Exploring Diverse Methods in Visual Question Answering
2404.13565
0
0
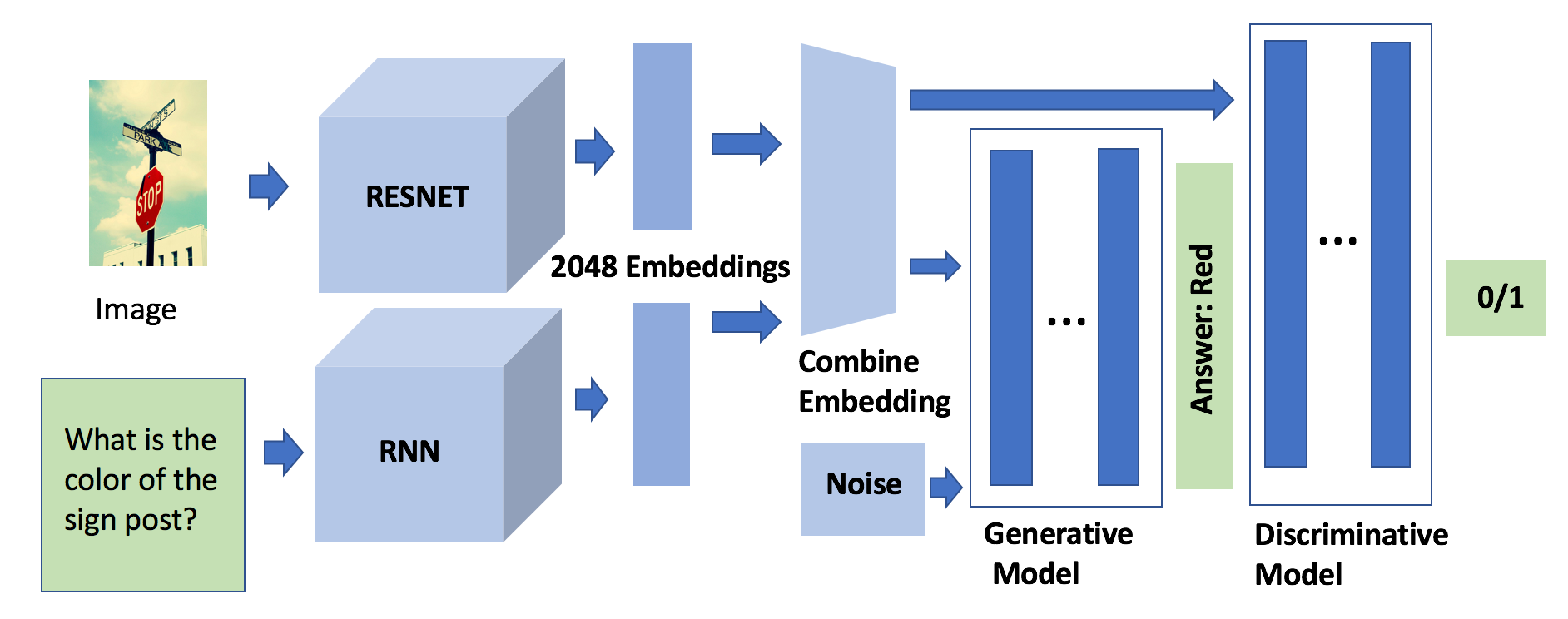
Abstract
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
Create account to get full access
Overview
- The paper explores diverse methods for improving visual question answering (VQA), a task that involves answering questions about images.
- The authors investigate techniques like generative adversarial networks (GANs), autoencoders, and attention mechanisms to enhance VQA performance.
- The paper aims to provide insights into effective approaches for building more capable VQA systems.
Plain English Explanation
Visual question answering (VQA) is a task where a computer system is shown an image and asked a question about it, and the system has to provide the correct answer. This is a challenging problem that requires understanding both the visual information in the image and the semantic meaning of the question.
The researchers in this paper explore various advanced machine learning techniques to improve the performance of VQA systems. They investigate using generative adversarial networks (GANs), which are a type of AI model that can generate realistic-looking images. They also look at autoencoders, which are models that can learn efficient representations of data, and attention mechanisms, which allow AI systems to focus on the most relevant parts of an image or question when formulating an answer.
