Automating Robot Failure Recovery Using Vision-Language Models With Optimized Prompts

0

Sign in to get full access
Overview
- This paper describes a system that uses vision-language models to automatically recover from failures during robot tasks.
- The system leverages multimodal AI models that can understand images and language to diagnose issues and generate recovery plans.
- Optimized prompts are used to elicit informative responses from the language models.
- Experiments demonstrate the system's ability to recover from various types of failures across different robotic platforms.
Plain English Explanation
The paper presents a new approach to help robots recover from problems that occur during their tasks. When a robot encounters an unexpected situation or error, it can be challenging for human operators to quickly diagnose the issue and determine the best recovery plan. This paper introduces a system that automates this process by using advanced AI models that can understand both visual information (like camera images) and language instructions.
The key idea is to leverage these vision-language models to assess the robot's current state, identify the problem, and generate an appropriate recovery plan. The researchers developed optimized prompts - specific instructions tailored to elicit informative responses from the language models.
Through experiments on various robot platforms, the researchers demonstrated that this approach can effectively handle different types of failures, like objects getting stuck or robots losing track of their location. By automating the recovery process, this system could help robots operate more reliably and reduce the need for constant human supervision.
Technical Explanation
The paper introduces a system for automating robot failure recovery using vision-language models. The core components are:
-
Failure Detection: The system monitors the robot's state during task execution and detects when an unexpected issue or failure occurs.
-
Failure Diagnosis: When a failure is detected, the system captures images of the robot's current state and uses a vision-language model to diagnose the problem. Optimized prompts are used to elicit informative responses from the language model.
-
Recovery Planning: Based on the diagnosed issue, the system generates a recovery plan by querying the vision-language model with additional prompts. The recovery plan is then executed to resolve the failure.
The researchers evaluated this system across different robot platforms and failure scenarios, including objects getting stuck, robots losing localization, and more. The results demonstrate the system's ability to effectively recover from a variety of failures in an automated manner, reducing the need for human intervention.
Critical Analysis
The paper presents a compelling approach for automating robot failure recovery using state-of-the-art vision-language models. By leveraging these advanced AI models, the system can diagnose problems and generate recovery plans without requiring manual intervention.
One potential limitation of the approach is its reliance on the capabilities of the underlying vision-language models. The performance of the system may be constrained by the accuracy and robustness of these models, especially in handling edge cases or unexpected situations. The authors acknowledge this and suggest further research to improve the model's generalization abilities.
Additionally, the paper does not provide a detailed analysis of the computational and time requirements of the system. Deploying this approach in real-world robotic applications would require consideration of the processing overhead and response times, which could be critical for time-sensitive tasks.
Overall, this research represents an important step towards more autonomous and resilient robotic systems. The ability to automatically recover from failures is a valuable capability that could enhance the reliability and flexibility of robots operating in complex, unstructured environments.
Conclusion
This paper introduces a novel approach for automating robot failure recovery using vision-language models and optimized prompts. By leveraging the capabilities of these advanced AI systems, the proposed system can effectively diagnose problems and generate appropriate recovery plans, reducing the need for human intervention.
The experimental results demonstrate the system's ability to handle a variety of failure scenarios across different robot platforms. While the approach has some limitations, it represents a significant advancement in the field of robust and autonomous robotics. Further research to improve the generalization and efficiency of the system could lead to even more practical and widespread applications in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automating Robot Failure Recovery Using Vision-Language Models With Optimized Prompts
Hongyi Chen, Yunchao Yao, Ruixuan Liu, Changliu Liu, Jeffrey Ichnowski
Current robot autonomy struggles to operate beyond the assumed Operational Design Domain (ODD), the specific set of conditions and environments in which the system is designed to function, while the real-world is rife with uncertainties that may lead to failures. Automating recovery remains a significant challenge. Traditional methods often rely on human intervention to manually address failures or require exhaustive enumeration of failure cases and the design of specific recovery policies for each scenario, both of which are labor-intensive. Foundational Vision-Language Models (VLMs), which demonstrate remarkable common-sense generalization and reasoning capabilities, have broader, potentially unbounded ODDs. However, limitations in spatial reasoning continue to be a common challenge for many VLMs when applied to robot control and motion-level error recovery. In this paper, we investigate how optimizing visual and text prompts can enhance the spatial reasoning of VLMs, enabling them to function effectively as black-box controllers for both motion-level position correction and task-level recovery from unknown failures. Specifically, the optimizations include identifying key visual elements in visual prompts, highlighting these elements in text prompts for querying, and decomposing the reasoning process for failure detection and control generation. In experiments, prompt optimizations significantly outperform pre-trained Vision-Language-Action Models in correcting motion-level position errors and improve accuracy by 65.78% compared to VLMs with unoptimized prompts. Additionally, for task-level failures, optimized prompts enhanced the success rate by 5.8%, 5.8%, and 7.5% in VLMs' abilities to detect failures, analyze issues, and generate recovery plans, respectively, across a wide range of unknown errors in Lego assembly.
Read more9/9/2024

