PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
2404.07336
0
0
Abstract
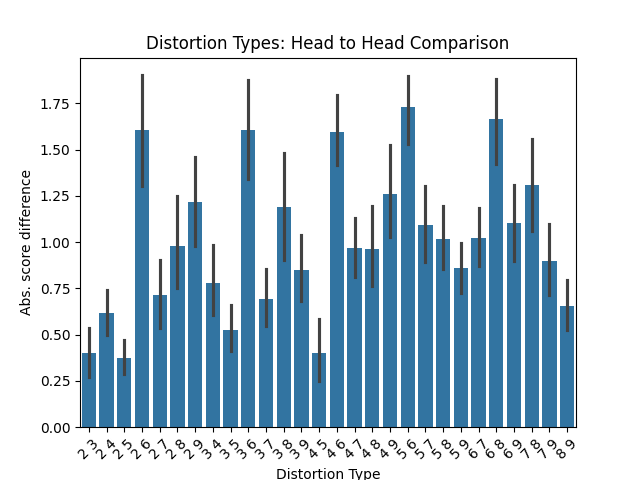
Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos in the wild. To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos in the wild.
Create account to get full access
Overview
- This paper presents a new method called PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) for assessing the synchronization between audio and visual signals in multimedia content.
- The key idea is to ground the evaluation in the subjective opinions of viewers, rather than relying solely on technical metrics.
- The authors conduct extensive user studies to collect viewer ratings of audio-visual synchrony across a variety of video clips, and then use this data to train a machine learning model that can predict synchrony scores.
Plain English Explanation
The researchers developed a new way to evaluate how well audio and video are synchronized in multimedia content. Instead of just looking at technical measurements, they wanted to base the evaluation on what actual viewers think about the synchronization.
To do this, they showed a variety of video clips to lots of people and asked them to rate how well the audio and video were synced up. They used this data from the viewers to train a machine learning model that can now predict synchronization scores for new video clips, without needing to do further user studies.
This approach is valuable because it focuses on the subjective human experience, rather than just relying on objective technical metrics. By grounding the evaluation in viewers' opinions, the researchers can get a better sense of what synchronization levels people actually perceive as good or bad. This could be helpful for improving the quality of audio-visual content across applications like video conferencing, virtual reality, and speech recognition.
Technical Explanation
The core of the PEAVS approach is a user study where participants were shown a variety of video clips with different levels of audio-visual synchronization. Viewers were asked to rate the perceived synchrony on a scale, and this data was used to train a machine learning model.
Specifically, the researchers collected synchrony ratings from over 300 participants for 120 different video clips. These clips covered a range of content types (e.g. speech, music, natural scenes) and included both artificially desynchronized examples and naturally occurring asynchrony.
The researchers then trained a deep neural network model to predict synchrony scores based on features extracted from the audio and video signals. This model was able to achieve strong correlation with the human-provided ratings, demonstrating its ability to capture the subjective perception of synchrony.
Additionally, the paper explores how the PEAVS model can be used to analyze the impacts of audio-visual asynchrony, such as in conversational scenarios or for audio-visual speech recognition. The results suggest the model can provide valuable insights beyond just a synchrony score.
Critical Analysis
One key limitation of the PEAVS approach is that the user study data is collected in a lab setting, which may not fully reflect real-world viewing conditions and preferences. The authors acknowledge this and suggest that future work should explore in-situ evaluations to better capture authentic user experiences.
Additionally, the current PEAVS model is trained on a relatively narrow set of video content, so its generalization to more diverse multimedia applications is an open question. Expanding the model's training data and evaluating its performance across a broader range of use cases would help demonstrate its robustness.
Some readers may also question whether relying solely on subjective viewer ratings is sufficient, and whether incorporating more objective technical metrics could provide additional valuable insights. A hybrid approach combining human and algorithmic assessments may be worth exploring.
Overall, the PEAVS framework represents an interesting step towards grounding audio-visual synchrony evaluation in human perception. With further research and refinement, it could become a useful tool for improving the quality of multimedia experiences across many domains.
Conclusion
The PEAVS method presented in this paper offers a novel approach to assessing audio-visual synchrony that goes beyond traditional technical metrics. By basing the evaluation on the subjective opinions of viewers, the researchers have developed a model that can predict synchrony scores in a way that aligns with human perception.