By experimenting with these diverse methods, the researchers aim to gain insights into what approaches work best for building more capable and reliable VQA systems. Their findings could help advance the state-of-the-art in this important area of AI and computer vision.
Technical Explanation
The paper investigates several advanced techniques for enhancing visual question answering (VQA) performance.
One key approach explored is the use of generative adversarial networks (GANs). The authors propose a GAN-based mechanism that can generate diverse answers to visual questions, going beyond the typical single-answer VQA setup. This allows the system to provide a richer set of possible responses, which can improve overall VQA accuracy.
The researchers also investigate the role of autoencoders in VQA. Autoencoders are used to learn compact representations of the visual and textual inputs, which can then be effectively combined to produce answers. This representation learning component is shown to boost VQA performance.
Additionally, the paper explores the use of attention mechanisms, which enable the VQA model to focus on the most relevant parts of the image and question when generating an answer. This selective attention is demonstrated to improve the system's reasoning and answer prediction capabilities.
Through extensive experiments on benchmark VQA datasets, the authors provide insights into the relative merits of these diverse techniques. They find that the combination of GAN-based answer generation, autoencoder-based representation learning, and attention-guided reasoning leads to state-of-the-art VQA performance.
Critical Analysis
The paper presents a thorough investigation of various advanced methods for enhancing visual question answering (VQA), and the findings provide valuable insights for the research community.
However, the authors acknowledge certain limitations of their work. For example, they note that the GAN-based answer generation approach may struggle with generating diverse yet plausible responses, and that further research is needed to address this issue. Additionally, the attention mechanisms used in the paper, while effective, may not fully capture the complex relationships between visual and textual elements in VQA.
Another potential concern is the reliance on benchmark datasets, which may not fully reflect the challenges of real-world VQA scenarios. Further research exploring the performance of these techniques in more diverse and realistic settings would be valuable.
Additionally, the paper does not address the potential biases and fairness issues that can arise in VQA systems, which is an important consideration for real-world deployments. Incorporating fairness and explainability into the proposed methods could enhance their practical relevance.
Conclusion
This paper presents a comprehensive exploration of diverse methods for improving visual question answering (VQA) performance. The authors investigate the use of generative adversarial networks, autoencoders, and attention mechanisms, and demonstrate their effectiveness in boosting VQA accuracy.
The findings provide valuable insights into the relative strengths and limitations of these techniques, and could inform the development of more advanced and capable VQA systems. As the field of AI continues to advance, the insights gained from this research could contribute to the creation of VQA models that are more robust, reliable, and aligned with real-world needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Optimizing Visual Question Answering Models for Driving: Bridging the Gap Between Human and Machine Attention Patterns
Kaavya Rekanar, Martin Hayes, Ganesh Sistu, Ciaran Eising
0
0
Visual Question Answering (VQA) models play a critical role in enhancing the perception capabilities of autonomous driving systems by allowing vehicles to analyze visual inputs alongside textual queries, fostering natural interaction and trust between the vehicle and its occupants or other road users. This study investigates the attention patterns of humans compared to a VQA model when answering driving-related questions, revealing disparities in the objects observed. We propose an approach integrating filters to optimize the model's attention mechanisms, prioritizing relevant objects and improving accuracy. Utilizing the LXMERT model for a case study, we compare attention patterns of the pre-trained and Filter Integrated models, alongside human answers using images from the NuImages dataset, gaining insights into feature prioritization. We evaluated the models using a Subjective scoring framework which shows that the integration of the feature encoder filter has enhanced the performance of the VQA model by refining its attention mechanisms.
