Adaptive Visual Scene Understanding: Incremental Scene Graph Generation

0
Sign in to get full access
Overview
- This paper proposes a novel benchmark for Continual Scene Graph Generation (CSEGG), which aims to incrementally learn and generate scene graphs from visual inputs.
- The CSEGG benchmark introduces new challenges in scene understanding, such as handling novel object categories, relationships, and attributes over time.
- The authors also present a new model, called Adaptive Visual Scene Understanding (AVSU), which can incrementally learn and generate scene graphs in a continual learning setting.
Plain English Explanation
The research paper describes a new way to help computers understand and describe visual scenes. Computers often struggle to fully comprehend the complex relationships and details in images, but this work aims to address that challenge.
The key idea is to build a system that can continuously learn about new objects, relationships, and attributes in images, rather than being limited to a fixed set. This is known as "continual learning" - the ability to gain new knowledge without forgetting what was learned before.
To enable this, the researchers created a new benchmark called CSEGG (Continual Scene Graph Generation). This benchmark presents a series of visual scenes, with new elements introduced over time. The goal is for the system to learn and update its understanding of the scenes as new information becomes available.
The researchers also developed a new model called AVSU (Adaptive Visual Scene Understanding) that can handle this continual learning process. AVSU is designed to incrementally build a "scene graph" - a structured representation of the objects, relationships, and attributes in an image. As the benchmark progresses, AVSU adapts and expands its understanding to encompass the new elements.
By developing this continual learning approach to scene understanding, the researchers hope to create AI systems that can more flexibly and comprehensively perceive and describe the visual world around them. This could have applications in areas like robotics, autonomous driving, and virtual/augmented reality.
Technical Explanation
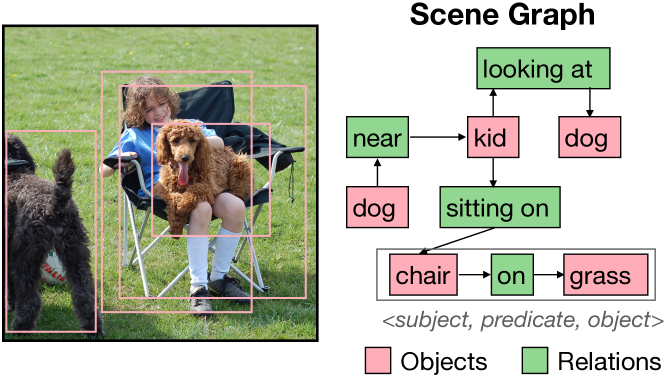
The paper introduces the Continual ScenE Graph Generation (CSEGG) benchmark, which is designed to evaluate the ability of AI models to continuously learn and generate scene graphs from visual inputs. Scene graphs are structured representations that capture the objects, relationships, and attributes present in an image.
The CSEGG benchmark presents a sequence of visual scenes, with new object categories, relationships, and attributes introduced over time. This challenges models to update their understanding of the visual world in an incremental fashion, without forgetting previously learned knowledge. This is in contrast to traditional scene graph generation tasks, which assume a fixed set of elements.
To address the CSEGG benchmark, the authors propose a new model called Adaptive Visual Scene Understanding (AVSU). AVSU uses a combination of techniques, including graph neural networks and transformers, to build and update a scene graph representation. AVSU is designed to efficiently incorporate new knowledge while preserving its existing understanding, enabling continual learning.
The paper presents extensive experiments evaluating AVSU on the CSEGG benchmark, comparing its performance to various baselines. The results demonstrate AVSU's ability to continuously learn and generate accurate scene graphs, outperforming alternative approaches. The authors also provide insights into the strengths and limitations of their model, as well as potential avenues for future research.
Critical Analysis
The CSEGG benchmark and the AVSU model presented in this paper address an important challenge in visual scene understanding – the ability to continuously learn and adapt to new information, rather than being limited to a fixed set of knowledge.
One key strength of this work is the focus on continual learning, which is a crucial capability for AI systems to be truly flexible and adaptable in real-world applications. The CSEGG benchmark provides a well-designed testbed for evaluating models in this context, presenting a more realistic and dynamic scenario than traditional scene graph generation tasks.
