Automatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network

0
🌐
Sign in to get full access
Overview
- Automatic assessment of dysarthria, a speech disorder, remains a challenging task due to the high variability in acoustic signals and limited data available.
- Current research focuses on two main approaches: using expert-designed features combined with machine learning, and employing data-driven deep learning methods to extract representations.
- The paper proposes a novel approach that integrates the strengths of expert features and deep learning to construct a neural network architecture for improved interpretability and assessment performance.
Plain English Explanation
The paper addresses the challenge of automatically assessing dysarthria, a speech disorder that can affect people's ability to speak clearly. Assessing dysarthria is difficult because the sounds people with this condition make can vary a lot, and there isn't much data available to train computer systems to recognize the patterns.
Researchers have tried two main approaches so far: using expert-designed features combined with machine learning, and using deep learning methods to automatically extract relevant features from the data. Expert features are good at representing the unique characteristics of pathological speech, while deep learning can uncover hidden patterns in the data.
The paper proposes a new method that combines the strengths of both approaches. It uses a neural network architecture that incorporates expert knowledge about the structure of vowel sounds, as well as deep learning techniques to automatically learn relevant features from the audio and visual information. The goal is to create a system that is both interpretable (easy to understand) and effective at assessing dysarthria.
Technical Explanation
The paper presents a vowel graph attention network that integrates expert knowledge and deep learning to improve the automatic assessment of dysarthria.
Firstly, the model combines various expert-designed acoustic features and deep learning-based pre-trained representations as inputs. This allows the system to leverage both the known characteristics of pathological speech and the latent patterns discovered through data-driven approaches.
Secondly, the researchers designed a graph network structure based on vowel space theory. This allows the model to deeply explore the spatial correlations between different vowel sounds, which are crucial for understanding speech disorders like dysarthria.
Finally, the researchers incorporated visual information (e.g., facial movements) into the model to further enhance its robustness and generalizability. [Audio-visual integration has been shown to be effective for other speech-related tasks](https://aimodels.fyi/papers/arxiv/av2wav-diffusion-based-re-synthesis-from-continuous, https://aimodels.fyi/papers/arxiv/dynamic-cross-attention-audio-visual-person-verification).
The proposed method exhibited superior performance in regression experiments targeting the Frenchay assessment scores, which are commonly used to evaluate dysarthria, compared to existing approaches.
Critical Analysis
The paper presents a well-designed approach that effectively combines expert knowledge and deep learning to tackle the challenging task of automatic dysarthria assessment. By incorporating both acoustic features and visual information, the model is able to capture a more comprehensive representation of the speech disorder.
One potential limitation of the research is the reliance on the Frenchay assessment scores as the sole evaluation metric. While these scores are widely used, they may not fully capture all the nuances of dysarthria. Evaluating the model's performance on other assessment criteria or in real-world clinical settings could provide additional insights.
Furthermore, the paper does not discuss the interpretability of the model's decision-making process. Interpretability is an important consideration for clinical applications, as healthcare professionals may need to understand the reasoning behind the model's assessments. Exploring ways to enhance the interpretability of the proposed approach could be a valuable area for future research.
Overall, the paper presents a promising step forward in the field of automatic dysarthria assessment and highlights the potential benefits of integrating expert knowledge and deep learning techniques.
Conclusion
The paper proposes a novel vowel graph attention network that effectively combines expert-designed features and deep learning-based representations to improve the automatic assessment of dysarthria, a speech disorder. By incorporating both acoustic and visual information, and leveraging the strengths of expert knowledge and data-driven approaches, the model demonstrates superior performance compared to existing methods.
This research highlights the potential of integrating domain expertise and advanced machine learning techniques to tackle complex healthcare problems. The proposed approach could have important implications for the development of more accurate and interpretable tools for the assessment and management of speech disorders, ultimately improving patient care and outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Automatic Assessment of Dysarthria Using Audio-visual Vowel Graph Attention Network
Xiaokang Liu, Xiaoxia Du, Juan Liu, Rongfeng Su, Manwa Lawrence Ng, Yumei Zhang, Yudong Yang, Shaofeng Zhao, Lan Wang, Nan Yan
Automatic assessment of dysarthria remains a highly challenging task due to high variability in acoustic signals and the limited data. Currently, research on the automatic assessment of dysarthria primarily focuses on two approaches: one that utilizes expert features combined with machine learning, and the other that employs data-driven deep learning methods to extract representations. Research has demonstrated that expert features are effective in representing pathological characteristics, while deep learning methods excel at uncovering latent features. Therefore, integrating the advantages of expert features and deep learning to construct a neural network architecture based on expert knowledge may be beneficial for interpretability and assessment performance. In this context, the present paper proposes a vowel graph attention network based on audio-visual information, which effectively integrates the strengths of expert knowledges and deep learning. Firstly, various features were combined as inputs, including knowledge based acoustical features and deep learning based pre-trained representations. Secondly, the graph network structure based on vowel space theory was designed, allowing for a deep exploration of spatial correlations among vowels. Finally, visual information was incorporated into the model to further enhance its robustness and generalizability. The method exhibited superior performance in regression experiments targeting Frenchay scores compared to existing approaches.