6/14/2024
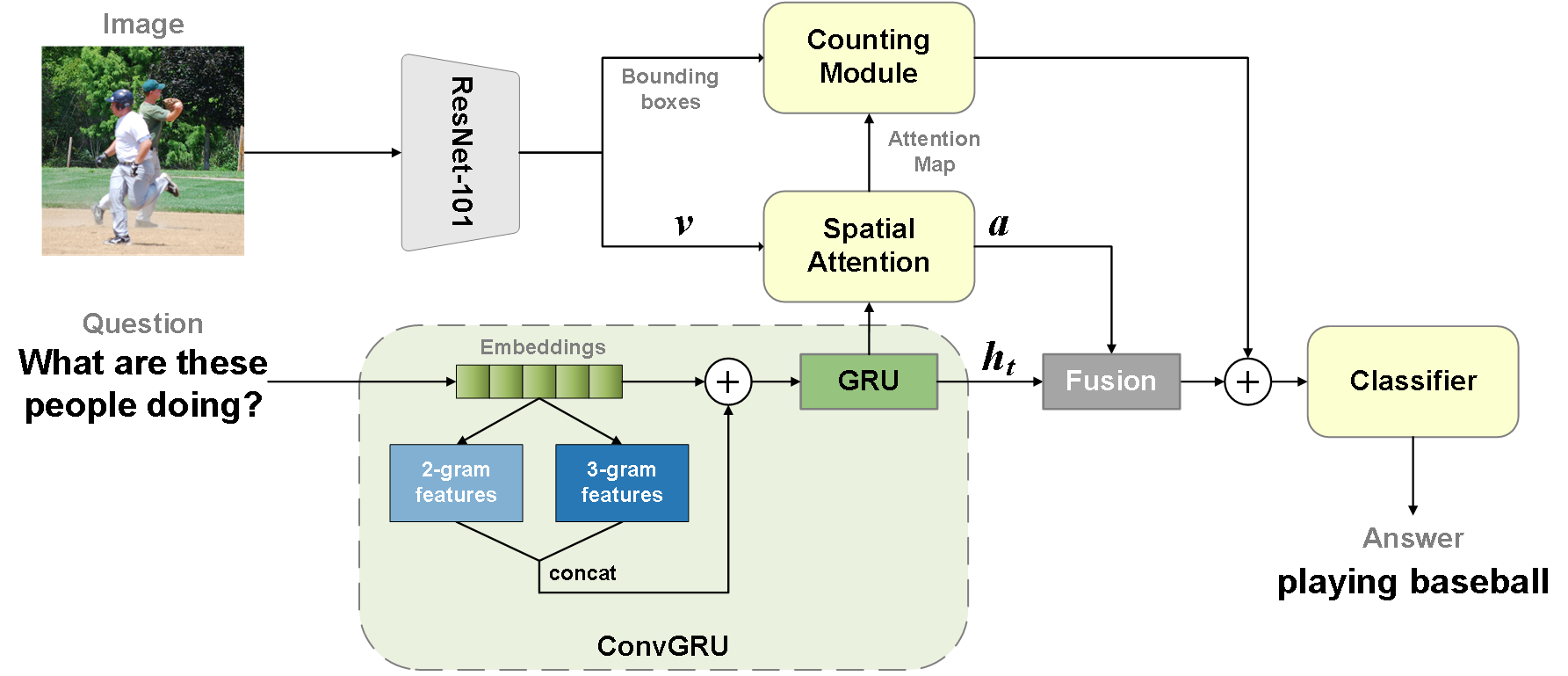
Enhanced Visual Question Answering: A Comparative Analysis and Textual Feature Extraction Via Convolutions
Zhilin Zhang
0
0
Visual Question Answering (VQA) has emerged as a highly engaging field in recent years, attracting increasing research efforts aiming to enhance VQA accuracy through the deployment of advanced models such as Transformers. Despite this growing interest, there has been limited exploration into the comparative analysis and impact of textual modalities within VQA, particularly in terms of model complexity and its effect on performance. In this work, we conduct a comprehensive comparison between complex textual models that leverage long dependency mechanisms and simpler models focusing on local textual features within a well-established VQA framework. Our findings reveal that employing complex textual encoders is not invariably the optimal approach for the VQA-v2 dataset. Motivated by this insight, we introduce an improved model, ConvGRU, which incorporates convolutional layers to enhance the representation of question text. Tested on the VQA-v2 dataset, ConvGRU achieves better performance without substantially increasing parameter complexity.
5/2/2024

Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Ovgu Ozdemir, Erdem Akagunduz
0
0
Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at url{https://github.com/ovguyo/captions-in-VQA}.
4/15/2024

Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
0
0
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
6/17/2024