attention weights are dynamically generated based on the current audio and visual inputs, rather than being static.
The final verification score is obtained by passing the attended audio and visual features through additional neural network layers.
Experiments on standard benchmarks like VoxCeleb and YTVFace show the proposed dynamic cross-attention approach outperforms previous audio-visual fusion techniques.
Critical Analysis
The paper provides a novel and effective solution for improving audio-visual person verification by dynamically attending to the most relevant parts of the input signals. The dynamic cross-attention mechanism is a clever way to adaptively combine the audio and visual modalities.
However, the paper does not delve into the limitations of the approach or discuss potential avenues for further research. It would be interesting to see how the method performs on more challenging or diverse datasets, and whether the attention mechanism generalizes well to different types of audio-visual inputs.
Additionally, the paper could have provided more insight into the inner workings of the dynamic cross-attention module and how it differs from static attention-based fusion techniques. A deeper analysis of the attention patterns learned by the model could shed light on the specific audio and visual cues that are most discriminative for person verification.
Overall, the proposed approach is a valuable contribution to the field of audio-visual biometrics, and the dynamic cross-attention mechanism could be applicable to other multimodal learning tasks as well.
Conclusion
The Dynamic Cross Attention for Audio-Visual Person Verification paper introduces an effective method for fusing audio and visual information for the task of person verification. By dynamically attending to the most relevant parts of the input signals, the approach outperforms previous audio-visual fusion techniques on standard benchmarks.
This work demonstrates the importance of adaptively combining multimodal data, and the potential of attention mechanisms to improve the performance of biometric authentication systems. The dynamic cross-attention module could be a valuable building block for future multimodal learning applications beyond person verification as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
R. Gnana Praveen, Jahangir Alam
0
0
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
4/29/2024
👁️
Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition
G Rajasekhar, Jahangir Alam
0
0
Leveraging complementary relationships across modalities has recently drawn a lot of attention in multimodal emotion recognition. Most of the existing approaches explored cross-attention to capture the complementary relationships across the modalities. However, the modalities may also exhibit weak complementary relationships, which may deteriorate the cross-attended features, resulting in poor multimodal feature representations. To address this problem, we propose Inconsistency-Aware Cross-Attention (IACA), which can adaptively select the most relevant features on-the-fly based on the strong or weak complementary relationships across audio and visual modalities. Specifically, we design a two-stage gating mechanism that can adaptively select the appropriate relevant features to deal with weak complementary relationships. Extensive experiments are conducted on the challenging Aff-Wild2 dataset to show the robustness of the proposed model.
7/2/2024

MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition
He Wang, Pengcheng Guo, Pan Zhou, Lei Xie
0
0
While automatic speech recognition (ASR) systems degrade significantly in noisy environments, audio-visual speech recognition (AVSR) systems aim to complement the audio stream with noise-invariant visual cues and improve the system's robustness. However, current studies mainly focus on fusing the well-learned modality features, like the output of modality-specific encoders, without considering the contextual relationship during the modality feature learning. In this study, we propose a multi-layer cross-attention fusion based AVSR (MLCA-AVSR) approach that promotes representation learning of each modality by fusing them at different levels of audio/visual encoders. Experimental results on the MISP2022-AVSR Challenge dataset show the efficacy of our proposed system, achieving a concatenated minimum permutation character error rate (cpCER) of 30.57% on the Eval set and yielding up to 3.17% relative improvement compared with our previous system which ranked the second place in the challenge. Following the fusion of multiple systems, our proposed approach surpasses the first-place system, establishing a new SOTA cpCER of 29.13% on this dataset.
4/9/2024
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
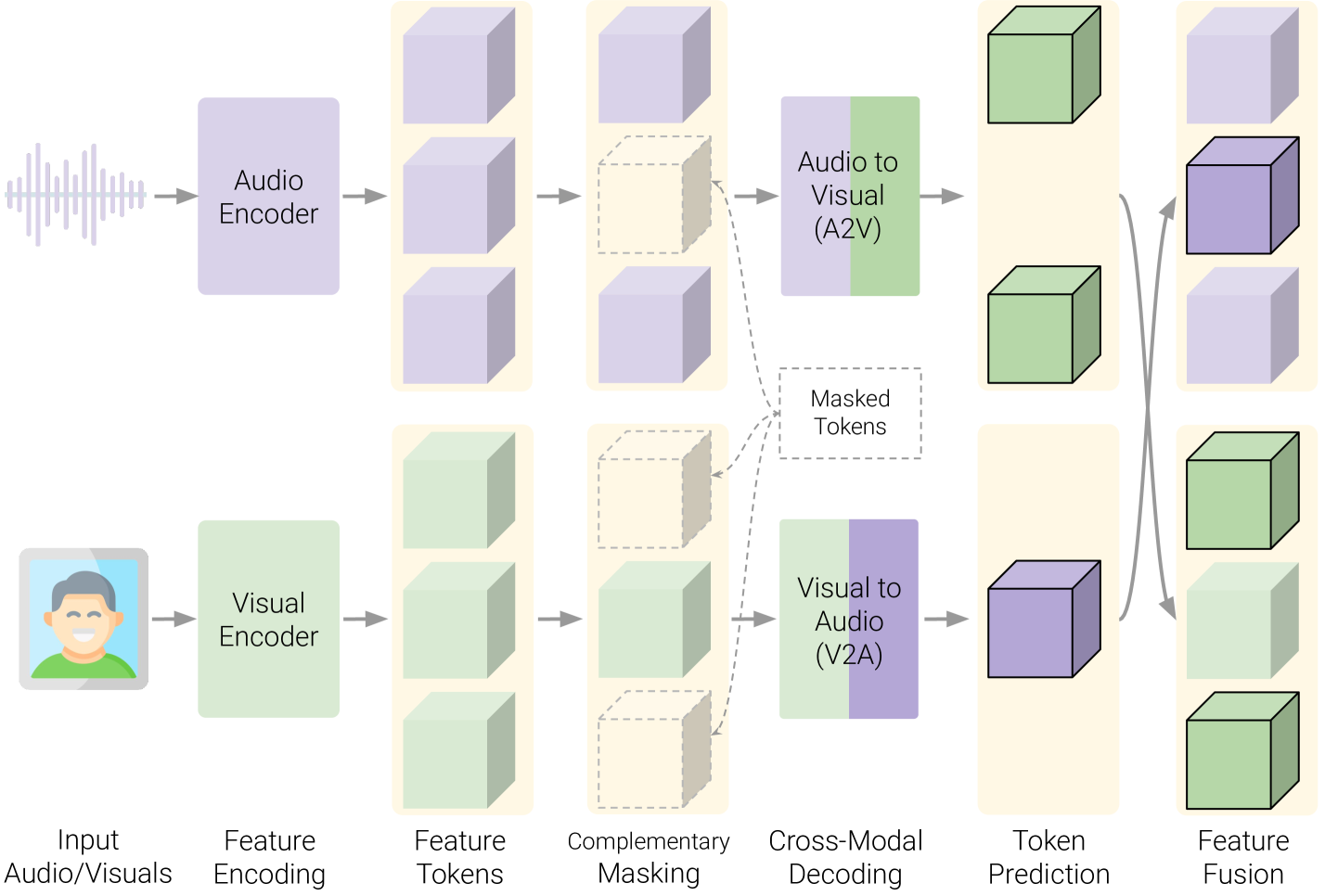
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024