However, the paper also acknowledges some limitations of the current approach. For instance, the authors note that AVSU still struggles with certain types of compositional reasoning and long-term memory retention. Additionally, the benchmark may not capture all the nuances and complexities of real-world visual scenes, and further refinements may be needed to make the evaluation more representative.
Future research could explore ways to address these limitations, such as by incorporating more sophisticated memory management techniques or developing richer scene representations. Combining the continual learning approach with other advances in scene understanding, 3D perception, and semantic reasoning could also lead to further improvements.
Overall, the CSEGG benchmark and the AVSU model presented in this paper represent an important step forward in the pursuit of more adaptive and comprehensive visual scene understanding capabilities for AI systems.
Conclusion
This research paper introduces a novel benchmark and model for Continual Scene Graph Generation (CSEGG), which aims to enable AI systems to continuously learn and update their understanding of visual scenes. The CSEGG benchmark presents a sequence of images with new objects, relationships, and attributes introduced over time, challenging models to adapt their scene graph representations accordingly.
To address this benchmark, the authors propose the Adaptive Visual Scene Understanding (AVSU) model, which combines graph neural networks and transformers to incrementally build and refine scene graph representations. Experiments demonstrate AVSU's ability to outperform alternative approaches in continually learning and generating accurate scene graphs.
This work represents a significant advancement in the field of visual scene understanding, as it moves beyond traditional static approaches to enable more flexible and adaptable AI systems. By incorporating continual learning capabilities, the CSEGG benchmark and AVSU model lay the groundwork for AI systems that can more comprehensively and dynamically perceive and describe the visual world, with potential applications in areas like robotics, autonomous driving, and virtual/augmented reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Naitik Khandelwal, Xiao Liu, Mengmi Zhang
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Read more4/15/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024

0
Towards Scene Graph Anticipation
Rohith Peddi, Saksham Singh, Saurabh, Parag Singla, Vibhav Gogate
Spatio-temporal scene graphs represent interactions in a video by decomposing scenes into individual objects and their pair-wise temporal relationships. Long-term anticipation of the fine-grained pair-wise relationships between objects is a challenging problem. To this end, we introduce the task of Scene Graph Anticipation (SGA). We adapt state-of-the-art scene graph generation methods as baselines to anticipate future pair-wise relationships between objects and propose a novel approach SceneSayer. In SceneSayer, we leverage object-centric representations of relationships to reason about the observed video frames and model the evolution of relationships between objects. We take a continuous time perspective and model the latent dynamics of the evolution of object interactions using concepts of NeuralODE and NeuralSDE, respectively. We infer representations of future relationships by solving an Ordinary Differential Equation and a Stochastic Differential Equation, respectively. Extensive experimentation on the Action Genome dataset validates the efficacy of the proposed methods.
Read more7/22/2024
🛸
0
Scene Graph Generation Strategy with Co-occurrence Knowledge and Learnable Term Frequency
Hyeongjin Kim, Sangwon Kim, Dasom Ahn, Jong Taek Lee, Byoung Chul Ko
Scene graph generation (SGG) is an important task in image understanding because it represents the relationships between objects in an image as a graph structure, making it possible to understand the semantic relationships between objects intuitively. Previous SGG studies used a message-passing neural networks (MPNN) to update features, which can effectively reflect information about surrounding objects. However, these studies have failed to reflect the co-occurrence of objects during SGG generation. In addition, they only addressed the long-tail problem of the training dataset from the perspectives of sampling and learning methods. To address these two problems, we propose CooK, which reflects the Co-occurrence Knowledge between objects, and the learnable term frequency-inverse document frequency (TF-l-IDF) to solve the long-tail problem. We applied the proposed model to the SGG benchmark dataset, and the results showed a performance improvement of up to 3.8% compared with existing state-of-the-art models in SGGen subtask. The proposed method exhibits generalization ability from the results obtained, showing uniform performance improvement for all MPNN models.
Read more5/22/2024