InstructEdit: Instruction-based Knowledge Editing for Large Language Models
2402.16123
0
11
💬
Abstract
Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approaches encounter issues with limited generalizability across tasks, necessitating one distinct editor for each task, significantly hindering the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets are available in https://github.com/zjunlp/EasyEdit.
Create account to get full access
Overview
- Researchers propose a new technique called InstructEdit to improve knowledge editing for large language models (LLMs)
- Current approaches have limited generalizability across tasks, requiring a distinct editor for each task
- InstructEdit aims to enable a single unified editor to improve performance on multiple tasks simultaneously using simple instructions
- Experiments show InstructEdit can improve reliability by 14.86% on average in a multi-task setting and outperform previous baselines on unseen tasks
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, their behavior can be unpredictable or undesirable in certain situations. Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance.
The current approaches to knowledge editing have a significant limitation - they are often tailored to a specific task, meaning a new editor needs to be developed for each different task. This makes it difficult to apply knowledge editing more broadly. To address this issue, the researchers developed a new technique called InstructEdit.
InstructEdit allows a single unified editor to be used across multiple tasks. Instead of creating a separate editor for each task, InstructEdit uses simple instructions to guide the editor's behavior. This means the same editor can be used to improve the model's performance on a variety of different tasks, making knowledge editing much more efficient and flexible.
The researchers found that InstructEdit was able to improve the model's "reliability" - its consistency and trustworthiness - by an average of 14.86% in a multi-task setting. Additionally, when tested on completely new, unseen tasks, InstructEdit outperformed previous state-of-the-art approaches.
Overall, this research is a significant step forward in making knowledge editing more practical and widely applicable for improving the behavior of large language models.
Technical Explanation
The key idea behind InstructEdit is to develop an instruction-based editing technique that can adapt to various task performances simultaneously using simple instructions. This addresses the limitation of current approaches, which require a distinct editor for each task, significantly hindering broader applications.
The researchers empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in a multi-task editing setting. Furthermore, experiments involving holdout unseen tasks illustrate that InstructEdit consistently outperforms previous strong baselines.
To understand the underlying mechanisms of instruction-based knowledge editing, the researchers analyze the principal components of the editing gradient directions. This analysis reveals that instructions can help control the optimization direction, resulting in stronger out-of-distribution (OOD) generalization.
The researchers make their code and datasets available to facilitate further research in this area. This work represents a significant advancement in the field of knowledge editing for large language models, paving the way for more efficient and versatile methods to improve the behavior of these powerful AI systems.
Critical Analysis
The researchers have made a compelling case for the benefits of InstructEdit, demonstrating its ability to outperform previous approaches in multi-task and unseen task settings. However, the paper does not explore the limitations or potential drawbacks of this technique.
For example, the paper does not discuss the complexity or computational cost of the InstructEdit approach compared to other knowledge editing methods. Additionally, it's unclear how the performance of InstructEdit scales with the number of tasks or the complexity of the instructions provided.
Furthermore, the paper does not address potential ethical concerns around the use of knowledge editing, such as the risk of unintended biases or the potential for misuse. As large language models become more capable and widely deployed, it is crucial to consider the broader implications of techniques like InstructEdit.
Future research in this area should explore these limitations and potential issues more thoroughly, ensuring that knowledge editing techniques are developed and applied in a responsible and ethical manner. Additionally, evaluating InstructEdit on a broader range of tasks and datasets, including real-world applications, would further validate the effectiveness and generalizability of this approach.
Conclusion
The research presented in this paper represents a significant advancement in the field of knowledge editing for large language models. The InstructEdit technique offers a more efficient and flexible solution compared to previous approaches, allowing a single unified editor to be used across multiple tasks.
The empirical results demonstrate the effectiveness of InstructEdit, with an average 14.86% increase in Reliability in a multi-task setting and consistent outperformance on unseen tasks. This suggests that InstructEdit can help improve the reliability and trustworthiness of large language models, which is crucial as these powerful AI systems become more widely deployed.
