Automated Molecular Concept Generation and Labeling with Large Language Models

0
Sign in to get full access
Overview
- This paper presents a method for automatically generating and labeling molecular concepts using large language models (LLMs).
- The researchers demonstrate that LLMs can be used to discover new molecular concepts and associate them with human-interpretable labels, without requiring prior domain knowledge or extensive datasets.
- The proposed approach has the potential to accelerate scientific discovery and enable more transparent and explainable molecular modeling.
Plain English Explanation
Large language models (LLMs) are AI systems that have been trained on vast amounts of text data, allowing them to understand and generate human-like language. In this paper, the researchers show how these powerful models can be used to automatically discover and describe new molecular concepts.
Traditionally, understanding the chemical properties of molecules has required extensive domain expertise and large experimental datasets. However, the researchers found that LLMs can be leveraged to generate meaningful molecular concepts and associate them with easy-to-understand labels, without needing to explicitly program these relationships.
For example, an LLM might learn that certain molecular structures are associated with "anti-inflammatory" or "cancer-fighting" properties, and be able to generate new molecules that share these desirable characteristics. By making these connections explicit, the approach could accelerate scientific discovery and lead to more transparent and explainable molecular modeling.
Technical Explanation
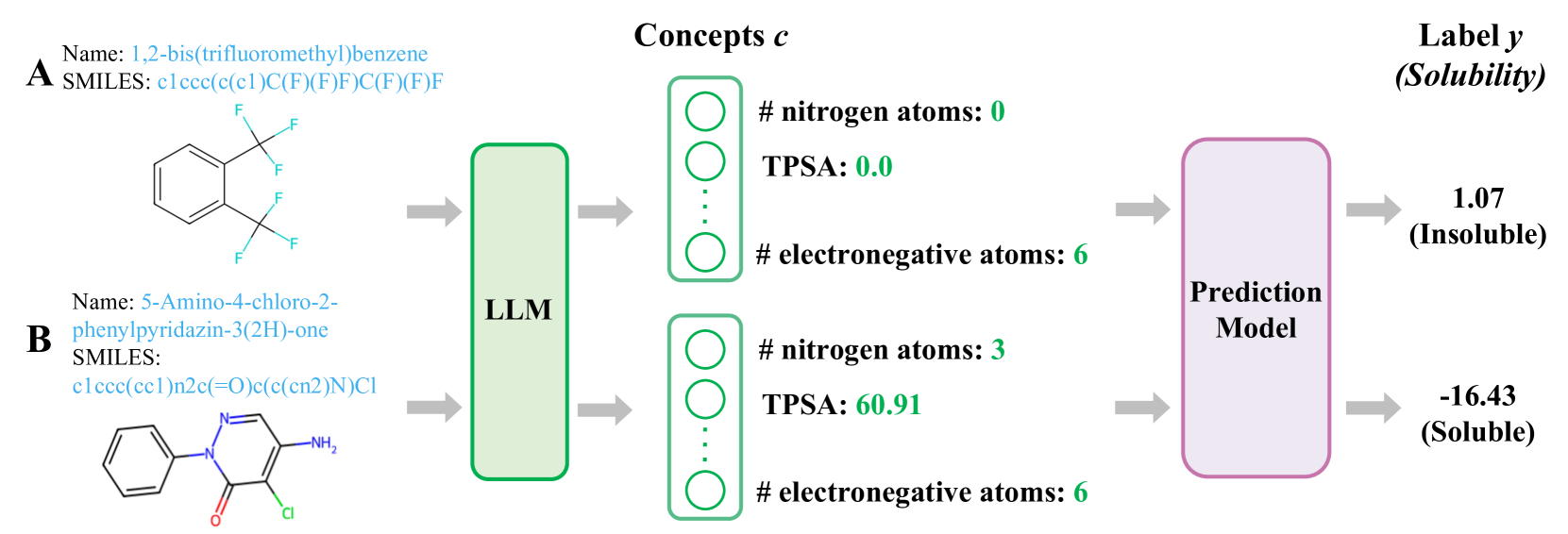
The researchers developed a novel framework for Automated Molecular Concept Generation and Labeling with Large Language Models. They first trained an LLM on a large corpus of scientific literature related to chemistry and molecular biology. They then used this pre-trained model to generate new molecular concepts and associated them with human-interpretable labels.
