Audio-Visual Speaker Diarization: Current Databases, Approaches and Challenges

0

Sign in to get full access
Overview
- Audio-visual speaker diarization is the task of identifying and tracking individual speakers in a video
- It involves multiple components like active speaker detection, audio-visual person localization, and identity assignment
- Current databases, approaches, and challenges in this domain are discussed
Plain English Explanation
Audio-visual speaker diarization is the process of identifying and tracking different speakers in a video. It involves several key steps:
- Active Speaker Detection: Determining which person in the video is currently speaking.
- Audio-Visual Person Localization: Identifying the location of each speaker in the video.
- Identity Assignment: Keeping track of which speech segments belong to which speaker throughout the video.
This technology has many potential applications, such as meeting transcription, video conferencing, and interactive virtual assistants. However, there are significant challenges in making these systems work reliably, such as dealing with background noise, overlapping speech, and changes in camera angles or speaker positions.
Technical Explanation
Audio-visual speaker diarization systems aim to automatically identify and track individual speakers in videos. This involves several key components:
- Active Speaker Detection: Determining which person in the video is currently speaking based on both audio and visual cues.
- Audio-Visual Person Localization: Identifying the spatial location of each speaker in the video frame.
- Identity Assignment: Keeping track of which speech segments belong to each unique speaker throughout the duration of the video.
Researchers have developed various approaches to tackle these challenges, including deep learning models and multi-modal fusion techniques. However, significant obstacles remain, such as dealing with background noise, overlapping speech, camera movement, and changes in speaker position over time.
Critical Analysis
The research covered in this paper highlights the significant challenges involved in building robust and reliable audio-visual speaker diarization systems. While progress has been made, there are still many open problems that require further investigation:
-
Domain Mismatch: Most existing datasets and models are trained on constrained, laboratory-like settings, but real-world scenarios can involve much more complex and variable conditions. Bridging this "domain gap" is crucial for deploying these systems in practical applications.
-
Identity Assignment: Accurately associating speech segments with the correct speaker, even when speakers move around or take turns speaking, remains a difficult problem. More advanced tracking and re-identification techniques may be needed.
-
Scalability: Current approaches may struggle to handle videos with large numbers of speakers. Developing scalable solutions that can handle real-world meeting or conference scenarios is an important area for future work.
-
Interpretability: Many of the deep learning models used in this domain are "black boxes," making it difficult to understand and debug their decision-making processes. Improving the interpretability of these models could lead to better insights and more trustworthy systems.
Overall, while audio-visual speaker diarization has seen significant progress, there are still many open challenges that require further research and innovation to overcome.
Conclusion
Audio-visual speaker diarization is a complex task that involves multiple components, including active speaker detection, audio-visual person localization, and identity assignment. While researchers have developed various approaches to tackle these challenges, significant obstacles remain, such as dealing with domain mismatch, identity assignment, scalability, and model interpretability.
Overcoming these hurdles is crucial for deploying audio-visual speaker diarization systems in practical applications, such as meeting transcription, video conferencing, and interactive virtual assistants. Continued research and innovation in this area could lead to more robust and reliable solutions that can handle the complexities of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Audio-Visual Speaker Diarization: Current Databases, Approaches and Challenges
Victoria Mingote, Alfonso Ortega, Antonio Miguel, Eduardo Lleida
Nowadays, the large amount of audio-visual content available has fostered the need to develop new robust automatic speaker diarization systems to analyse and characterise it. This kind of system helps to reduce the cost of doing this process manually and allows the use of the speaker information for different applications, as a huge quantity of information is present, for example, images of faces, or audio recordings. Therefore, this paper aims to address a critical area in the field of speaker diarization systems, the integration of audio-visual content of different domains. This paper seeks to push beyond current state-of-the-art practices by developing a robust audio-visual speaker diarization framework adaptable to various data domains, including TV scenarios, meetings, and daily activities. Unlike most of the existing audio-visual speaker diarization systems, this framework will also include the proposal of an approach to lead the precise assignment of specific identities in TV scenarios where celebrities appear. In addition, in this work, we have conducted an extensive compilation of the current state-of-the-art approaches and the existing databases for developing audio-visual speaker diarization.
Read more9/10/2024