While the paper does not address all the potential limitations and concerns, this research represents an important step forward in the ongoing efforts to enhance the behavior and capabilities of large language models. As the field continues to evolve, it will be essential to build on these advancements while also prioritizing the ethical and responsible development of knowledge editing techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
EasyEdit: An Easy-to-use Knowledge Editing Framework for Large Language Models
Peng Wang, Ningyu Zhang, Bozhong Tian, Zekun Xi, Yunzhi Yao, Ziwen Xu, Mengru Wang, Shengyu Mao, Xiaohan Wang, Siyuan Cheng, Kangwei Liu, Yuansheng Ni, Guozhou Zheng, Huajun Chen
0
0
Large Language Models (LLMs) usually suffer from knowledge cutoff or fallacy issues, which means they are unaware of unseen events or generate text with incorrect facts owing to outdated/noisy data. To this end, many knowledge editing approaches for LLMs have emerged -- aiming to subtly inject/edit updated knowledge or adjust undesired behavior while minimizing the impact on unrelated inputs. Nevertheless, due to significant differences among various knowledge editing methods and the variations in task setups, there is no standard implementation framework available for the community, which hinders practitioners from applying knowledge editing to applications. To address these issues, we propose EasyEdit, an easy-to-use knowledge editing framework for LLMs. It supports various cutting-edge knowledge editing approaches and can be readily applied to many well-known LLMs such as T5, GPT-J, LlaMA, etc. Empirically, we report the knowledge editing results on LlaMA-2 with EasyEdit, demonstrating that knowledge editing surpasses traditional fine-tuning in terms of reliability and generalization. We have released the source code on GitHub, along with Google Colab tutorials and comprehensive documentation for beginners to get started. Besides, we present an online system for real-time knowledge editing, and a demo video.
6/26/2024
💬
