PowerTrain: Fast, Generalizable Time and Power Prediction Models to Optimize DNN Training on Accelerated Edges

0
Sign in to get full access
Overview
- The research paper "PowerTrain: Fast, Generalizable Time and Power Prediction Models to Optimize DNN Training on Accelerated Edges" presents models to predict the training time and power consumption of deep neural networks (DNNs) on edge computing devices.
- The goal is to help optimize DNN training on accelerated edge devices by providing accurate predictions of the time and power required.
- The models are designed to be fast and generalizable, allowing them to be applied across different DNN architectures, hardware accelerators, and edge computing platforms.
Plain English Explanation
The research paper introduces PowerTrain, a set of models that can quickly and accurately predict the training time and power consumption of deep learning models running on edge computing devices. These edge devices, like smartphones or IoT sensors, often have specialized hardware accelerators to speed up machine learning tasks.
The key idea behind PowerTrain is to provide a way for developers to optimize the training of their deep learning models on these edge devices. By predicting the time and power requirements, they can make informed decisions about things like:
- Model architecture: Choosing a model that can be trained efficiently on the available hardware.
- Hardware configuration: Selecting the right edge device or accelerator for their needs.
- Training hyperparameters: Tuning settings like batch size or learning rate to improve performance.
The models use information about the DNN model, the hardware, and the training process to make these predictions. They are designed to be fast and generalizable, meaning they can be applied to a wide variety of deep learning models and edge computing platforms without extensive retraining or customization.
This could be really helpful for developers working on AI applications that run on edge devices, as it can save them a lot of time and effort in optimizing their models for those platforms.
Technical Explanation
The PowerTrain models consist of two main components:
-
Time Prediction Model: This model predicts the total training time of a DNN on a given edge device. It takes into account factors like the DNN model architecture, the hardware specifications, and the training hyperparameters.
-
Power Prediction Model: This model predicts the average power consumption during the DNN training process on the edge device. It uses similar input features to the time prediction model.
The researchers evaluated these models on a variety of DNN architectures (e.g., ResNet, BERT) running on different edge computing platforms (e.g., NVIDIA Jetson Nano, Raspberry Pi). They found that the PowerTrain models could make accurate predictions with low latency, outperforming existing approaches.
Key insights from the research include:
- The models are able to generalize well across different DNN models and hardware, without requiring extensive retraining.
- Certain model and hardware features, like the number of parameters and the memory bandwidth, are particularly important for accurate time and power predictions.
- The models can be used to guide design decisions, such as selecting the most suitable hardware for a given DNN or tuning training hyperparameters.
Critical Analysis
The research presents a promising approach for optimizing DNN training on edge devices, but there are a few potential limitations and areas for further exploration:
- The models were evaluated on a relatively limited set of DNN architectures and edge platforms. More extensive testing across a wider range of models and hardware would help validate the generalizability claims.
- The paper does not discuss the overhead or complexity of deploying the PowerTrain models in a real-world production environment. Integrating the models into existing edge computing frameworks or deployment pipelines may require additional engineering effort.
- The power prediction model relies on measuring the actual power consumption during training, which may not always be feasible in all edge computing setups. Exploring alternative approaches to power estimation could make the models more widely applicable.
Overall, the PowerTrain research represents an important step towards optimizing DNN training on edge devices, but further refinement and validation of the models would be beneficial to strengthen the practical applicability of this approach.
Conclusion
The "PowerTrain" research introduces fast and generalizable models for predicting the training time and power consumption of deep neural networks on edge computing devices. These models can help developers optimize their DNN models for deployment on edge platforms by guiding decisions around model architecture, hardware selection, and training hyperparameters.
