ConsistencyTTA: Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
2309.10740
0
0

Abstract
Diffusion models are instrumental in text-to-audio (TTA) generation. Unfortunately, they suffer from slow inference due to an excessive number of queries to the underlying denoising network per generation. To address this bottleneck, we introduce ConsistencyTTA, a framework requiring only a single non-autoregressive network query, thereby accelerating TTA by hundreds of times. We achieve so by proposing CFG-aware latent consistency model, which adapts consistency generation into a latent space and incorporates classifier-free guidance (CFG) into model training. Moreover, unlike diffusion models, ConsistencyTTA can be finetuned closed-loop with audio-space text-aware metrics, such as CLAP score, to further enhance the generations. Our objective and subjective evaluation on the AudioCaps dataset shows that compared to diffusion-based counterparts, ConsistencyTTA reduces inference computation by 400x while retaining generation quality and diversity.
Create account to get full access
Overview
- This paper explores a method called "Consistency Distillation" to accelerate the process of generating audio from text using diffusion models.
- Diffusion models are a type of machine learning model that can generate high-quality audio by learning from a large dataset of audio samples.
- However, training diffusion models for text-to-audio generation can be computationally expensive and time-consuming.
- The Consistency Distillation approach aims to speed up this process by training a smaller, more efficient model to mimic the behavior of the larger, more complex diffusion model.
Plain English Explanation
Generating high-quality audio from text is a challenging task, but diffusion models have shown promising results. These models work by learning from a large dataset of audio samples and then using that knowledge to create new audio that matches the given text. However, training these diffusion models can take a long time and require a lot of computing power.
The researchers in this paper developed a technique called "Consistency Distillation" to make the training process faster and more efficient. The key idea is to train a smaller, simpler model to mimic the behavior of the larger, more complex diffusion model. This smaller model can then be used to generate audio just as well as the original diffusion model, but much more quickly and with less computing power.
The researchers tested their Consistency Distillation approach on several different text-to-audio generation tasks, and they found that it was able to significantly speed up the process without sacrificing the quality of the generated audio. This could be especially useful for applications where real-time or low-latency audio generation is important, such as in virtual assistants or interactive audio experiences.
Technical Explanation
The paper builds on previous work in diffusion models for text-to-audio generation and consistency models for audio generation. The key idea of Consistency Distillation is to train a smaller "student" model to mimic the behavior of a larger "teacher" diffusion model.
The authors first train a large, complex diffusion model on a dataset of audio samples. This diffusion model can then be used to generate high-quality audio from text inputs. However, the training and inference processes for this diffusion model can be computationally expensive and time-consuming.
To address this, the authors train a smaller, more efficient "student" model to approximate the behavior of the larger "teacher" diffusion model. This student model is trained using a combination of standard supervised learning techniques and a novel "consistency distillation" loss function. The consistency distillation loss encourages the student model to generate audio samples that are consistent with the outputs of the teacher diffusion model, even if the student model's internal representations differ.
The authors evaluate their Consistency Distillation approach on several text-to-audio generation benchmarks, including the TANGO and SoundCTM datasets. They find that the student model trained with Consistency Distillation is able to generate audio that is comparable in quality to the original diffusion model, but with significantly faster inference times.
Critical Analysis
The Consistency Distillation approach presented in this paper is a promising technique for accelerating the process of text-to-audio generation using diffusion models. By training a smaller, more efficient student model to mimic the behavior of a larger, more complex teacher model, the authors are able to reduce the computational cost and training time required.
One potential limitation of this approach is that it relies on the availability of a high-quality diffusion model to serve as the "teacher." If the teacher model is not well-trained or has suboptimal performance, the student model may not be able to fully capture its capabilities. Additionally, the authors note that the Consistency Distillation approach may be sensitive to the choice of hyperparameters and architectural details.
Another area for further research could be exploring ways to further improve the efficiency and performance of the student model, beyond just mimicking the teacher. For example, the student model could potentially be trained to learn more abstract, generalized representations that would allow it to generate even higher-quality audio than the teacher model in certain scenarios.
Overall, the Consistency Distillation approach presented in this paper represents an important step forward in making diffusion-based text-to-audio generation more practical and accessible for real-world applications. However, as with any research, there is still room for improvement and further exploration.
Conclusion
This paper introduces a novel technique called "Consistency Distillation" that can be used to accelerate the process of generating high-quality audio from text using diffusion models. By training a smaller, more efficient "student" model to mimic the behavior of a larger, more complex "teacher" diffusion model, the authors are able to reduce the computational cost and training time required, without sacrificing the quality of the generated audio.