0
ReplanVLM: Replanning Robotic Tasks with Visual Language Models
Aoran Mei, Guo-Niu Zhu, Huaxiang Zhang, Zhongxue Gan
Large language models (LLMs) have gained increasing popularity in robotic task planning due to their exceptional abilities in text analytics and generation, as well as their broad knowledge of the world. However, they fall short in decoding visual cues. LLMs have limited direct perception of the world, which leads to a deficient grasp of the current state of the world. By contrast, the emergence of visual language models (VLMs) fills this gap by integrating visual perception modules, which can enhance the autonomy of robotic task planning. Despite these advancements, VLMs still face challenges, such as the potential for task execution errors, even when provided with accurate instructions. To address such issues, this paper proposes a ReplanVLM framework for robotic task planning. In this study, we focus on error correction interventions. An internal error correction mechanism and an external error correction mechanism are presented to correct errors under corresponding phases. A replan strategy is developed to replan tasks or correct error codes when task execution fails. Experimental results on real robots and in simulation environments have demonstrated the superiority of the proposed framework, with higher success rates and robust error correction capabilities in open-world tasks. Videos of our experiments are available at https://youtu.be/NPk2pWKazJc.
Read more8/1/2024
💬
0
Language Models as Black-Box Optimizers for Vision-Language Models
Shihong Liu, Zhiqiu Lin, Samuel Yu, Ryan Lee, Tiffany Ling, Deepak Pathak, Deva Ramanan
Vision-language models (VLMs) pre-trained on web-scale datasets have demonstrated remarkable capabilities on downstream tasks when fine-tuned with minimal data. However, many VLMs rely on proprietary data and are not open-source, which restricts the use of white-box approaches for fine-tuning. As such, we aim to develop a black-box approach to optimize VLMs through natural language prompts, thereby avoiding the need to access model parameters, feature embeddings, or even output logits. We propose employing chat-based LLMs to search for the best text prompt for VLMs. Specifically, we adopt an automatic hill-climbing procedure that converges to an effective prompt by evaluating the performance of current prompts and asking LLMs to refine them based on textual feedback, all within a conversational process without human-in-the-loop. In a challenging 1-shot image classification setup, our simple approach surpasses the white-box continuous prompting method (CoOp) by an average of 1.5% across 11 datasets including ImageNet. Our approach also outperforms both human-engineered and LLM-generated prompts. We highlight the advantage of conversational feedback that incorporates both positive and negative prompts, suggesting that LLMs can utilize the implicit gradient direction in textual feedback for a more efficient search. In addition, we find that the text prompts generated through our strategy are not only more interpretable but also transfer well across different VLM architectures in a black-box manner. Lastly, we apply our framework to optimize the state-of-the-art black-box VLM (DALL-E 3) for text-to-image generation, prompt inversion, and personalization.
Read more5/15/2024
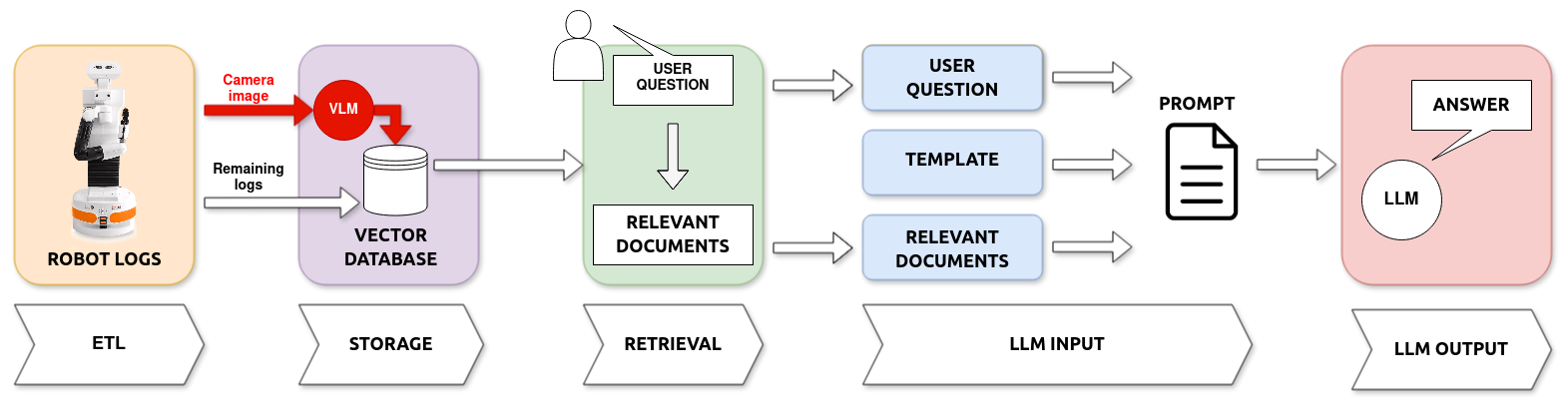
0
Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
David Sobr'in-Hidalgo, Miguel 'Angel Gonz'alez-Santamarta, 'Angel Manuel Guerrero-Higueras, Francisco Javier Rodr'iguez-Lera, Vicente Matell'an-Olivera
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
Read more4/16/2024