Automatic Generation of Model and Data Cards: A Step Towards Responsible AI

0
🛸
Sign in to get full access
Overview
- The research paper addresses the need for standardized and consistent documentation in the rapidly evolving field of machine learning and AI, particularly with the proliferation of open-source technologies.
- The authors propose an automated approach using Large Language Models (LLMs) to generate more complete, objective, and faithful model and data cards, which are crucial for responsible AI practices and better accountability.
- The key contributions include the establishment of a comprehensive dataset called CardBench and the development of the CardGen pipeline, a two-step retrieval process for generating the model and data cards.
Plain English Explanation
As machine learning and AI technologies advance, especially with the widespread availability of open-source tools, there is a growing need for consistent and comprehensive documentation. This research paper addresses this need by proposing an automated approach to generate more complete and reliable model and data cards using Large Language Models (LLMs).
The authors have created a large dataset called CardBench, which includes over 4,800 model cards and 1,400 data cards. They have then developed a two-step process called the CardGen pipeline to generate these cards automatically. This approach aims to ensure that the generated cards are more complete, objective, and faithful to the original information, which is crucial for responsible AI practices and better accountability.
The research team's work is an important step towards improving the documentation of machine learning and AI systems, making it easier for users to understand the capabilities and limitations of these technologies. This can help promote transparency and trust in the field, as well as enable better decision-making and responsible deployment of these powerful tools.
Technical Explanation
The research paper presents an automated approach to generate model and data cards using Large Language Models (LLMs). The authors have established a comprehensive dataset called CardBench, which includes over 4,800 model cards and 1,400 data cards. This dataset serves as the foundation for their work.
The CardGen pipeline, the core of their approach, consists of a two-step retrieval process. The first step involves using an LLM-based retrieval model to identify relevant sections from the CardBench dataset, based on the input prompts. The second step then uses another LLM to generate the final model or data card, incorporating the relevant information from the retrieved sections.
The key innovations of this research include the establishment of the CardBench dataset and the development of the CardGen pipeline. The authors demonstrate that their approach can generate model and data cards with enhanced completeness, objectivity, and faithfulness, compared to manually curated cards. This is a significant advancement in responsible AI documentation practices, as it can improve accountability and traceability.
Critical Analysis
The research paper presents a compelling approach to addressing the need for standardized and consistent documentation in the rapidly evolving field of machine learning and AI. The authors have made a substantial contribution by creating the CardBench dataset and the CardGen pipeline, which can generate more comprehensive and reliable model and data cards.
One potential limitation of the research is the reliance on the CardBench dataset, which may not capture the full diversity of model and data cards available in the broader ecosystem. As the authors acknowledge, the dataset is a starting point, and further expansion and refinement may be necessary to ensure the approach is widely applicable.
Additionally, the evaluation of the generated cards' quality, while promising, could be further strengthened by incorporating feedback from a broader range of stakeholders, including model developers, data scientists, and end-users. This would help validate the real-world utility and impact of the proposed solution.
Future research could explore ways to integrate the CardGen pipeline with existing model and data management workflows, making it easier for organizations to adopt and integrate this technology into their practices. Exploring the use of LLMs in other documentation tasks, such as generating illustrated instructions or autonomous LLM-driven research, could also be valuable avenues for further investigation.
Conclusion
The research paper presents a significant contribution to the field of responsible AI documentation by proposing an automated approach to generate more complete, objective, and faithful model and data cards. The establishment of the CardBench dataset and the development of the CardGen pipeline are key innovations that can help address the growing need for standardized and consistent documentation in the rapidly evolving world of machine learning and AI.
This work has the potential to improve transparency, accountability, and traceability in the deployment of AI systems, which is crucial for building trust and ensuring the responsible use of these powerful technologies. As the field continues to evolve, the insights and methodologies presented in this research can serve as a foundation for further advancements in AI documentation practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
Automatic Generation of Model and Data Cards: A Step Towards Responsible AI
Jiarui Liu, Wenkai Li, Zhijing Jin, Mona Diab
In an era of model and data proliferation in machine learning/AI especially marked by the rapid advancement of open-sourced technologies, there arises a critical need for standardized consistent documentation. Our work addresses the information incompleteness in current human-generated model and data cards. We propose an automated generation approach using Large Language Models (LLMs). Our key contributions include the establishment of CardBench, a comprehensive dataset aggregated from over 4.8k model cards and 1.4k data cards, coupled with the development of the CardGen pipeline comprising a two-step retrieval process. Our approach exhibits enhanced completeness, objectivity, and faithfulness in generated model and data cards, a significant step in responsible AI documentation practices ensuring better accountability and traceability.
