VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time
2404.10667
0
0

Abstract
We introduce VASA, a framework for generating lifelike talking faces with appealing visual affective skills (VAS) given a single static image and a speech audio clip. Our premiere model, VASA-1, is capable of not only producing lip movements that are exquisitely synchronized with the audio, but also capturing a large spectrum of facial nuances and natural head motions that contribute to the perception of authenticity and liveliness. The core innovations include a holistic facial dynamics and head movement generation model that works in a face latent space, and the development of such an expressive and disentangled face latent space using videos. Through extensive experiments including evaluation on a set of new metrics, we show that our method significantly outperforms previous methods along various dimensions comprehensively. Our method not only delivers high video quality with realistic facial and head dynamics but also supports the online generation of 512x512 videos at up to 40 FPS with negligible starting latency. It paves the way for real-time engagements with lifelike avatars that emulate human conversational behaviors.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents VASA-1, a system that can generate lifelike talking faces in real-time driven by audio input.
- The system is capable of producing high-fidelity facial animations that closely match the speaker's voice and expressions.
- VASA-1 utilizes a disentangled face representation learning approach to separately model the static identity and dynamic facial movements.
- This allows the system to generate realistic talking faces for arbitrary speakers and audio inputs.
Plain English Explanation
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time is a research project that has developed a system capable of creating animated talking faces in real-time. The system takes audio input, such as someone speaking, and generates a video of a virtual face that matches the speech and facial expressions.
The key innovation is the use of a disentangled face representation, which means the system separately models the static facial identity (like the person's distinctive features) and the dynamic facial movements (like their expressions and lip movements). This allows the system to generate talking faces for any speaker, not just the ones it was trained on.
The result is a very lifelike and natural-looking animated face that moves and speaks in sync with the audio input. This technology could have applications in areas like virtual assistants, video conferencing, and animated films and games. By separating the identity and motion, the system can create customized talking avatars that feel more personalized and engaging.
Technical Explanation
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time presents an end-to-end system for generating high-fidelity talking faces from audio input in real-time. The system uses a disentangled face representation to separately model the static facial identity and the dynamic facial movements.
The architecture consists of several key components:
- Audio Encoder: Encodes the input audio into a latent representation.
- Identity Encoder: Encodes a reference face image into a static identity representation.
- Motion Decoder: Takes the audio latent and identity representation to predict the dynamic facial movements.
- Rendering Module: Synthesizes the final talking face video by applying the predicted motion to the static identity.
This disentangled approach allows the system to generate talking faces for any speaker, not just those seen during training. The authors demonstrate the system's capabilities on a range of speakers and show that it can produce highly realistic and synchronized facial animations.
Related work includes Talk3D, which also focuses on audio-driven talking face synthesis, and AudioChatLLaMA, which explores speech-driven animation in language models.
Critical Analysis
The VASA-1 system represents an impressive advance in audio-driven talking face generation, producing highly lifelike and responsive animations. The use of a disentangled face representation is a key innovation that allows the system to generalize to new speakers.
However, the paper does not extensively discuss the limitations of the approach. For example, it is unclear how well the system would handle noisy or low-quality audio inputs, or how it would perform on speakers with very distinctive facial features or speech patterns.
Additionally, the training and inference times of the system are not reported, which makes it difficult to assess the real-world practicality of deploying VASA-1 in interactive applications. Further research could explore ways to improve the efficiency and robustness of the system.
Another potential area for improvement is the ability to control higher-level aspects of the facial animation, such as emotional expression or lip synchronization. EDTalk has explored disentangling these elements, which could be a valuable addition to the VASA-1 framework.
Overall, VASA-1 represents an exciting step forward in audio-driven talking face synthesis, but there are still opportunities to enhance the system's capabilities and real-world applicability.
Conclusion
VASA-1: Lifelike Audio-Driven Talking Faces Generated in Real Time presents a novel system that can generate highly realistic talking faces from audio input in real-time. The key innovation is the use of a disentangled face representation, which allows the system to produce personalized animations for any speaker.
This technology has the potential to significantly impact fields like virtual assistants, video conferencing, and animated media, by providing a more natural and engaging interface. While the current system demonstrates impressive capabilities, there are opportunities to further improve its robustness, efficiency, and controllability. Ongoing research in this area will likely lead to increasingly sophisticated and versatile audio-driven animation systems.
