Phased Consistency Model
2405.18407
0
0
📈
Abstract
The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
Create account to get full access
Overview
- The paper discusses a new model called the Phased Consistency Model (PCM) that improves upon the existing Latent Consistency Model (LCM) for high-resolution, text-conditioned image generation.
- The authors identify three key flaws in the current design of LCM and propose PCM as a generalized solution to address these limitations.
- Evaluations show that PCM significantly outperforms LCM across various generation settings and even achieves superior or comparable results to specialized 1-step methods.
- The authors also demonstrate the versatility of PCM by applying it to video generation, enabling state-of-the-art few-step text-to-video generation.
Plain English Explanation
The paper focuses on improving a technique called Latent Consistency Model (LCM) for generating high-resolution images based on text descriptions. While LCM has shown progress, the authors found three main issues with its current design.
To address these problems, the researchers developed a new model called the Phased Consistency Model (PCM). This generalized approach tackles the limitations of LCM and significantly outperforms it in generating images across different settings, from single-step to multi-step refinement. Interestingly, PCM even matches or surpasses the performance of specialized 1-step generation methods.
Beyond image generation, the authors demonstrate the versatility of PCM by applying it to video generation. This allows them to create a state-of-the-art text-to-video generator that can produce high-quality videos in just a few steps.
Technical Explanation
The paper identifies three key flaws in the current design of the Latent Consistency Model (LCM) for high-resolution, text-conditioned image generation:
- Insufficient modeling of the consistency between text and image latent representations.
- Lack of a principled way to incorporate multi-step refinement.
- Suboptimal architecture choices that limit the model's performance.
To address these limitations, the authors propose the Phased Consistency Model (PCM), which generalizes the design space and introduces several key innovations:
- Improved Consistency Modeling: PCM employs a novel consistency loss function that better captures the relationship between text and image latent representations.
- Multi-Step Refinement: PCM introduces a multi-stage generation process, allowing for gradual refinement of the output.
- Architectural Enhancements: PCM's architecture incorporates several design choices, such as the use of diffusion models and trajectory-level consistency, to improve its performance.
The authors' evaluations demonstrate that PCM significantly outperforms LCM across various generation settings, from 1 to 16 steps. Notably, PCM achieves superior or comparable results to specialized 1-step methods, despite being designed for multi-step refinement.
Furthermore, the authors show the versatility of PCM's methodology by applying it to video generation. This allows them to train a state-of-the-art few-step text-to-video generator, showcasing the model's broad applicability.
Critical Analysis
The paper presents a well-designed and comprehensive solution to address the limitations of the existing Latent Consistency Model (LCM) for high-resolution, text-conditioned image generation. The authors have identified the key issues and proposed the Phased Consistency Model (PCM) as a generalized approach to tackle these problems.
One potential concern raised in the paper is the trade-off between the model's performance and computational efficiency. While PCM outperforms LCM, the additional complexity and multi-stage design may come with increased computational requirements. The authors acknowledge this and suggest that future work could focus on improving the efficiency of PCM.
Additionally, the paper does not provide a detailed analysis of the model's robustness to different types of text inputs or its ability to handle edge cases. It would be valuable to see how PCM performs with more diverse or challenging text prompts, as well as its generalization capabilities.
Furthermore, the paper does not discuss the potential ethical implications of the proposed text-to-image and text-to-video generation models. As these technologies become more advanced, it is essential to consider their potential misuse, such as the creation of fake media or the spread of misinformation. Future research could explore ways to mitigate these risks and ensure the responsible development of such generative models.
Conclusion
The Phased Consistency Model (PCM) introduced in this paper represents a significant advancement in the field of high-resolution, text-conditioned image generation. By addressing the limitations of the existing Latent Consistency Model (LCM), PCM demonstrates superior performance across various generation settings and even outperforms specialized 1-step methods.
The versatility of PCM's methodology, as shown by its application to video generation, suggests its potential to be a valuable tool in a wide range of multimedia creation tasks. As the authors highlight, further research on improving the efficiency and robustness of PCM could lead to even more impactful applications of this technology.
Overall, the Phased Consistency Model presented in this paper is a promising step forward in the development of advanced generative models, with the potential to enhance various creative and multimedia applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Consistency^2: Consistent and Fast 3D Painting with Latent Consistency Models
Tianfu Wang, Anton Obukhov, Konrad Schindler
0
0
Generative 3D Painting is among the top productivity boosters in high-resolution 3D asset management and recycling. Ever since text-to-image models became accessible for inference on consumer hardware, the performance of 3D Painting methods has consistently improved and is currently close to plateauing. At the core of most such models lies denoising diffusion in the latent space, an inherently time-consuming iterative process. Multiple techniques have been developed recently to accelerate generation and reduce sampling iterations by orders of magnitude. Designed for 2D generative imaging, these techniques do not come with recipes for lifting them into 3D. In this paper, we address this shortcoming by proposing a Latent Consistency Model (LCM) adaptation for the task at hand. We analyze the strengths and weaknesses of the proposed model and evaluate it quantitatively and qualitatively. Based on the Objaverse dataset samples study, our 3D painting method attains strong preference in all evaluations. Source code is available at https://github.com/kongdai123/consistency2.
