Towards Data-Centric Automatic R&D

0
Sign in to get full access
Overview
- Introduces RD2Bench, a framework for automating R&D processes using data-centric approaches
- Aims to accelerate research and development by leveraging large datasets and machine learning techniques
- Covers the key components of the RD2Bench framework and its potential applications
Plain English Explanation
The provided paper introduces a new framework called RD2Bench, which stands for "Research and Development Benchmark." The goal of this framework is to automate various aspects of the R&D process by using data-centric approaches.
The researchers behind RD2Bench recognize that modern R&D often involves working with large and complex datasets. By leveraging machine learning and other advanced data analysis techniques, they believe it's possible to accelerate the R&D process and make it more efficient. The RD2Bench framework outlines a set of tools and methodologies designed to support this data-centric approach to R&D.
Some of the key ideas behind RD2Bench include automating the generation of hypotheses, designing experiments, and analyzing the resulting data. The framework also aims to facilitate collaboration and knowledge sharing between researchers working on similar problems. By standardizing and streamlining the R&D process, the researchers hope to enable faster and more impactful discoveries across a wide range of scientific and engineering disciplines.
Technical Explanation
The RD2Bench framework is composed of several key components:
-
Data Acquisition and Preprocessing: The framework includes tools for efficiently gathering, cleaning, and organizing the relevant data needed for R&D projects.
-
Hypothesis Generation: RD2Bench uses machine learning techniques to automatically generate plausible hypotheses based on the available data, accelerating the ideation process.
-
Experiment Design: The framework can assist in designing experiments to test the generated hypotheses, optimizing parameters and logistics to maximize the information gained.
-
Data Analysis: RD2Bench provides advanced data analysis capabilities, including the use of machine learning models to extract insights and identify patterns in the experimental results.
-
Knowledge Sharing and Collaboration: The framework incorporates features to facilitate the sharing of research findings and collaboration among scientists and engineers working on similar problems.
By integrating these components, the RD2Bench framework aims to create a more streamlined and data-driven approach to R&D, potentially leading to faster and more impactful discoveries.
Critical Analysis
The paper presents a compelling vision for a data-centric approach to R&D, but it also acknowledges several potential challenges and limitations:
-
Data Quality and Availability: The effectiveness of RD2Bench is heavily dependent on the quality and availability of the underlying data. Ensuring the integrity and representativeness of the data used in the R&D process will be crucial.
-
Ethical Considerations: As the framework relies on automated decision-making, there may be concerns around the ethical implications of such systems, particularly when it comes to areas like medical research or other high-stakes domains.
-
Interpretability and Transparency: The use of complex machine learning models within RD2Bench raises questions about the interpretability and transparency of the decision-making process, which may be important for gaining trust and acceptance from the research community.
-
Adaptability and Generalizability: The paper doesn't extensively address how the RD2Bench framework can be adapted to different research domains or how it can maintain its effectiveness as the nature of R&D evolves over time.
Conclusion
The RD2Bench framework presented in this paper represents a promising step towards a more data-centric and automated approach to research and development. By leveraging advanced data analysis and machine learning techniques, the researchers aim to accelerate the R&D process and enable faster, more impactful discoveries across a wide range of scientific and engineering disciplines.
However, the successful implementation of RD2Bench will depend on addressing the critical challenges and limitations, such as data quality, ethical considerations, and the need for interpretability and adaptability. As the field of data-centric AI continues to evolve, frameworks like RD2Bench may play an increasingly important role in shaping the future of research and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Data-Centric Automatic R&D
Haotian Chen, Xinjie Shen, Zeqi Ye, Wenjun Feng, Haoxue Wang, Xiao Yang, Xu Yang, Weiqing Liu, Jiang Bian
The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method has demonstrated its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focus on evaluating the interaction and synergistic effects of various model capabilities and aiding in selecting well-performing trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.
Read more7/31/2024
🛸
0
Automatic Generation of Model and Data Cards: A Step Towards Responsible AI
Jiarui Liu, Wenkai Li, Zhijing Jin, Mona Diab
In an era of model and data proliferation in machine learning/AI especially marked by the rapid advancement of open-sourced technologies, there arises a critical need for standardized consistent documentation. Our work addresses the information incompleteness in current human-generated model and data cards. We propose an automated generation approach using Large Language Models (LLMs). Our key contributions include the establishment of CardBench, a comprehensive dataset aggregated from over 4.8k model cards and 1.4k data cards, coupled with the development of the CardGen pipeline comprising a two-step retrieval process. Our approach exhibits enhanced completeness, objectivity, and faithfulness in generated model and data cards, a significant step in responsible AI documentation practices ensuring better accountability and traceability.
