MLCM: Multistep Consistency Distillation of Latent Diffusion Model
2406.05768
0
0

Abstract
Distilling large latent diffusion models (LDMs) into ones that are fast to sample from is attracting growing research interest. However, the majority of existing methods face a dilemma where they either (i) depend on multiple individual distilled models for different sampling budgets, or (ii) sacrifice generation quality with limited (e.g., 2-4) and/or moderate (e.g., 5-8) sampling steps. To address these, we extend the recent multistep consistency distillation (MCD) strategy to representative LDMs, establishing the Multistep Latent Consistency Models (MLCMs) approach for low-cost high-quality image synthesis. MLCM serves as a unified model for various sampling steps due to the promise of MCD. We further augment MCD with a progressive training strategy to strengthen inter-segment consistency to boost the quality of few-step generations. We take the states from the sampling trajectories of the teacher model as training data for MLCMs to lift the requirements for high-quality training datasets and to bridge the gap between the training and inference of the distilled model. MLCM is compatible with preference learning strategies for further improvement of visual quality and aesthetic appeal. Empirically, MLCM can generate high-quality, delightful images with only 2-8 sampling steps. On the MSCOCO-2017 5K benchmark, MLCM distilled from SDXL gets a CLIP Score of 33.30, Aesthetic Score of 6.19, and Image Reward of 1.20 with only 4 steps, substantially surpassing 4-step LCM [23], 8-step SDXL-Lightning [17], and 8-step HyperSD [33]. We also demonstrate the versatility of MLCMs in applications including controllable generation, image style transfer, and Chinese-to-image generation.
Create account to get full access
Overview
- Introduces a new approach called Multistep Latent Consistency Model (MLCM) for improving the performance of latent diffusion models
- Builds on prior work on consistency distillation techniques like Accelerating Diffusion Models with Stochastic Consistency Distillation, Phased Consistency Model, and AudioLCM: Text-to-Audio Generation with Latent Consistency
- Aims to enhance the latent consistency of diffusion models through a multistep training process
Plain English Explanation
The paper presents a new technique called the Multistep Latent Consistency Model (MLCM) that can improve the performance of latent diffusion models. Latent diffusion models are a type of AI system that can generate images, text, and other media by learning the patterns in a large dataset.
The key insight of MLCM is that by training the model in multiple steps, it can learn to produce more consistent and high-quality outputs. The first step trains the model to produce a rough initial output. Then, in subsequent steps, the model refines and improves the output, making it more coherent and realistic.
This "multistep" training process is inspired by prior research on consistency distillation, which has shown that encouraging a model to produce consistent outputs can lead to better performance. By applying this idea to latent diffusion models specifically, the authors aim to unlock even greater capabilities in these powerful AI systems.
The paper provides a technical explanation of how MLCM works and demonstrates its effectiveness through experiments on various image and text generation tasks. The results show that MLCM can outperform standard latent diffusion models, producing more visually appealing and semantically coherent outputs.
Overall, the MLCM technique represents an important advance in the field of generative AI, offering a way to make latent diffusion models even more capable and reliable. By focusing on the consistency of the generated outputs, the researchers have found a promising path to further improving the state-of-the-art in this rapidly evolving area of AI technology.
Technical Explanation
The Multistep Latent Consistency Model (MLCM) builds upon the concept of Accelerating Diffusion Models with Stochastic Consistency Distillation, which showed that encouraging a diffusion model to produce consistent outputs can lead to performance improvements. The authors extend this idea to the context of latent diffusion models, which operate in a lower-dimensional latent space.
The key innovation of MLCM is a multistep training process that involves sequential refinement of the model's outputs. In the first step, the model is trained to produce an initial latent representation of the desired output. In subsequent steps, the model is trained to refine this latent representation, gradually improving its consistency and quality.
This multistep approach is inspired by techniques like Phased Consistency Model and AudioLCM: Text-to-Audio Generation with Latent Consistency, which have demonstrated the benefits of a stepwise learning process for improving the coherence and realism of generated outputs.
The authors evaluate MLCM on a range of image and text generation tasks, comparing its performance to standard latent diffusion models. The results show that MLCM consistently outperforms the baseline, producing more visually appealing and semantically coherent outputs. The authors attribute this improvement to the model's enhanced ability to maintain latent consistency throughout the generation process.
Critical Analysis
The MLCM paper presents a promising approach for improving the performance of latent diffusion models, and the experimental results are quite compelling. However, the authors do acknowledge some potential limitations and areas for further research.
One limitation is that the multistep training process can be computationally intensive, as it requires multiple rounds of optimization. The authors suggest that techniques like gradient checkpointing or model parallelism could help mitigate the computational burden, but this remains an area for future exploration.