Read more5/8/2024

0
Developing vocal system impaired patient-aimed voice quality assessment approach using ASR representation-included multiple features
Shaoxiang Dang, Tetsuya Matsumoto, Yoshinori Takeuchi, Takashi Tsuboi, Yasuhiro Tanaka, Daisuke Nakatsubo, Satoshi Maesawa, Ryuta Saito, Masahisa Katsuno, Hiroaki Kudo
The potential of deep learning in clinical speech processing is immense, yet the hurdles of limited and imbalanced clinical data samples loom large. This article addresses these challenges by showcasing the utilization of automatic speech recognition and self-supervised learning representations, pre-trained on extensive datasets of normal speech. This innovative approach aims to estimate voice quality of patients with impaired vocal systems. Experiments involve checks on PVQD dataset, covering various causes of vocal system damage in English, and a Japanese dataset focusing on patients with Parkinson's disease before and after undergoing subthalamic nucleus deep brain stimulation (STN-DBS) surgery. The results on PVQD reveal a notable correlation (>0.8 on PCC) and an extraordinary accuracy (<0.5 on MSE) in predicting Grade, Breathy, and Asthenic indicators. Meanwhile, progress has been achieved in predicting the voice quality of patients in the context of STN-DBS.
Read more8/23/2024
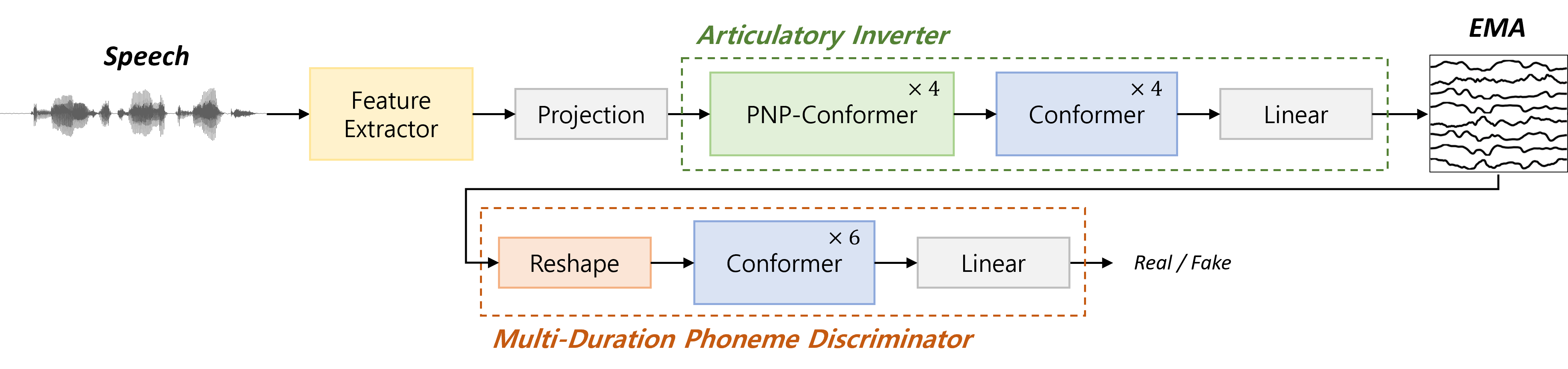
0
Speaker-Independent Acoustic-to-Articulatory Inversion through Multi-Channel Attention Discriminator
Woo-Jin Chung, Hong-Goo Kang
We present a novel speaker-independent acoustic-to-articulatory inversion (AAI) model, overcoming the limitations observed in conventional AAI models that rely on acoustic features derived from restricted datasets. To address these challenges, we leverage representations from a pre-trained self-supervised learning (SSL) model to more effectively estimate the global, local, and kinematic pattern information in Electromagnetic Articulography (EMA) signals during the AAI process. We train our model using an adversarial approach and introduce an attention-based Multi-duration phoneme discriminator (MDPD) designed to fully capture the intricate relationship among multi-channel articulatory signals. Our method achieves a Pearson correlation coefficient of 0.847, marking state-of-the-art performance in speaker-independent AAI models. The implementation details and code can be found online.
Read more6/26/2024
🗣️
0
Interpreting Pretrained Speech Models for Automatic Speech Assessment of Voice Disorders
Hok-Shing Lau, Mark Huntly, Nathon Morgan, Adesua Iyenoma, Biao Zeng, Tim Bashford
Speech contains information that is clinically relevant to some diseases, which has the potential to be used for health assessment. Recent work shows an interest in applying deep learning algorithms, especially pretrained large speech models to the applications of Automatic Speech Assessment. One question that has not been explored is how these models output the results based on their inputs. In this work, we train and compare two configurations of Audio Spectrogram Transformer in the context of Voice Disorder Detection and apply the attention rollout method to produce model relevance maps, the computed relevance of the spectrogram regions when the model makes predictions. We use these maps to analyse how models make predictions in different conditions and to show that the spread of attention is reduced as a model is finetuned, and the model attention is concentrated on specific phoneme regions.
Read more7/2/2024