Read more6/21/2024
0
Data-Centric AI in the Age of Large Language Models
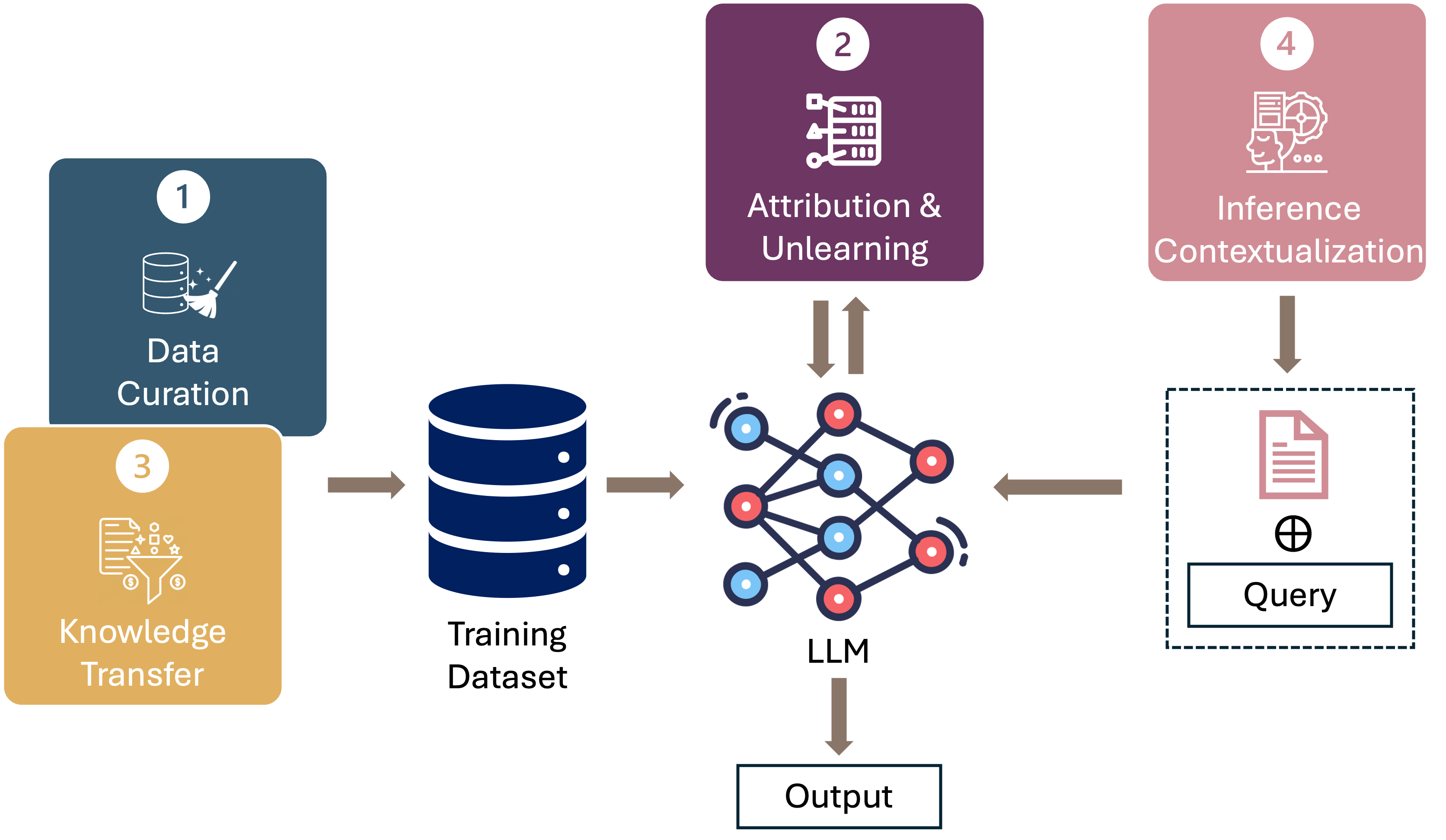
Xinyi Xu, Zhaoxuan Wu, Rui Qiao, Arun Verma, Yao Shu, Jingtan Wang, Xinyuan Niu, Zhenfeng He, Jiangwei Chen, Zijian Zhou, Gregory Kang Ruey Lau, Hieu Dao, Lucas Agussurja, Rachael Hwee Ling Sim, Xiaoqiang Lin, Wenyang Hu, Zhongxiang Dai, Pang Wei Koh, Bryan Kian Hsiang Low
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Read more6/21/2024
📊
0
Autonomous LLM-driven research from data to human-verifiable research papers
Tal Ifargan, Lukas Hafner, Maor Kern, Ori Alcalay, Roy Kishony
As AI promises to accelerate scientific discovery, it remains unclear whether fully AI-driven research is possible and whether it can adhere to key scientific values, such as transparency, traceability and verifiability. Mimicking human scientific practices, we built data-to-paper, an automation platform that guides interacting LLM agents through a complete stepwise research process, while programmatically back-tracing information flow and allowing human oversight and interactions. In autopilot mode, provided with annotated data alone, data-to-paper raised hypotheses, designed research plans, wrote and debugged analysis codes, generated and interpreted results, and created complete and information-traceable research papers. Even though research novelty was relatively limited, the process demonstrated autonomous generation of de novo quantitative insights from data. For simple research goals, a fully-autonomous cycle can create manuscripts which recapitulate peer-reviewed publications without major errors in about 80-90%, yet as goal complexity increases, human co-piloting becomes critical for assuring accuracy. Beyond the process itself, created manuscripts too are inherently verifiable, as information-tracing allows to programmatically chain results, methods and data. Our work thereby demonstrates a potential for AI-driven acceleration of scientific discovery while enhancing, rather than jeopardizing, traceability, transparency and verifiability.
Read more4/30/2024