The Consistency Distillation approach has the potential to make diffusion-based text-to-audio generation more accessible and practical for a wide range of applications, from virtual assistants to interactive audio experiences. While the technique has some limitations and areas for further research, it represents an important step forward in the field of generative text-to-audio models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
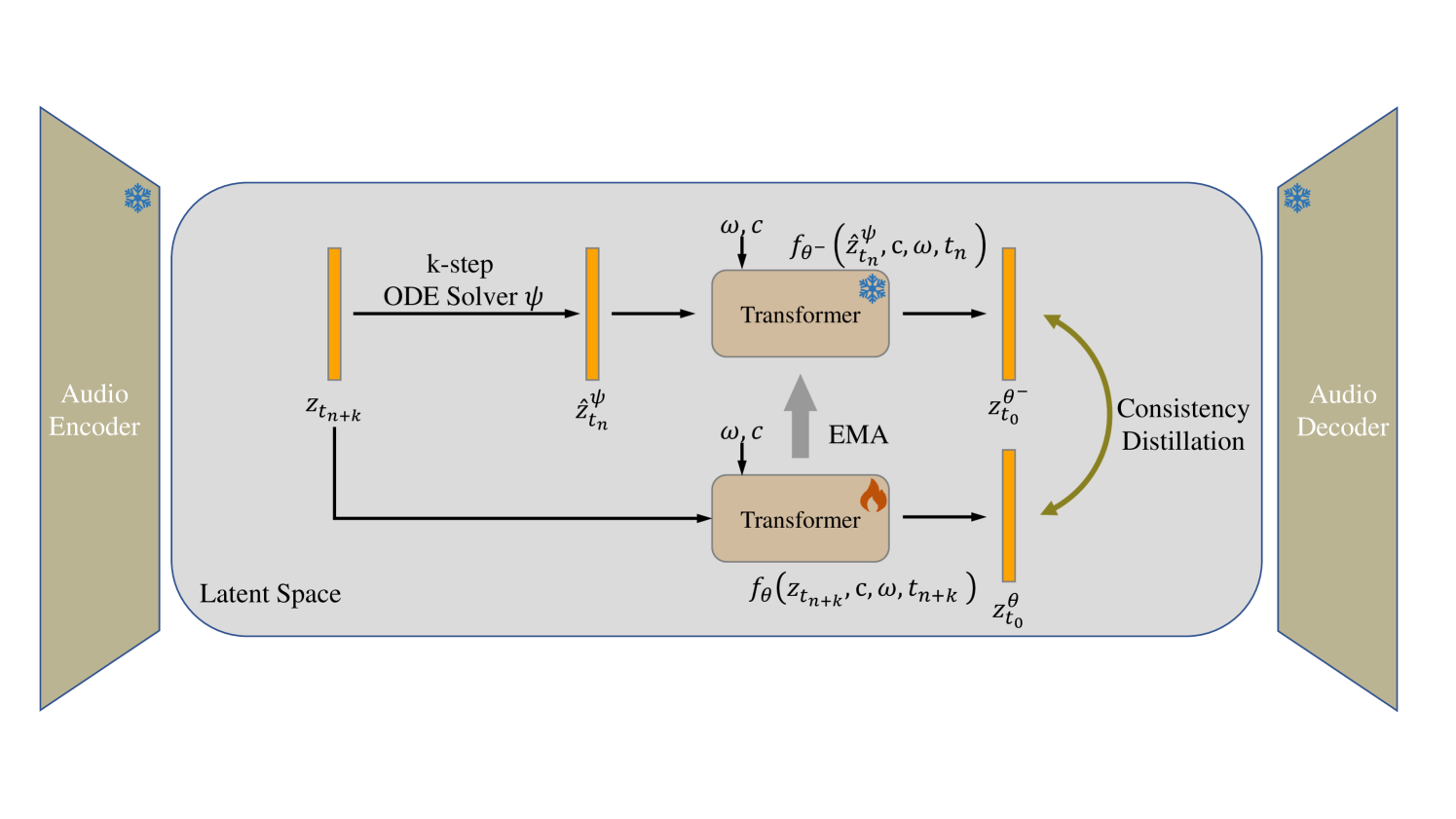
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024
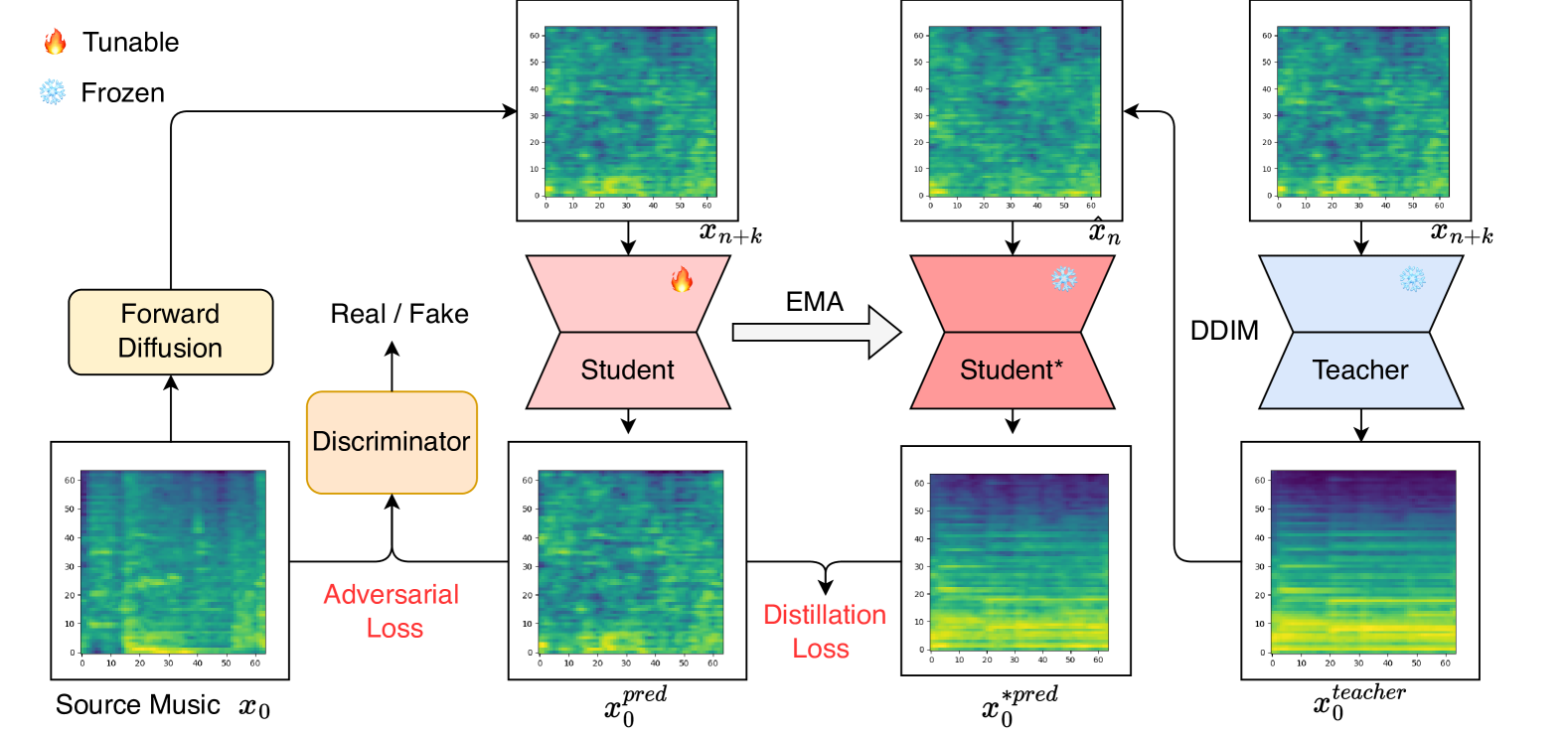
Music Consistency Models
Zhengcong Fei, Mingyuan Fan, Junshi Huang
0
0
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
4/23/2024

Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, Wei-Ning Hsu, Rada Mihalcea, Soujanya Poria
0
0
Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
4/17/2024

SoundCTM: Uniting Score-based and Consistency Models for Text-to-Sound Generation
Koichi Saito, Dongjun Kim, Takashi Shibuya, Chieh-Hsin Lai, Zhi Zhong, Yuhta Takida, Yuki Mitsufuji
0
0
Sound content is an indispensable element for multimedia works such as video games, music, and films. Recent high-quality diffusion-based sound generation models can serve as valuable tools for the creators. However, despite producing high-quality sounds, these models often suffer from slow inference speeds. This drawback burdens creators, who typically refine their sounds through trial and error to align them with their artistic intentions. To address this issue, we introduce Sound Consistency Trajectory Models (SoundCTM). Our model enables flexible transitioning between high-quality 1-step sound generation and superior sound quality through multi-step generation. This allows creators to initially control sounds with 1-step samples before refining them through multi-step generation. While CTM fundamentally achieves flexible 1-step and multi-step generation, its impressive performance heavily depends on an additional pretrained feature extractor and an adversarial loss, which are expensive to train and not always available in other domains. Thus, we reframe CTM's training framework and introduce a novel feature distance by utilizing the teacher's network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we train conditional and unconditional student models simultaneously and interpolate between these models during inference. We also propose training-free controllable frameworks for SoundCTM, leveraging its flexible sampling capability. SoundCTM achieves both promising 1-step and multi-step real-time sound generation without using any extra off-the-shelf networks. Furthermore, we demonstrate SoundCTM's capability of controllable sound generation in a training-free manner. Our codes, pretrained models, and audio samples are available at https://github.com/sony/soundctm.
6/12/2024