Additionally, the paper does not provide a deep analysis of the specific mechanisms by which MLCM achieves its performance gains. While the authors hypothesize that the enhanced latent consistency is the key driver, a more detailed investigation of the model's internal workings could yield additional insights.
Further research could also explore the generalization of MLCM to other types of generative models, beyond just latent diffusion. Applying the multistep consistency distillation approach to other architectures or domains could uncover its broader applicability and potential for even greater impact.
Overall, the MLCM paper represents a significant contribution to the field of generative AI, offering a novel and effective technique for improving the consistency and quality of latent diffusion models. As the research in this area continues to evolve, the insights and methods presented in this work are likely to have a lasting influence on the development of increasingly capable and reliable generative AI systems.
Conclusion
The Multistep Latent Consistency Model (MLCM) introduced in this paper offers a promising new approach for enhancing the performance of latent diffusion models, a powerful class of generative AI systems. By incorporating a multistep training process that focuses on improving the consistency of the model's latent representations, MLCM is able to produce more visually appealing and semantically coherent outputs compared to standard latent diffusion models.
This work builds on prior research in consistency distillation techniques, such as Accelerating Diffusion Models with Stochastic Consistency Distillation, Phased Consistency Model, and AudioLCM: Text-to-Audio Generation with Latent Consistency, and represents an important advancement in the field.
As the capabilities of generative AI continue to evolve, techniques like MLCM will play a vital role in unlocking even greater potential in these systems. By focusing on the consistency and coherence of the generated outputs, researchers can create models that are more reliable, versatile, and impactful across a wide range of applications, from creative content generation to scientific discovery and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
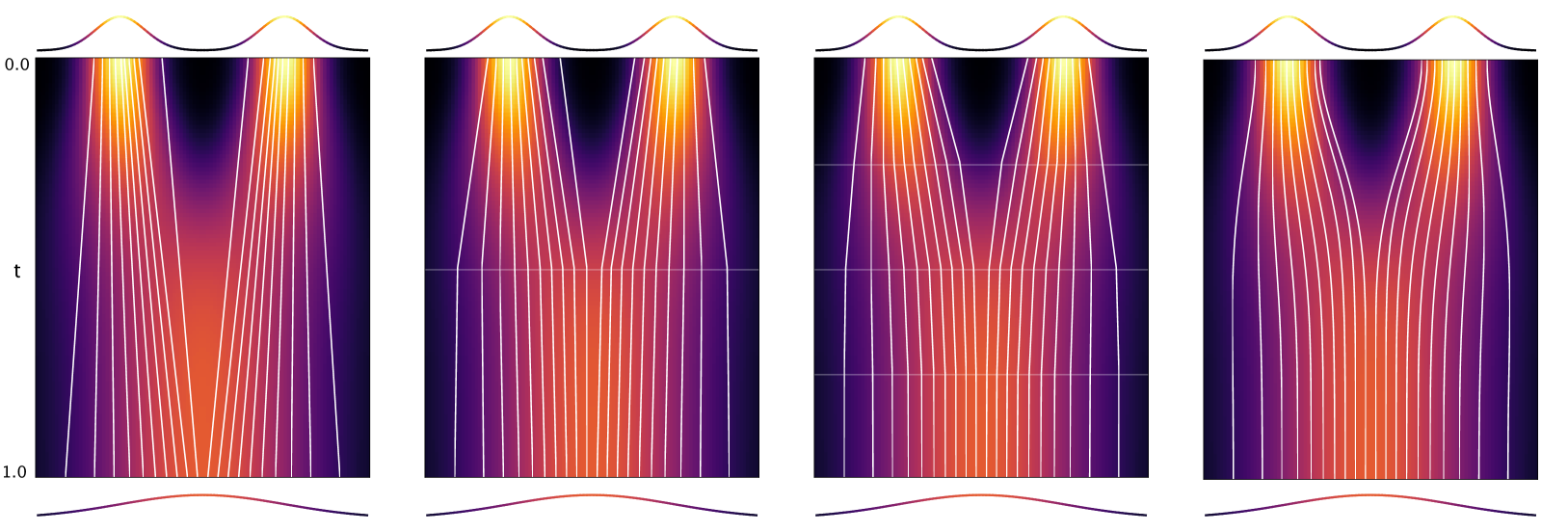
Multistep Consistency Models
Jonathan Heek, Emiel Hoogeboom, Tim Salimans
0
0
Diffusion models are relatively easy to train but require many steps to generate samples. Consistency models are far more difficult to train, but generate samples in a single step. In this paper we propose Multistep Consistency Models: A unification between Consistency Models (Song et al., 2023) and TRACT (Berthelot et al., 2023) that can interpolate between a consistency model and a diffusion model: a trade-off between sampling speed and sampling quality. Specifically, a 1-step consistency model is a conventional consistency model whereas a $infty$-step consistency model is a diffusion model. Multistep Consistency Models work really well in practice. By increasing the sample budget from a single step to 2-8 steps, we can train models more easily that generate higher quality samples, while retaining much of the sampling speed benefits. Notable results are 1.4 FID on Imagenet 64 in 8 step and 2.1 FID on Imagenet128 in 8 steps with consistency distillation, using simple losses without adversarial training. We also show that our method scales to a text-to-image diffusion model, generating samples that are close to the quality of the original model.