Related Papers
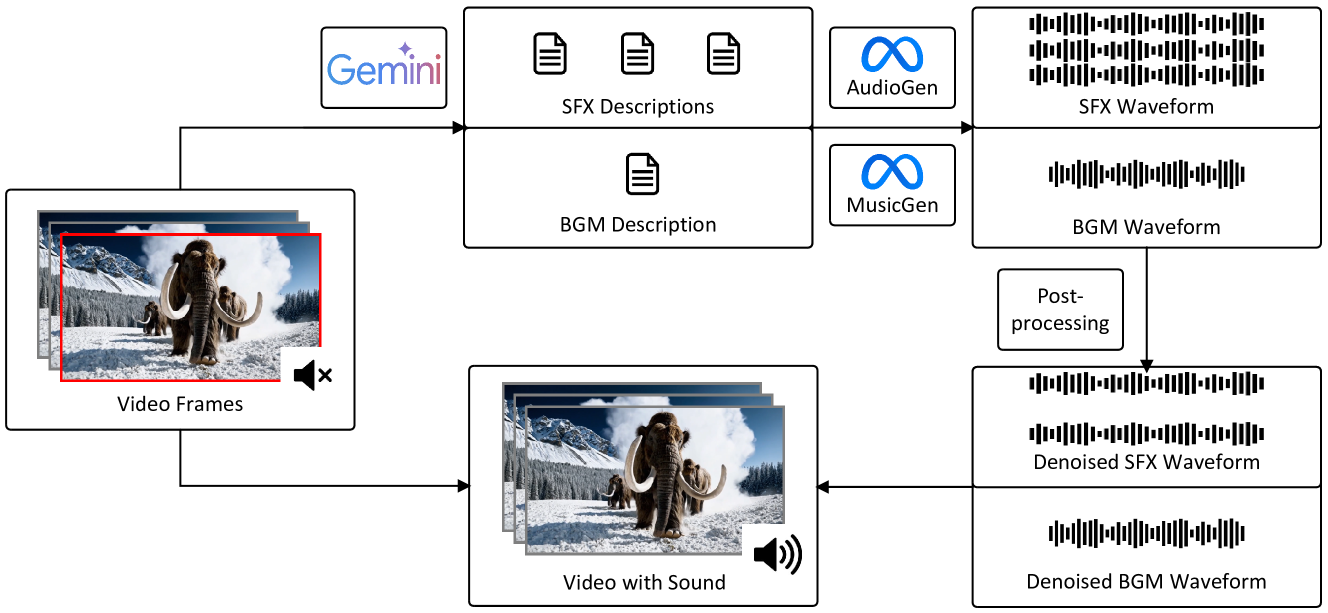
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Gehui Chen, Guan'an Wang, Xiaowen Huang, Jitao Sang
0
0
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
4/29/2024
🗣️
Audio-Visual Speech Representation Expert for Enhanced Talking Face Video Generation and Evaluation
Dogucan Yaman, Fevziye Irem Eyiokur, Leonard Barmann, Seymanur Akt{i}, Haz{i}m Kemal Ekenel, Alexander Waibel
0
0
In the task of talking face generation, the objective is to generate a face video with lips synchronized to the corresponding audio while preserving visual details and identity information. Current methods face the challenge of learning accurate lip synchronization while avoiding detrimental effects on visual quality, as well as robustly evaluating such synchronization. To tackle these problems, we propose utilizing an audio-visual speech representation expert (AV-HuBERT) for calculating lip synchronization loss during training. Moreover, leveraging AV-HuBERT's features, we introduce three novel lip synchronization evaluation metrics, aiming to provide a comprehensive assessment of lip synchronization performance. Experimental results, along with a detailed ablation study, demonstrate the effectiveness of our approach and the utility of the proposed evaluation metrics.
