Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation

0
Sign in to get full access
Overview
- This paper explores the use of synthetic data augmentation to improve image classification performance on small and unbalanced datasets.
- The authors propose a Variational Autoencoder (VAE) based approach to generate diverse and realistic synthetic images that can be used to supplement the original training data.
- Experiments on real-world datasets, including an esophagogastroduodenoscopy (EGD) image classification task, demonstrate the effectiveness of the synthetic data augmentation technique.
Plain English Explanation
When training machine learning models, it's important to have a large and balanced dataset to achieve good performance. However, in many real-world scenarios, the available data may be limited or unevenly distributed across different classes. This can make it challenging for the model to learn effectively and generalize well.
To address this issue, the researchers in this paper explored the use of synthetic data augmentation. The idea is to use a special type of machine learning model called a Variational Autoencoder (VAE) to generate new, realistic-looking images that can be added to the original training dataset.
The VAE is trained on the existing images and learns to capture the underlying patterns and characteristics of the data. It can then be used to generate new, similar-looking images that fill in the gaps in the original dataset. By combining the real and synthetic images during training, the machine learning model can learn more robust and generalized features, leading to improved performance on the image classification task.
The researchers tested their approach on several real-world datasets, including a medical imaging task involving esophagogastroduodenoscopy (EGD) images. The results showed that the synthetic data augmentation technique was effective in enhancing the image classification accuracy, especially when the original dataset was small and imbalanced.
Technical Explanation
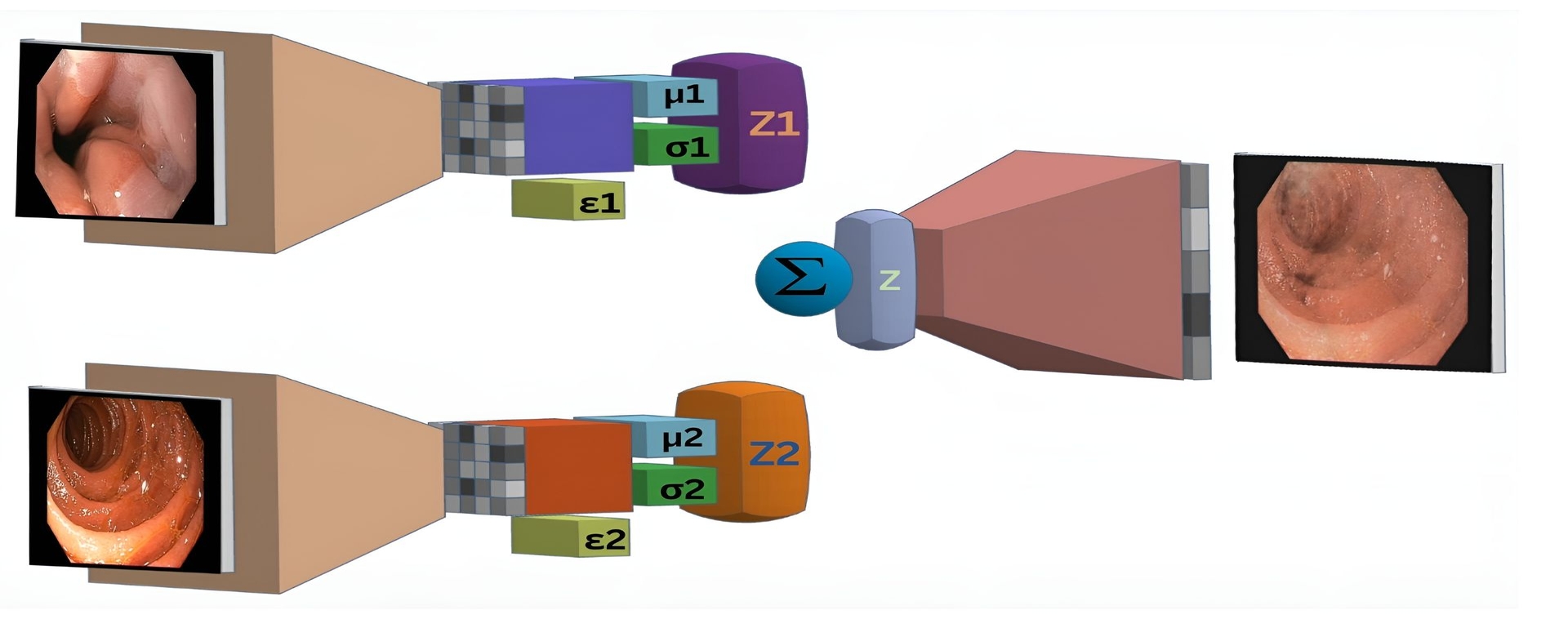
The paper proposes a Synthetic Data Augmentation (SDA) approach based on a Variational Autoencoder (VAE) to address the challenges of small and unbalanced datasets in image classification tasks.
The key components of the proposed method are:
-
VAE Architecture: The authors design a VAE model that takes in the original images and learns to capture their underlying patterns and characteristics. The VAE consists of an encoder network that compresses the input image into a low-dimensional latent representation, and a decoder network that reconstructs the image from the latent representation.
-
Synthetic Image Generation: Once the VAE is trained on the original dataset, it can be used to generate new, synthetic images. The researchers do this by sampling from the learned latent distribution and passing the samples through the decoder network to obtain the corresponding synthetic images.
-
Data Augmentation: The generated synthetic images are then combined with the original training data to create an augmented dataset. This augmented dataset is used to train the final image classification model, which can be any standard convolutional neural network (CNN) architecture.
The researchers evaluate their approach on several datasets, including the esophagogastroduodenoscopy (EGD) image classification task. They compare the performance of the CNN model trained on the original dataset, the CNN model trained on the augmented dataset, and other state-of-the-art data augmentation techniques.
The results demonstrate that the proposed SDA approach using the VAE-generated synthetic images consistently outperforms the baseline models, especially when the original dataset is small and imbalanced. This highlights the effectiveness of the synthetic data augmentation technique in enhancing image classification performance in challenging scenarios.
Critical Analysis
The paper presents a compelling approach to address the common challenge of limited and imbalanced datasets in image classification tasks. The use of a VAE to generate realistic synthetic images is a well-designed solution, as it allows for the creation of diverse and representative samples that can supplement the original training data.
One potential limitation of the study is the reliance on a single CNN architecture for the final image classification model. It would be valuable to assess the performance of the SDA approach with different CNN architectures or other types of classifiers to better understand its broader applicability.
Additionally, the paper could have provided more insights into the characteristics of the generated synthetic images and their impact on the final model's performance. Analyzing the distribution, diversity, and fidelity of the synthetic data compared to the real data could shed light on the mechanisms behind the observed improvements.
Further research could also explore the generalization of the SDA approach to other domains beyond image classification, such as natural language processing or time series analysis, where data scarcity and imbalance are also common challenges.
Conclusion
This paper presents a novel Synthetic Data Augmentation (SDA) approach based on a Variational Autoencoder (VAE) to enhance image classification performance on small and unbalanced datasets. The key idea is to leverage the VAE's ability to generate diverse and realistic synthetic images, which are then combined with the original training data to improve the final classification model.
The results demonstrate the effectiveness of the proposed SDA technique, particularly in scenarios where the available dataset is limited and unevenly distributed across classes. This work contributes to the ongoing efforts in the machine learning community to address data challenges and improve the robustness and generalization of image classification models.
The insights and methodology presented in this paper could inspire further research into synthetic data generation and its application to a broader range of machine learning problems, ultimately leading to more efficient and reliable models that can be deployed in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Enhancing Image Classification in Small and Unbalanced Datasets through Synthetic Data Augmentation
Neil De La Fuente, Mireia Maj'o, Irina Luzko, Henry C'ordova, Gloria Fern'andez-Esparrach, Jorge Bernal
Accurate and robust medical image classification is a challenging task, especially in application domains where available annotated datasets are small and present high imbalance between target classes. Considering that data acquisition is not always feasible, especially for underrepresented classes, our approach introduces a novel synthetic augmentation strategy using class-specific Variational Autoencoders (VAEs) and latent space interpolation to improve discrimination capabilities. By generating realistic, varied synthetic data that fills feature space gaps, we address issues of data scarcity and class imbalance. The method presented in this paper relies on the interpolation of latent representations within each class, thus enriching the training set and improving the model's generalizability and diagnostic accuracy. The proposed strategy was tested in a small dataset of 321 images created to train and validate an automatic method for assessing the quality of cleanliness of esophagogastroduodenoscopy images. By combining real and synthetic data, an increase of over 18% in the accuracy of the most challenging underrepresented class was observed. The proposed strategy not only benefited the underrepresented class but also led to a general improvement in other metrics, including a 6% increase in global accuracy and precision.
Read more9/17/2024

