An Autoencoder and Generative Adversarial Networks Approach for Multi-Omics Data Imbalanced Class Handling and Classification

0

Sign in to get full access
Overview
- Presents an approach that combines autoencoders and generative adversarial networks (GANs) to address imbalanced class issues in multi-omics data classification.
- Aims to generate synthetic minority class samples to balance the dataset and improve classification performance.
- Utilizes an autoencoder to learn a low-dimensional representation of the multi-omics data, and a GAN to generate synthetic minority class samples.
Plain English Explanation
Multi-omics data refers to the combination of different types of biological data, such as genomics, proteomics, and metabolomics. When working with this data, researchers often encounter the problem of imbalanced classes, where one class (e.g., a disease condition) is much less represented than the other (e.g., healthy individuals). This can make it challenging to train accurate classification models.
The researchers in this study propose a solution that combines two powerful machine learning techniques: autoencoders and generative adversarial networks (GANs). An autoencoder is a type of neural network that can learn a compressed representation of the input data, effectively capturing its key features. The GAN, on the other hand, is a framework that can generate new, synthetic data samples that resemble the original data.
By using an autoencoder to learn the underlying structure of the multi-omics data, the researchers can then feed this learned representation into a GAN. The GAN is then trained to generate additional samples of the minority class, effectively balancing the dataset. This balanced dataset can then be used to train a more accurate classification model, which can better distinguish between the different classes (e.g., disease and healthy).
The key idea is to leverage the strengths of both autoencoders and GANs to overcome the challenge of imbalanced classes in multi-omics data, ultimately leading to more reliable and accurate classification models.
Technical Explanation
The researchers propose a framework that combines an autoencoder and a generative adversarial network (GAN) to address the imbalanced class problem in multi-omics data classification.
First, an autoencoder is used to learn a low-dimensional representation of the multi-omics data. The autoencoder consists of an encoder network that compresses the input data into a lower-dimensional latent space, and a decoder network that reconstructs the original data from the latent representation. By training the autoencoder to minimize the reconstruction error, it learns to capture the essential features of the multi-omics data in the latent space.
Next, the latent representations learned by the autoencoder are used as input to a GAN. The GAN is composed of a generator network and a discriminator network. The generator network is trained to generate synthetic samples that resemble the latent representations of the minority class, while the discriminator network is trained to distinguish between the real (original) and generated (synthetic) latent representations. This adversarial training process allows the generator to produce increasingly realistic synthetic minority class samples, effectively balancing the dataset.
Finally, the balanced dataset, containing both the original and synthetic minority class samples, is used to train a classification model for the multi-omics data. The researchers demonstrate that this approach, which combines autoencoders and GANs, can significantly improve the classification performance compared to using the original imbalanced dataset or other data balancing techniques.
Critical Analysis
The proposed approach presents a promising solution for addressing the imbalanced class problem in multi-omics data classification. The combination of autoencoders and GANs allows for the effective generation of synthetic minority class samples, which can help to improve the overall classification performance.
However, the paper does not provide a comprehensive analysis of the limitations and potential issues with the proposed method. For example, the researchers do not discuss the impact of the quality of the generated synthetic samples on the final classification results, or the computational resources required to train the complex autoencoder-GAN architecture.
Additionally, the authors do not compare their approach to other state-of-the-art techniques for handling imbalanced data, such as oversampling, undersampling, or ensemble methods. A more thorough comparison with these alternative methods could help to better evaluate the strengths and weaknesses of the proposed framework.
Further research could also explore the robustness of the approach to different types of multi-omics data and imbalanced class distributions, as well as investigate ways to improve the stability and convergence of the autoencoder-GAN training process.
Conclusion
This paper presents a novel approach that combines autoencoders and generative adversarial networks (GANs) to address the imbalanced class problem in multi-omics data classification. By using an autoencoder to learn a low-dimensional representation of the data and a GAN to generate synthetic minority class samples, the researchers demonstrate a significant improvement in classification performance compared to the original imbalanced dataset.