The research demonstrates the potential of these PowerTrain models to improve the efficiency and performance of AI applications running on edge devices, which is becoming increasingly important as machine learning becomes more pervasive in our everyday lives. Further development and validation of these models could lead to significant advancements in the field of edge computing and accelerated deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PowerTrain: Fast, Generalizable Time and Power Prediction Models to Optimize DNN Training on Accelerated Edges
Prashanthi S. K., Saisamarth Taluri, Beautlin S, Lakshya Karwa, Yogesh Simmhan
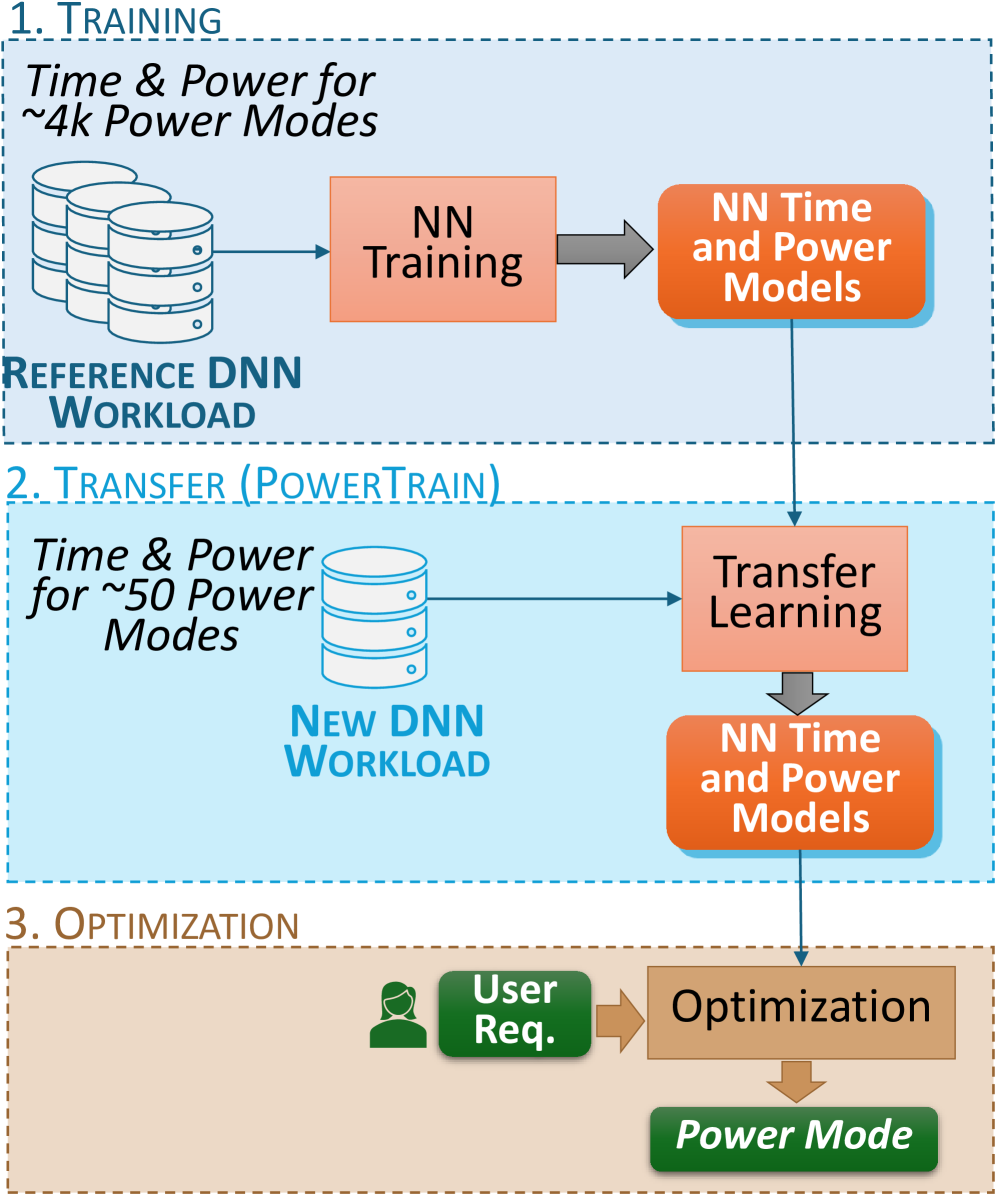
Accelerated edge devices, like Nvidia's Jetson with 1000+ CUDA cores, are increasingly used for DNN training and federated learning, rather than just for inferencing workloads. A unique feature of these compact devices is their fine-grained control over CPU, GPU, memory frequencies, and active CPU cores, which can limit their power envelope in a constrained setting while throttling the compute performance. Given this vast 10k+ parameter space, selecting a power mode for dynamically arriving training workloads to exploit power-performance trade-offs requires costly profiling for each new workload, or is done textit{ad hoc}. We propose textit{PowerTrain}, a transfer-learning approach to accurately predict the power and time consumed when training a given DNN workload (model + dataset) using any specified power mode (CPU/GPU/memory frequencies, core-count). It requires a one-time offline profiling of $1000$s of power modes for a reference DNN workload on a single Jetson device (Orin AGX) to build Neural Network (NN) based prediction models for time and power. These NN models are subsequently transferred (retrained) for a new DNN workload, or even a different Jetson device, with minimal additional profiling of just $50$ power modes to make accurate time and power predictions. These are then used to rapidly construct the Pareto front and select the optimal power mode for the new workload. PowerTrain's predictions are robust to new workloads, exhibiting a low MAPE of $<6%$ for power and $<15%$ for time on six new training workloads for up to $4400$ power modes, when transferred from a ResNet reference workload on Orin AGX. It is also resilient when transferred to two entirely new Jetson devices with prediction errors of $<14.5%$ and $<11%$. These outperform baseline predictions by more than $10%$ and baseline optimizations by up to $45%$ on time and $88%$ on power.