6/4/2024

SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Hongjian Liu, Qingsong Xie, Zhijie Deng, Chen Chen, Shixiang Tang, Fueyang Fu, Zheng-jun Zha, Haonan Lu
0
0
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
4/16/2024
📈
Phased Consistency Model
Fu-Yun Wang, Zhaoyang Huang, Alexander William Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, Hongsheng Li, Xiaogang Wang
0
0
The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
5/29/2024
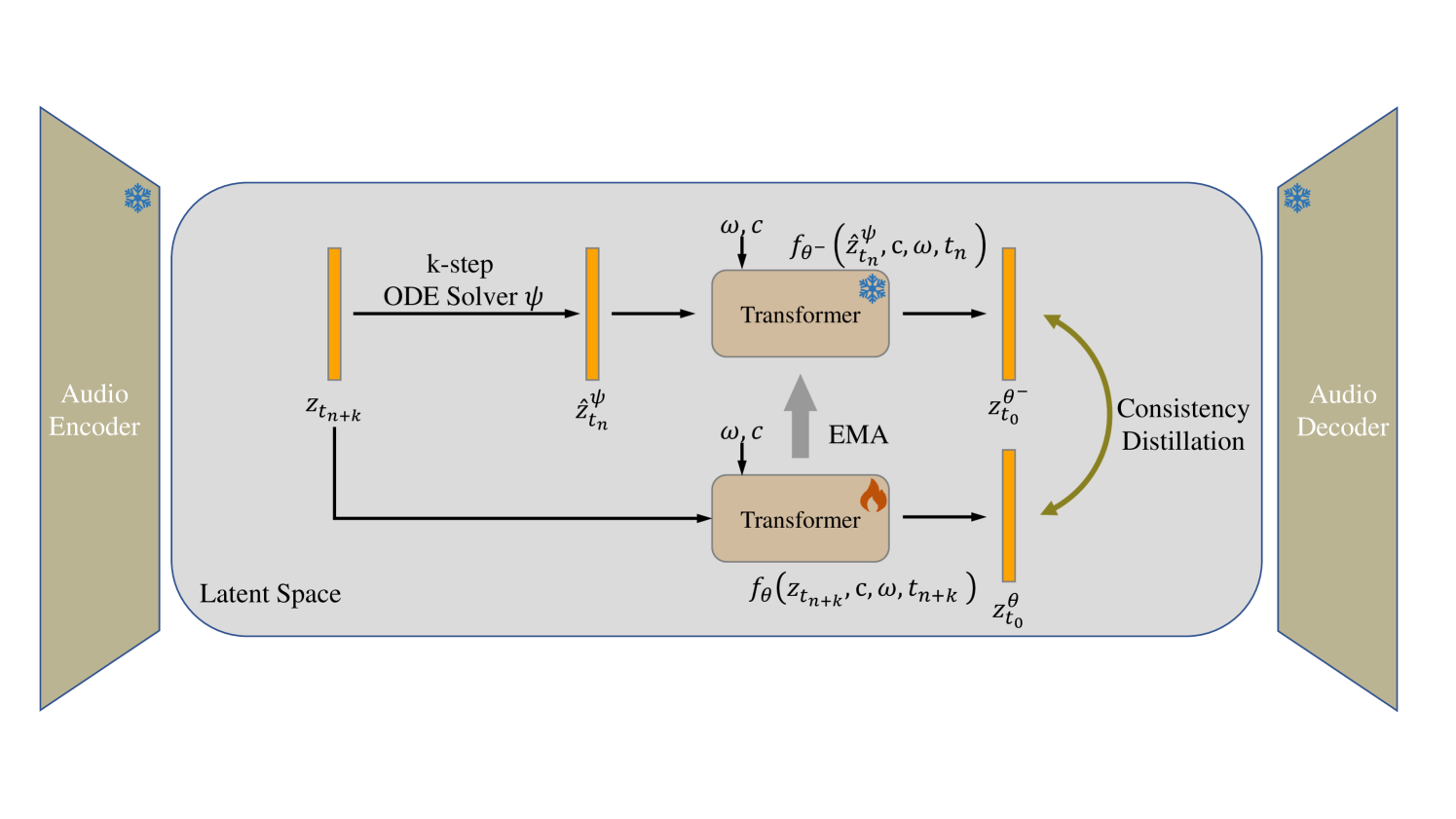
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024