The key innovation of this work is the integration of these two powerful machine learning techniques to effectively balance the dataset and train more accurate classification models. This approach has the potential to greatly benefit researchers and clinicians working with multi-omics data, particularly in fields such as disease diagnosis and drug discovery, where accurate classification is crucial.
While the paper provides a solid technical foundation, further research is needed to fully understand the limitations and potential issues with the proposed method, as well as to explore ways to enhance its robustness and computational efficiency. Nevertheless, this study represents an important step forward in addressing the challenges of imbalanced data in the multi-omics domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Autoencoder and Generative Adversarial Networks Approach for Multi-Omics Data Imbalanced Class Handling and Classification
Ibrahim Al-Hurani, Abedalrhman Alkhateeb, Salama Ikki
In the relentless efforts in enhancing medical diagnostics, the integration of state-of-the-art machine learning methodologies has emerged as a promising research area. In molecular biology, there has been an explosion of data generated from multi-omics sequencing. The advent sequencing equipment can provide large number of complicated measurements per one experiment. Therefore, traditional statistical methods face challenging tasks when dealing with such high dimensional data. However, most of the information contained in these datasets is redundant or unrelated and can be effectively reduced to significantly fewer variables without losing much information. Dimensionality reduction techniques are mathematical procedures that allow for this reduction; they have largely been developed through statistics and machine learning disciplines. The other challenge in medical datasets is having an imbalanced number of samples in the classes, which leads to biased results in machine learning models. This study, focused on tackling these challenges in a neural network that incorporates autoencoder to extract latent space of the features, and Generative Adversarial Networks (GAN) to generate synthetic samples. Latent space is the reduced dimensional space that captures the meaningful features of the original data. Our model starts with feature selection to select the discriminative features before feeding them to the neural network. Then, the model predicts the outcome of cancer for different datasets. The proposed model outperformed other existing models by scoring accuracy of 95.09% for bladder cancer dataset and 88.82% for the breast cancer dataset.
Read more5/17/2024
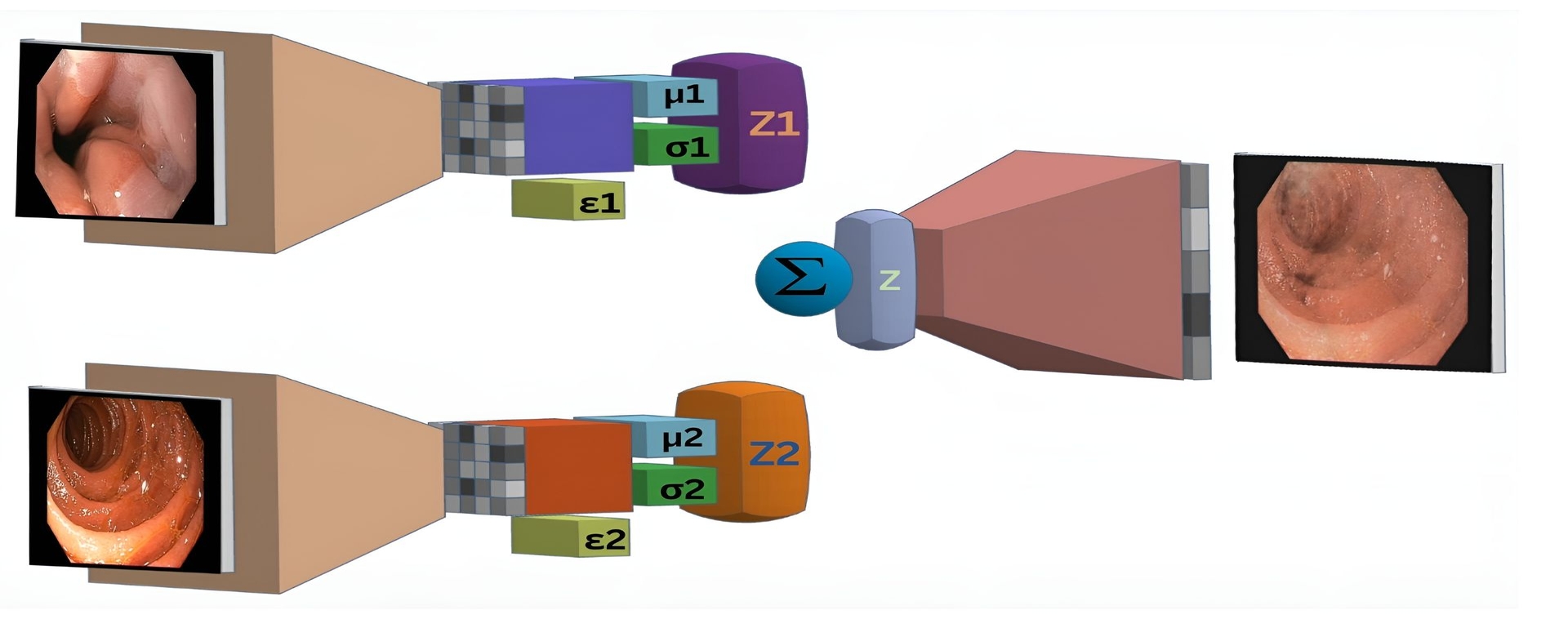
0
Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation
Neil De La Fuente, Mireia Maj'o, Irina Luzko, Henry C'ordova, Gloria Fern'andez-Esparrach, Jorge Bernal