Cross-Lingual Knowledge Editing in Large Language Models
Jiaan Wang, Yunlong Liang, Zengkui Sun, Yuxuan Cao, Jiarong Xu, Fandong Meng
0
0
Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges. Data and codes are available at https://github.com/krystalan/Bi_ZsRE
5/31/2024
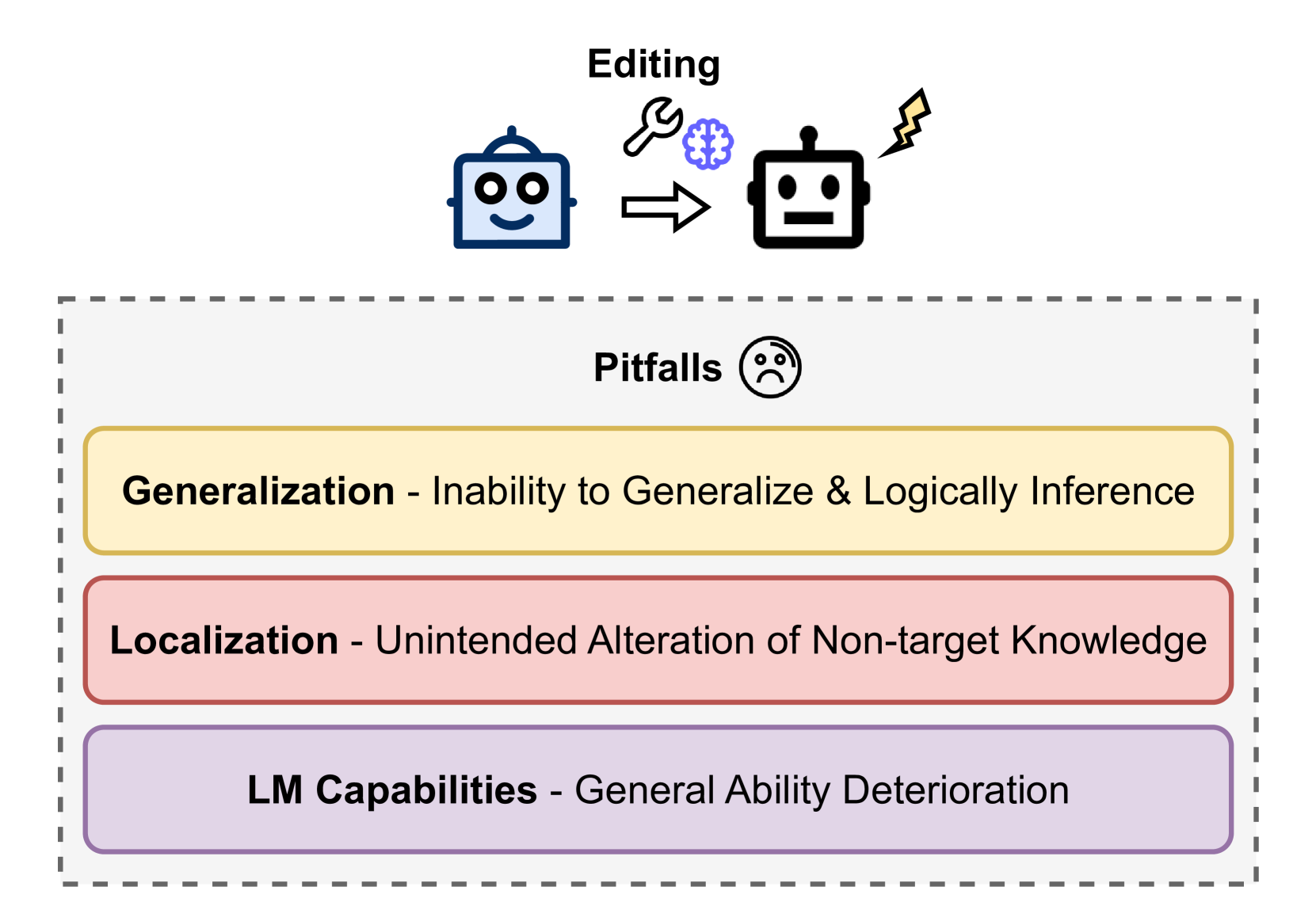
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Cheng-Hsun Hsueh, Paul Kuo-Ming Huang, Tzu-Han Lin, Che-Wei Liao, Hung-Chieh Fang, Chao-Wei Huang, Yun-Nung Chen
0
0
Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
6/4/2024
🔄
Learning to Edit: Aligning LLMs with Knowledge Editing
Yuxin Jiang, Yufei Wang, Chuhan Wu, Wanjun Zhong, Xingshan Zeng, Jiahui Gao, Liangyou Li, Xin Jiang, Lifeng Shang, Ruiming Tang, Qun Liu, Wei Wang
0
0
Knowledge editing techniques, aiming to efficiently modify a minor proportion of knowledge in large language models (LLMs) without negatively impacting performance across other inputs, have garnered widespread attention. However, existing methods predominantly rely on memorizing the updated knowledge, impeding LLMs from effectively combining the new knowledge with their inherent knowledge when answering questions. To this end, we propose a Learning to Edit (LTE) framework, focusing on teaching LLMs to apply updated knowledge into input questions, inspired by the philosophy of Teach a man to fish. LTE features a two-phase process: (i) the Alignment Phase, which fine-tunes LLMs on a meticulously curated parallel dataset to make reliable, in-scope edits while preserving out-of-scope information and linguistic proficiency; and (ii) the Inference Phase, which employs a retrieval-based mechanism for real-time and mass knowledge editing. By comparing our approach with seven advanced baselines across four popular knowledge editing benchmarks and two LLM architectures, we demonstrate LTE's superiority in knowledge editing performance, robustness in both batch and sequential editing, minimal interference on general tasks, and rapid editing speeds. The data and code are available at https://github.com/YJiangcm/LTE.
6/6/2024