The key innovation was a two-stage process:
- Concept Generation: The LLM was prompted to generate novel molecular concepts, expressed as free-text descriptions.
- Concept Labeling: A separate model was trained to map these free-text concepts to a set of predefined labels, drawn from a domain-specific ontology.
By combining these stages, the researchers were able to automatically discover new molecular ideas and provide intuitive names for them, without requiring manual curation or extensive domain expertise.
The researchers evaluated their approach through both automated metrics and user studies, demonstrating that the generated concepts were meaningful and the associated labels were generally accurate. This work shows the potential for LLMs to synergize with automated machine learning and enhance molecular learning tasks.
Critical Analysis
The paper presents a compelling approach for automating the discovery and description of molecular concepts using LLMs. However, the researchers acknowledge several caveats and limitations:
-
Dataset Quality: The performance of the concept generation and labeling models is heavily dependent on the quality and coverage of the training data. Gaps or biases in the literature could lead to incomplete or inaccurate concept discovery.
-
Label Ambiguity: While the predefined labels provide human-interpretable names for the concepts, there can be ambiguity in how these labels are defined and applied. Further work is needed to ensure the labels are unambiguous and align with domain expert understanding.
-
Generalization Ability: The experiments focused on a specific domain of organic chemistry. It remains to be seen how well the approach can generalize to other areas of chemistry or broader scientific domains.
-
Robustness to Noise: The paper does not address how the models would perform in the face of noisy or incomplete inputs, which is a common challenge in real-world applications.
Overall, this work demonstrates the potential for LLMs to automate aspects of the scientific discovery process. However, further research is needed to address the identified limitations and ensure the approach is reliable and scalable for practical use.
Conclusion
This paper presents a novel framework for automatically generating and labeling molecular concepts using large language models. By leveraging the language understanding capabilities of LLMs, the researchers were able to discover new molecular ideas and associate them with human-interpretable labels, without requiring extensive domain expertise or datasets.
The proposed approach has the potential to accelerate scientific discovery and lead to more transparent and explainable molecular modeling. While the current work has some limitations, it represents an important step towards enabling AI systems to assist and augment human researchers in the exploration of the chemical universe.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automated Molecular Concept Generation and Labeling with Large Language Models
Shichang Zhang, Botao Xia, Zimin Zhang, Qianli Wu, Fang Sun, Ziniu Hu, Yizhou Sun
Artificial intelligence (AI) is significantly transforming scientific research. Explainable AI methods, such as concept-based models (CMs), are promising for driving new scientific discoveries because they make predictions based on meaningful concepts and offer insights into the prediction process. In molecular science, however, explainable CMs are not as common compared to black-box models like Graph Neural Networks (GNNs), primarily due to their requirement for predefined concepts and manual label for each instance, which demand domain knowledge and can be labor-intensive. This paper introduces a novel framework for Automated Molecular Concept (AutoMolCo) generation and labeling. AutoMolCo leverages the knowledge in Large Language Models (LLMs) to automatically generate predictive molecular concepts and label them for each molecule. Such procedures are repeated through iterative interactions with LLMs to refine concepts, enabling simple linear models on the refined concepts to outperform GNNs and LLM in-context learning on several benchmarks. The whole AutoMolCo framework is automated without any human knowledge inputs in either concept generation, labeling, or refinement, thereby surpassing the limitations of extant CMs while maintaining their explainability and allowing easy intervention. Through systematic experiments on MoleculeNet and High-Throughput Experimentation (HTE) datasets, we demonstrate that the AutoMolCo-induced explainable CMs are beneficial and promising for molecular science research.