Read more7/22/2024

0
New!Automatic Generation of Fast and Accurate Performance Models for Deep Neural Network Accelerators
Konstantin Lubeck, Alexander Louis-Ferdinand Jung, Felix Wedlich, Mika Markus Muller, Federico Nicol'as Peccia, Felix Thommes, Jannik Steinmetz, Valentin Biermaier, Adrian Frischknecht, Paul Palomero Bernardo, Oliver Bringmann
Implementing Deep Neural Networks (DNNs) on resource-constrained edge devices is a challenging task that requires tailored hardware accelerator architectures and a clear understanding of their performance characteristics when executing the intended AI workload. To facilitate this, we present an automated generation approach for fast performance models to accurately estimate the latency of a DNN mapped onto systematically modeled and concisely described accelerator architectures. Using our accelerator architecture description method, we modeled representative DNN accelerators such as Gemmini, UltraTrail, Plasticine-derived, and a parameterizable systolic array. Together with DNN mappings for those modeled architectures, we perform a combined DNN/hardware dependency graph analysis, which enables us, in the best case, to evaluate only 154 loop kernel iterations to estimate the performance for 4.19 billion instructions achieving a significant speedup. We outperform regression and analytical models in terms of mean absolute percentage error (MAPE) compared to simulation results, while being several magnitudes faster than an RTL simulation.
Read more9/16/2024
🏋️
0
TinyTrain: Resource-Aware Task-Adaptive Sparse Training of DNNs at the Data-Scarce Edge
Young D. Kwon, Rui Li, Stylianos I. Venieris, Jagmohan Chauhan, Nicholas D. Lane, Cecilia Mascolo
On-device training is essential for user personalisation and privacy. With the pervasiveness of IoT devices and microcontroller units (MCUs), this task becomes more challenging due to the constrained memory and compute resources, and the limited availability of labelled user data. Nonetheless, prior works neglect the data scarcity issue, require excessively long training time (e.g. a few hours), or induce substantial accuracy loss (>10%). In this paper, we propose TinyTrain, an on-device training approach that drastically reduces training time by selectively updating parts of the model and explicitly coping with data scarcity. TinyTrain introduces a task-adaptive sparse-update method that dynamically selects the layer/channel to update based on a multi-objective criterion that jointly captures user data, the memory, and the compute capabilities of the target device, leading to high accuracy on unseen tasks with reduced computation and memory footprint. TinyTrain outperforms vanilla fine-tuning of the entire network by 3.6-5.0% in accuracy, while reducing the backward-pass memory and computation cost by up to 1,098x and 7.68x, respectively. Targeting broadly used real-world edge devices, TinyTrain achieves 9.5x faster and 3.5x more energy-efficient training over status-quo approaches, and 2.23x smaller memory footprint than SOTA methods, while remaining within the 1 MB memory envelope of MCU-grade platforms.
Read more6/12/2024
🤿
0
Workload-Aware Hardware Accelerator Mining for Distributed Deep Learning Training
Muhammad Adnan, Amar Phanishayee, Janardhan Kulkarni, Prashant J. Nair, Divya Mahajan
In this paper, we present a novel technique to search for hardware architectures of accelerators optimized for end-to-end training of deep neural networks (DNNs). Our approach addresses both single-device and distributed pipeline and tensor model parallel scenarios, latter being addressed for the first time. The search optimized accelerators for training relevant metrics such as throughput/TDP under a fixed area and power constraints. However, with the proliferation of specialized architectures and complex distributed training mechanisms, the design space exploration of hardware accelerators is very large. Prior work in this space has tried to tackle this by reducing the search space to either a single accelerator execution that too only for inference, or tuning the architecture for specific layers (e.g., convolution). Instead, we take a unique heuristic-based critical path-based approach to determine the best use of available resources (power and area) either for a set of DNN workloads or each workload individually. First, we perform local search to determine the architecture for each pipeline and tensor model stage. Specifically, the system iteratively generates architectural configurations and tunes the design using a novel heuristic-based approach that prioritizes accelerator resources and scheduling to critical operators in a machine learning workload. Second, to address the complexities of distributed training, the local search selects multiple (k) designs per stage. A global search then identifies an accelerator from the top-k sets to optimize training throughput across the stages. We evaluate this work on 11 different DNN models. Compared to a recent inference-only work Spotlight, our method converges to a design in, on average, 31x less time and offers 12x higher throughput. Moreover, designs generated using our method achieve 12% throughput improvement over TPU architecture.
Read more4/24/2024