0
Integrating Audio, Visual, and Semantic Information for Enhanced Multimodal Speaker Diarization
Luyao Cheng, Hui Wang, Siqi Zheng, Yafeng Chen, Rongjie Huang, Qinglin Zhang, Qian Chen, Xihao Li
Speaker diarization, the process of segmenting an audio stream or transcribed speech content into homogenous partitions based on speaker identity, plays a crucial role in the interpretation and analysis of human speech. Most existing speaker diarization systems rely exclusively on unimodal acoustic information, making the task particularly challenging due to the innate ambiguities of audio signals. Recent studies have made tremendous efforts towards audio-visual or audio-semantic modeling to enhance performance. However, even the incorporation of up to two modalities often falls short in addressing the complexities of spontaneous and unstructured conversations. To exploit more meaningful dialogue patterns, we propose a novel multimodal approach that jointly utilizes audio, visual, and semantic cues to enhance speaker diarization. Our method elegantly formulates the multimodal modeling as a constrained optimization problem. First, we build insights into the visual connections among active speakers and the semantic interactions within spoken content, thereby establishing abundant pairwise constraints. Then we introduce a joint pairwise constraint propagation algorithm to cluster speakers based on these visual and semantic constraints. This integration effectively leverages the complementary strengths of different modalities, refining the affinity estimation between individual speaker embeddings. Extensive experiments conducted on multiple multimodal datasets demonstrate that our approach consistently outperforms state-of-the-art speaker diarization methods.
Read more8/23/2024
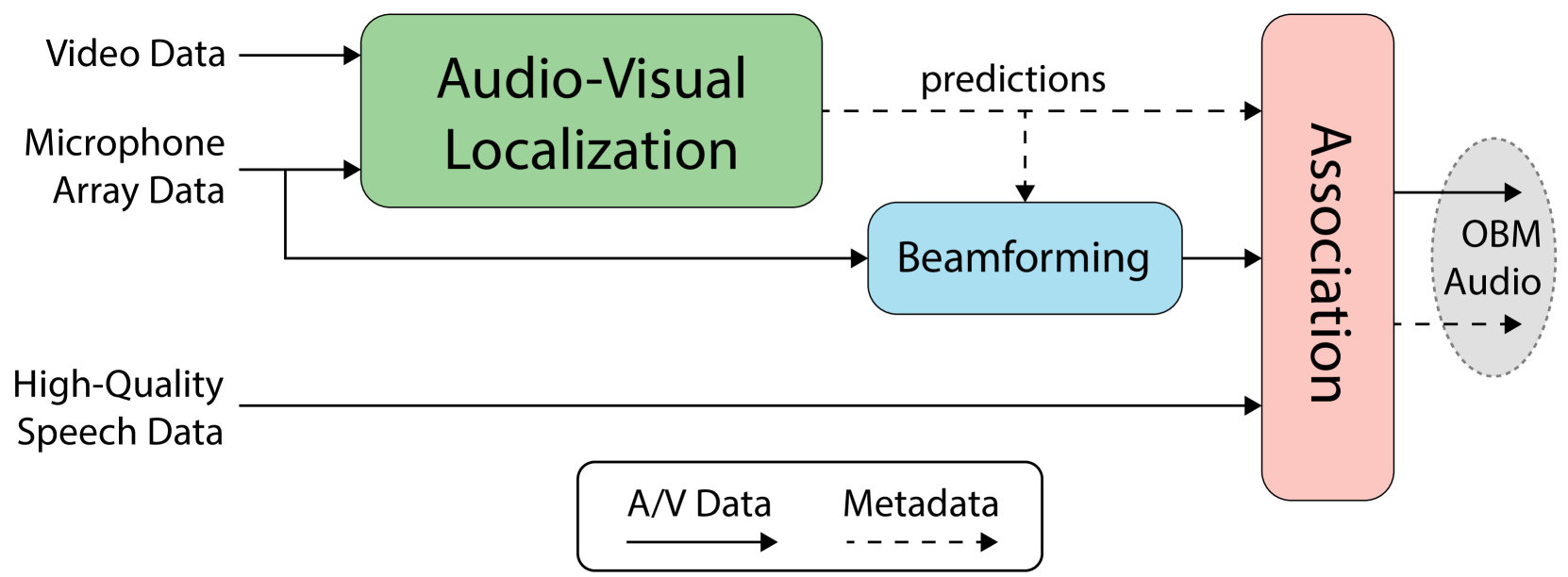
0
Audio-Visual Talker Localization in Video for Spatial Sound Reproduction
Davide Berghi, Philip J. B. Jackson
Object-based audio production requires the positional metadata to be defined for each point-source object, including the key elements in the foreground of the sound scene. In many media production use cases, both cameras and microphones are employed to make recordings, and the human voice is often a key element. In this research, we detect and locate the active speaker in the video, facilitating the automatic extraction of the positional metadata of the talker relative to the camera's reference frame. With the integration of the visual modality, this study expands upon our previous investigation focused solely on audio-based active speaker detection and localization. Our experiments compare conventional audio-visual approaches for active speaker detection that leverage monaural audio, our previous audio-only method that leverages multichannel recordings from a microphone array, and a novel audio-visual approach integrating vision and multichannel audio. We found the role of the two modalities to complement each other. Multichannel audio, overcoming the problem of visual occlusions, provides a double-digit reduction in detection error compared to audio-visual methods with single-channel audio. The combination of multichannel audio and vision further enhances spatial accuracy, leading to a four-percentage point increase in F1 score on the Tragic Talkers dataset. Future investigations will assess the robustness of the model in noisy and highly reverberant environments, as well as tackle the problem of off-screen speakers.
Read more6/4/2024

0
A Review of Common Online Speaker Diarization Methods
Roman Aperdannier, Sigurd Schacht, Alexander Piazza
Speaker diarization provides the answer to the question who spoke when? for an audio file. This information can be used to complete audio transcripts for further processing steps. Most speaker diarization systems assume that the audio file is available as a whole. However, there are scenarios in which the speaker labels are needed immediately after the arrival of an audio segment. Speaker diarization with a correspondingly low latency is referred to as online speaker diarization. This paper provides an overview. First the history of online speaker diarization is briefly presented. Next a taxonomy and datasets for training and evaluation are given. In the sections that follow, online diarization methods and systems are discussed in detail. This paper concludes with the presentation of challenges that still need to be solved by future research in the field of online speaker diarization.
Read more6/21/2024