0
Improving SMOTE via Fusing Conditional VAE for Data-adaptive Noise Filtering
Sungchul Hong, Seunghwan An, Jong-June Jeon
Recent advances in a generative neural network model extend the development of data augmentation methods. However, the augmentation methods based on the modern generative models fail to achieve notable performance for class imbalance data compared to the conventional model, Synthetic Minority Oversampling Technique (SMOTE). We investigate the problem of the generative model for imbalanced classification and introduce a framework to enhance the SMOTE algorithm using Variational Autoencoders (VAE). Our approach systematically quantifies the density of data points in a low-dimensional latent space using the VAE, simultaneously incorporating information on class labels and classification difficulty. Then, the data points potentially degrading the augmentation are systematically excluded, and the neighboring observations are directly augmented on the data space. Empirical studies on several imbalanced datasets represent that this simple process innovatively improves the conventional SMOTE algorithm over the deep learning models. Consequently, we conclude that the selection of minority data and the interpolation in the data space are beneficial for imbalanced classification problems with a relatively small number of data points.
Read more8/27/2024

0
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
Quang-Huy Che, Duc-Tri Le, Vinh-Tiep Nguyen
Data augmentation is a widely used technique for creating training data for tasks that require labeled data, such as semantic segmentation. This method benefits pixel-wise annotation tasks requiring much effort and intensive labor. Traditional data augmentation methods involve simple transformations like rotations and flips to create new images from existing ones. However, these new images may lack diversity along the main semantic axes in the data and not change high-level semantic properties. To address this issue, generative models have emerged as an effective solution for augmenting data by generating synthetic images. Controllable generative models offer a way to augment data for semantic segmentation tasks using a prompt and visual reference from the original image. However, using these models directly presents challenges, such as creating an effective prompt and visual reference to generate a synthetic image that accurately reflects the content and structure of the original. In this work, we introduce an effective data augmentation method for semantic segmentation using the Controllable Diffusion Model. Our proposed method includes efficient prompt generation using Class-Prompt Appending and Visual Prior Combination to enhance attention to labeled classes in real images. These techniques allow us to generate images that accurately depict segmented classes in the real image. In addition, we employ the class balancing algorithm to ensure efficiency when merging the synthetic and original images to generate balanced data for the training dataset. We evaluated our method on the PASCAL VOC datasets and found it highly effective for synthesizing images in semantic segmentation.
Read more9/14/2024
0
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Qikai Yang, Panfeng Li, Xinhe Xu, Zhicheng Ding, Wenjing Zhou, Yi Nian
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Read more9/17/2024