Accurate and robust medical image classification is a challenging task, especially in application domains where available annotated datasets are small and present high imbalance between target classes. Considering that data acquisition is not always feasible, especially for underrepresented classes, our approach introduces a novel synthetic augmentation strategy using class-specific Variational Autoencoders (VAEs) and latent space interpolation to improve discrimination capabilities. By generating realistic, varied synthetic data that fills feature space gaps, we address issues of data scarcity and class imbalance. The method presented in this paper relies on the interpolation of latent representations within each class, thus enriching the training set and improving the model's generalizability and diagnostic accuracy. The proposed strategy was tested in a small dataset of 321 images created to train and validate an automatic method for assessing the quality of cleanliness of esophagogastroduodenoscopy images. By combining real and synthetic data, an increase of over 18% in the accuracy of the most challenging underrepresented class was observed. The proposed strategy not only benefited the underrepresented class but also led to a general improvement in other metrics, including a 6% increase in global accuracy and precision.
Read more9/17/2024

0
LatentQGAN: A Hybrid QGAN with Classical Convolutional Autoencoder
Vieloszynski Alexis, Soumaya Cherkaoui, Jean-Fr'ed'eric Laprade, Oliver Nahman-L'evesque, Abdallah Aaraba, Shengrui Wang
Quantum machine learning consists in taking advantage of quantum computations to generate classical data. A potential application of quantum machine learning is to harness the power of quantum computers for generating classical data, a process essential to a multitude of applications such as enriching training datasets, anomaly detection, and risk management in finance. Given the success of Generative Adversarial Networks in classical image generation, the development of its quantum versions has been actively conducted. However, existing implementations on quantum computers often face significant challenges, such as scalability and training convergence issues. To address these issues, we propose LatentQGAN, a novel quantum model that uses a hybrid quantum-classical GAN coupled with an autoencoder. Although it was initially designed for image generation, the LatentQGAN approach holds potential for broader application across various practical data generation tasks. Experimental outcomes on both classical simulators and noisy intermediate scale quantum computers have demonstrated significant performance enhancements over existing quantum methods, alongside a significant reduction in quantum resources overhead.
Read more9/24/2024
📊
0
Enhancing Medical Imaging with GANs Synthesizing Realistic Images from Limited Data
Yinqiu Feng, Bo Zhang, Lingxi Xiao, Yutian Yang, Tana Gegen, Zexi Chen
In this research, we introduce an innovative method for synthesizing medical images using generative adversarial networks (GANs). Our proposed GANs method demonstrates the capability to produce realistic synthetic images even when trained on a limited quantity of real medical image data, showcasing commendable generalization prowess. To achieve this, we devised a generator and discriminator network architecture founded on deep convolutional neural networks (CNNs), leveraging the adversarial training paradigm for model optimization. Through extensive experimentation across diverse medical image datasets, our method exhibits robust performance, consistently generating synthetic images that closely emulate the structural and textural attributes of authentic medical images.
Read more6/28/2024