This work has important implications for applications like virtual reality, video conferencing, and speech recognition, where ensuring high-quality audio-visual synchronization is crucial for providing compelling and natural user experiences. By incorporating the PEAVS approach, developers and researchers can gain deeper insights into how viewers actually experience and respond to asynchrony in multimedia content.
While the current PEAVS model has some limitations, the overall framework represents an important step forward in bridging the gap between technical metrics and human perception. With further refinement and validation, this type of subjective, user-centric evaluation could become an invaluable tool for driving improvements in multimedia technology and enhancing the way people interact with digital content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Visual and audio scene classification for detecting discrepancies in video: a baseline method and experimental protocol
Konstantinos Apostolidis, Jakob Abesser, Luca Cuccovillo, Vasileios Mezaris
0
0
This paper presents a baseline approach and an experimental protocol for a specific content verification problem: detecting discrepancies between the audio and video modalities in multimedia content. We first design and optimize an audio-visual scene classifier, to compare with existing classification baselines that use both modalities. Then, by applying this classifier separately to the audio and the visual modality, we can detect scene-class inconsistencies between them. To facilitate further research and provide a common evaluation platform, we introduce an experimental protocol and a benchmark dataset simulating such inconsistencies. Our approach achieves state-of-the-art results in scene classification and promising outcomes in audio-visual discrepancies detection, highlighting its potential in content verification applications.
5/2/2024

Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Zhaofeng Shi, Qingbo Wu, Fanman Meng, Linfeng Xu, Hongliang Li
0
0
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask for application scenarios such as multi-modal video editing, augmented reality, and intelligent robot systems. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a Global semantic label in each sequence, but the video frame covers multiple semantic objects across different Local regions, which leads to mislocalization of the representationally similar but semantically different object. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-agnostic label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance. Code will be available at https://github.com/ZhaofengSHI/AVS-C3N once accepted.
5/9/2024
🗣️
Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation
Dogucan Yaman, Fevziye Irem Eyiokur, Leonard Barmann, Seymanur Akt{i}, Haz{i}m Kemal Ekenel, Alexander Waibel
0
0
In the task of talking face generation, the objective is to generate a face video with lips synchronized to the corresponding audio while preserving visual details and identity information. Current methods face the challenge of learning accurate lip synchronization while avoiding detrimental effects on visual quality, as well as robustly evaluating such synchronization. To tackle these problems, we propose utilizing an audio-visual speech representation expert (AV-HuBERT) for calculating lip synchronization loss during training. Moreover, leveraging AV-HuBERT's features, we introduce three novel lip synchronization evaluation metrics, aiming to provide a comprehensive assessment of lip synchronization performance. Experimental results, along with a detailed ablation study, demonstrate the effectiveness of our approach and the utility of the proposed evaluation metrics.
5/8/2024

UniAV: Unified Audio-Visual Perception for Multi-Task Video Localization
Tiantian Geng, Teng Wang, Yanfu Zhang, Jinming Duan, Weili Guan, Feng Zheng
0
0
Video localization tasks aim to temporally locate specific instances in videos, including temporal action localization (TAL), sound event detection (SED) and audio-visual event localization (AVEL). Existing methods over-specialize on each task, overlooking the fact that these instances often occur in the same video to form the complete video content. In this work, we present UniAV, a Unified Audio-Visual perception network, to achieve joint learning of TAL, SED and AVEL tasks for the first time. UniAV can leverage diverse data available in task-specific datasets, allowing the model to learn and share mutually beneficial knowledge across tasks and modalities. To tackle the challenges posed by substantial variations in datasets (size/domain/duration) and distinct task characteristics, we propose to uniformly encode visual and audio modalities of all videos to derive generic representations, while also designing task-specific experts to capture unique knowledge for each task. Besides, we develop a unified language-aware classifier by utilizing a pre-trained text encoder, enabling the model to flexibly detect various types of instances and previously unseen ones by simply changing prompts during inference. UniAV outperforms its single-task counterparts by a large margin with fewer parameters, achieving on-par or superior performances compared to state-of-the-art task-specific methods across ActivityNet 1.3, DESED and UnAV-100 benchmarks.
4/5/2024