Read more6/17/2024

0
Concept Induction using LLMs: a user experiment for assessment
Adrita Barua, Cara Widmer, Pascal Hitzler
Explainable Artificial Intelligence (XAI) poses a significant challenge in providing transparent and understandable insights into complex AI models. Traditional post-hoc algorithms, while useful, often struggle to deliver interpretable explanations. Concept-based models offer a promising avenue by incorporating explicit representations of concepts to enhance interpretability. However, existing research on automatic concept discovery methods is often limited by lower-level concepts, costly human annotation requirements, and a restricted domain of background knowledge. In this study, we explore the potential of a Large Language Model (LLM), specifically GPT-4, by leveraging its domain knowledge and common-sense capability to generate high-level concepts that are meaningful as explanations for humans, for a specific setting of image classification. We use minimal textual object information available in the data via prompting to facilitate this process. To evaluate the output, we compare the concepts generated by the LLM with two other methods: concepts generated by humans and the ECII heuristic concept induction system. Since there is no established metric to determine the human understandability of concepts, we conducted a human study to assess the effectiveness of the LLM-generated concepts. Our findings indicate that while human-generated explanations remain superior, concepts derived from GPT-4 are more comprehensible to humans compared to those generated by ECII.
Read more9/24/2024

0
A Review of Large Language Models and Autonomous Agents in Chemistry
Mayk Caldas Ramos, Christopher J. Collison, Andrew D. White
Large language models (LLMs) have emerged as powerful tools in chemistry, significantly impacting molecule design, property prediction, and synthesis optimization. This review highlights LLM capabilities in these domains and their potential to accelerate scientific discovery through automation. We also review LLM-based autonomous agents: LLMs with a broader set of tools to interact with their surrounding environment. These agents perform diverse tasks such as paper scraping, interfacing with automated laboratories, and synthesis planning. As agents are an emerging topic, we extend the scope of our review of agents beyond chemistry and discuss across any scientific domains. This review covers the recent history, current capabilities, and design of LLMs and autonomous agents, addressing specific challenges, opportunities, and future directions in chemistry. Key challenges include data quality and integration, model interpretability, and the need for standard benchmarks, while future directions point towards more sophisticated multi-modal agents and enhanced collaboration between agents and experimental methods. Due to the quick pace of this field, a repository has been built to keep track of the latest studies: https://github.com/ur-whitelab/LLMs-in-science.
Read more7/29/2024
0
Explainable Molecular Property Prediction: Aligning Chemical Concepts with Predictions via Language Models
Zhenzhong Wang, Zehui Lin, Wanyu Lin, Ming Yang, Minggang Zeng, Kay Chen Tan
Providing explainable molecule property predictions is critical for many scientific domains, such as drug discovery and material science. Though transformer-based language models have shown great potential in accurate molecular property prediction, they neither provide chemically meaningful explanations nor faithfully reveal the molecular structure-property relationships. In this work, we develop a new framework for explainable molecular property prediction based on language models, dubbed as Lamole, which can provide chemical concepts-aligned explanations. We first leverage a designated molecular representation -- the Group SELFIES -- as it can provide chemically meaningful semantics. Because attention mechanisms in Transformers can inherently capture relationships within the input, we further incorporate the attention weights and gradients together to generate explanations for capturing the functional group interactions. We then carefully craft a marginal loss to explicitly optimize the explanations to be able to align with the chemists' annotations. We bridge the manifold hypothesis with the elaborated marginal loss to prove that the loss can align the explanations with the tangent space of the data manifold, leading to concept-aligned explanations. Experimental results over six mutagenicity datasets and one hepatotoxicity dataset demonstrate Lamole can achieve comparable classification accuracy and boost the explanation accuracy by up to 14.8%, being the state-of-the-art in explainable molecular property prediction.
Read more6/4/2024