Read more6/21/2024
0
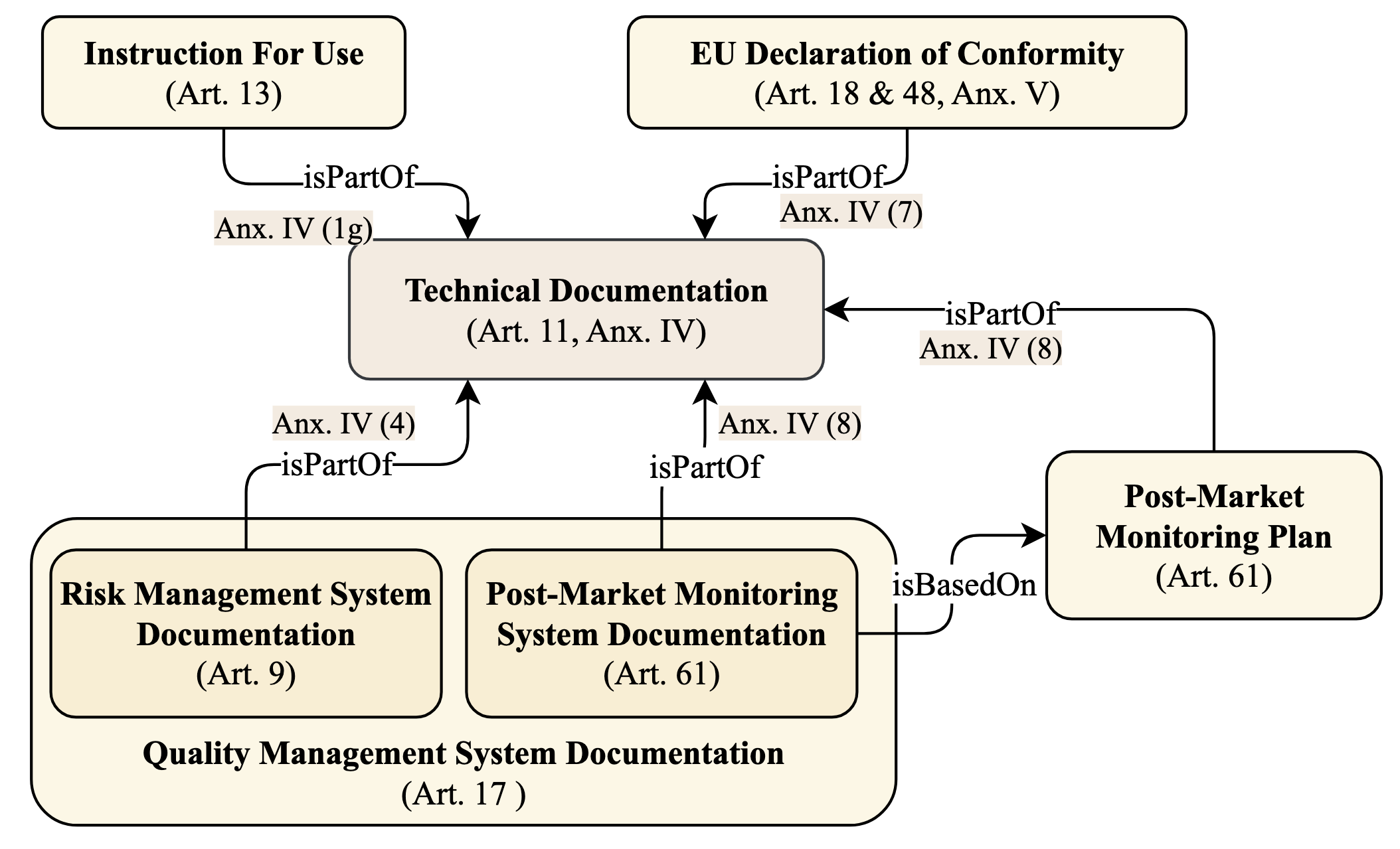
AI Cards: Towards an Applied Framework for Machine-Readable AI and Risk Documentation Inspired by the EU AI Act
Delaram Golpayegani, Isabelle Hupont, Cecilia Panigutti, Harshvardhan J. Pandit, Sven Schade, Declan O'Sullivan, Dave Lewis
With the upcoming enforcement of the EU AI Act, documentation of high-risk AI systems and their risk management information will become a legal requirement playing a pivotal role in demonstration of compliance. Despite its importance, there is a lack of standards and guidelines to assist with drawing up AI and risk documentation aligned with the AI Act. This paper aims to address this gap by providing an in-depth analysis of the AI Act's provisions regarding technical documentation, wherein we particularly focus on AI risk management. On the basis of this analysis, we propose AI Cards as a novel holistic framework for representing a given intended use of an AI system by encompassing information regarding technical specifications, context of use, and risk management, both in human- and machine-readable formats. While the human-readable representation of AI Cards provides AI stakeholders with a transparent and comprehensible overview of the AI use case, its machine-readable specification leverages on state of the art Semantic Web technologies to embody the interoperability needed for exchanging documentation within the AI value chain. This brings the flexibility required for reflecting changes applied to the AI system and its context, provides the scalability needed to accommodate potential amendments to legal requirements, and enables development of automated tools to assist with legal compliance and conformity assessment tasks. To solidify the benefits, we provide an exemplar AI Card for an AI-based student proctoring system and further discuss its potential applications within and beyond the context of the AI Act.
Read more6/27/2024
0
Towards Data-Centric Automatic R&D
Haotian Chen, Xinjie Shen, Zeqi Ye, Wenjun Feng, Haoxue Wang, Xiao Yang, Xu Yang, Weiqing Liu, Jiang Bian
The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method has demonstrated its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focus on evaluating the interaction and synergistic effects of various model capabilities and aiding in selecting well-performing trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.
Read more7/31/2024

0
Three Disclaimers for Safe Disclosure: A Cardwriter for Reporting the Use of Generative AI in Writing Process
Won Ik Cho, Eunjung Cho, Hyeonji Shin
Generative artificial intelligence (AI) and large language models (LLMs) are increasingly being used in the academic writing process. This is despite the current lack of unified framework for reporting the use of machine assistance. In this work, we propose Cardwriter, an intuitive interface that produces a short report for authors to declare their use of generative AI in their writing process. The demo is available online, at https://cardwriter.vercel.app
Read more4/16/2024