5/8/2024
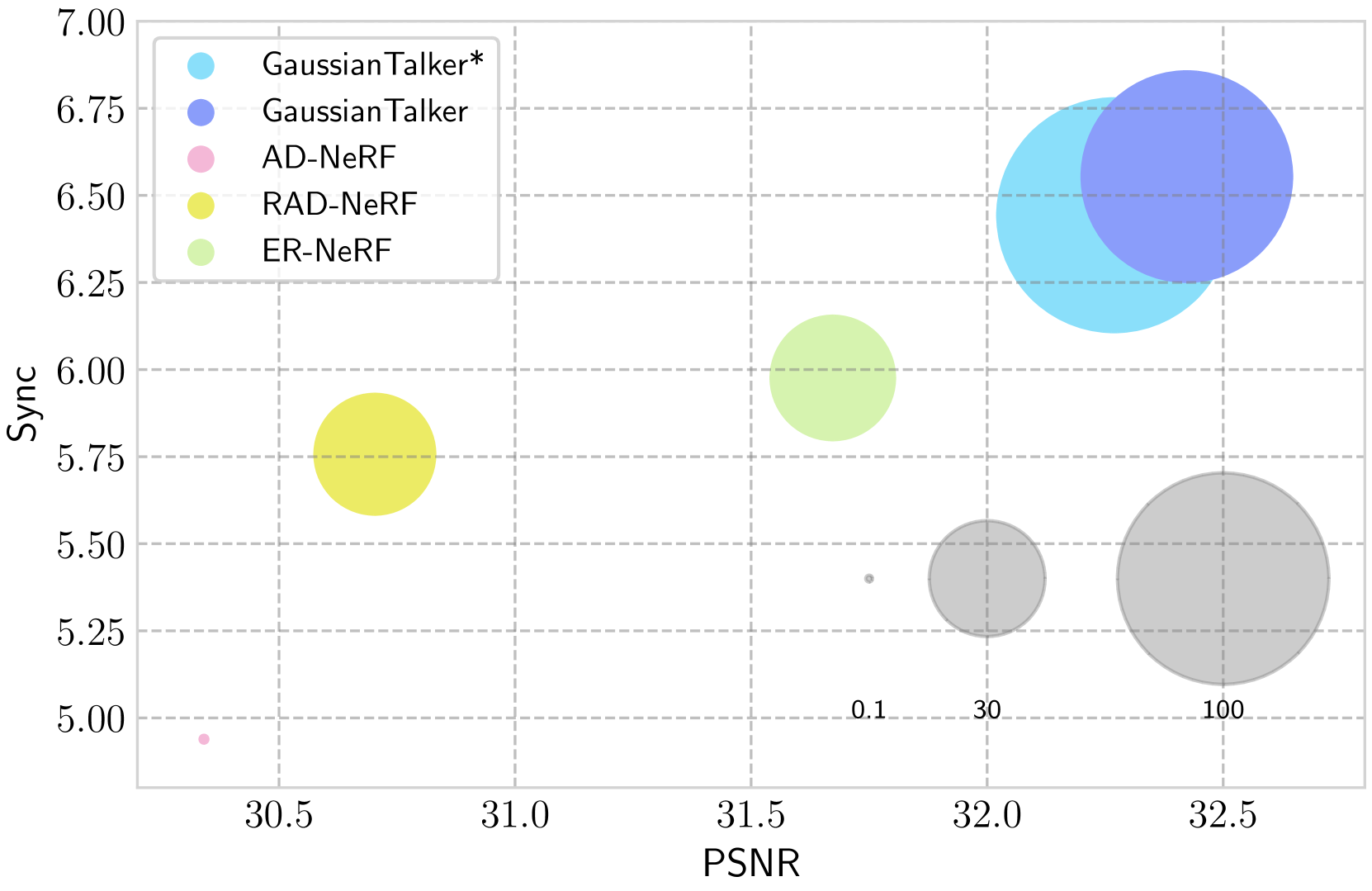
GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
Kyusun Cho, Joungbin Lee, Heeji Yoon, Yeobin Hong, Jaehoon Ko, Sangjun Ahn, Seungryong Kim
0
0
We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker's superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
4/26/2024
👨🏫
CSTalk: Correlation Supervised Speech-driven 3D Emotional Facial Animation Generation
Xiangyu Liang, Wenlin Zhuang, Tianyong Wang, Guangxing Geng, Guangyue Geng, Haifeng Xia, Siyu Xia
0
0
Speech-driven 3D facial animation technology has been developed for years, but its practical application still lacks expectations. The main challenges lie in data limitations, lip alignment, and the naturalness of facial expressions. Although lip alignment has seen many related studies, existing methods struggle to synthesize natural and realistic expressions, resulting in a mechanical and stiff appearance of facial animations. Even with some research extracting emotional features from speech, the randomness of facial movements limits the effective expression of emotions. To address this issue, this paper proposes a method called CSTalk (Correlation Supervised) that models the correlations among different regions of facial movements and supervises the training of the generative model to generate realistic expressions that conform to human facial motion patterns. To generate more intricate animations, we employ a rich set of control parameters based on the metahuman character model and capture a dataset for five different emotions. We train a generative network using an autoencoder structure and input an emotion embedding vector to achieve the generation of user-control expressions. Experimental results demonstrate that our method outperforms existing state-of-the-art methods.
4/30/2024