6/18/2024

Consistency Models Made Easy
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, J. Zico Kolter
0
0
Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.
6/21/2024
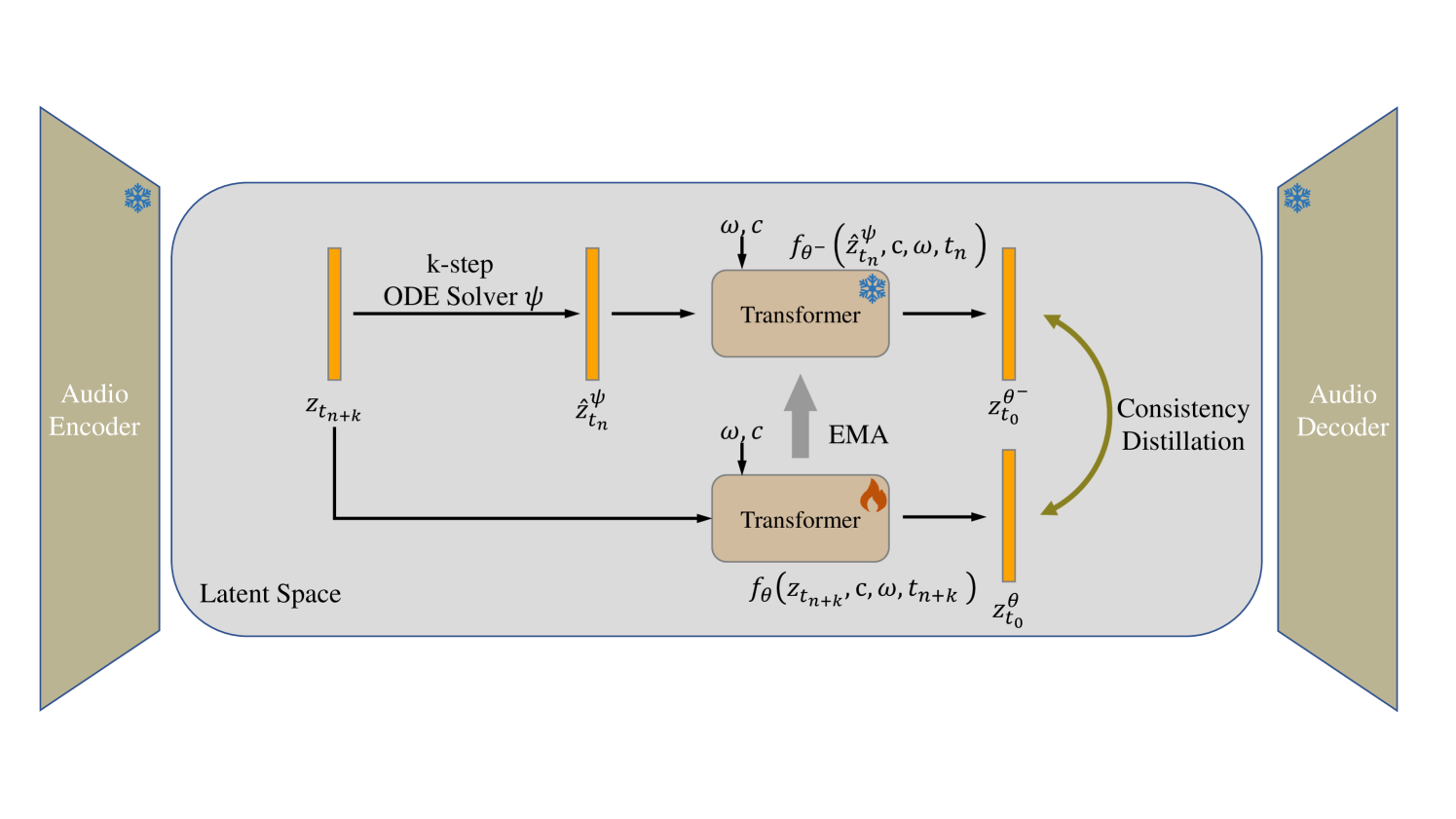
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024

MLCM: Multistep Consistency Distillation of Latent Diffusion Model
Qingsong Xie, Zhenyi Liao, Chen chen, Zhijie Deng, Shixiang Tang, Haonan Lu
0
0
Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2-4) and/or moderate (e.g., 5-8) sampling steps. To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD. We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model. MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2-8 sampling steps. On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM [23], 8-step SDXL-Lightning [17], and 8-step HyperSD [33]. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
6/13/2024