Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
2404.09705
0
0
Abstract
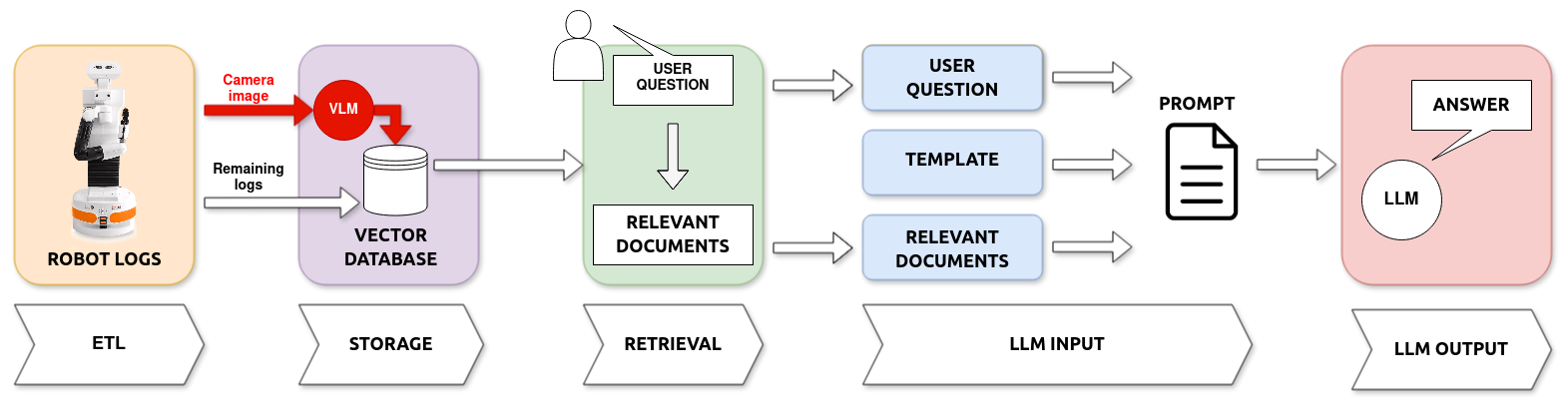
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how vision-language models can be used to enhance a robot's ability to explain its actions and decisions to humans during interaction.
- The researchers conducted a preliminary study to investigate the potential of using these models to interpret visual inputs and generate natural language explanations.
- The goal is to improve human-robot interaction by enabling robots to provide more transparent and understandable explanations of their behavior.
Plain English Explanation
The paper looks at how advanced vision-language models could be used to help robots communicate better with humans. Robots often struggle to explain what they are doing in a way that makes sense to people. This can be a big problem, especially when the robot is doing something complex or making important decisions.
The researchers wanted to see if using these new language and vision learning models could help robots give clearer and more natural-sounding explanations. The idea is that the robot could use the vision-language model to analyze what it's seeing, then turn that into plain language that a human can understand.
For example, if a robot is navigating through a room, it could use the vision-language model to describe what it's seeing - the furniture, the layout of the room, any obstacles it needs to avoid. Then it could explain in simple terms why it's choosing a particular path or making a certain decision. This could make the robot's behavior much more transparent and trustworthy to the human it's interacting with.
Technical Explanation
The researchers conducted a preliminary study to explore the potential of using vision-language models to enhance a robot's explanation capabilities during human-robot interaction. They focused on using these models to interpret visual inputs and generate natural language descriptions that could be used to explain the robot's actions and decisions.
The key aspects of the study include:
- Experiment Design: The researchers set up a simulated environment where a robot navigates through a room, interacting with various objects. They captured visual data from the robot's perspective during these interactions.
- Model Architecture: The researchers used a vision-language model that was pre-trained on large datasets of images and text. This allowed the model to learn how to interpret visual inputs and generate corresponding natural language descriptions.
- Evaluation: The researchers tested the robot's ability to provide explanations using the vision-language model and compared it to a baseline approach without the model. They assessed the quality, clarity, and relevance of the explanations.
The results suggest that the vision-language model-based approach can generate more informative, understandable, and trustworthy explanations compared to the baseline. This highlights the potential of these models to enhance a robot's transparency and improve human-robot interaction.
Critical Analysis
The paper presents a promising preliminary study, but there are some important caveats and limitations to consider:
- The study was conducted in a simulated environment, so it's unclear how well the approach would translate to real-world scenarios with all their complexity and unpredictability. Further testing in physical settings is needed.
- The evaluation focused on qualitative assessments of the explanation quality, but more quantitative metrics could provide additional insights into the model's performance.
- The study only explored a single task and environment. Expanding the research to a wider range of robotic applications and contexts would help further validate the generalizability of the approach.
- While the vision-language model showed improvements over the baseline, there is still room for the explanations to be more natural, coherent, and tailored to the specific needs and backgrounds of the human users.
Additionally, it would be valuable to consider potential biases and limitations inherent in the vision-language models themselves, and how those could impact the quality and fairness of the robot's explanations.
Conclusion
This paper presents a promising step towards enhancing robot explanation capabilities through the use of advanced vision-language models. By leveraging these models to interpret visual inputs and generate natural language descriptions, robots can potentially provide more transparent and understandable explanations of their actions and decisions during human-robot interaction.
The preliminary results suggest that this approach can lead to improvements in the quality, clarity, and trustworthiness of robot explanations compared to a baseline. However, further research is needed to fully validate the approach in real-world settings and address potential limitations and biases.
Overall, this study highlights the potential of vision-language models to bridge the communication gap between robots and humans, ultimately paving the way for more effective and meaningful human-robot collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Vision Beyond Boundaries: An Initial Design Space of Domain-specific Large Vision Models in Human-robot Interaction
Yuchong Zhang, Yong Ma, Danica Kragic
0
0
The emergence of Large Vision Models (LVMs) is following in the footsteps of the recent prosperity of Large Language Models (LLMs) in following years. However, there's a noticeable gap in structured research applying LVMs to Human-Robot Interaction (HRI), despite extensive evidence supporting the efficacy of vision models in enhancing interactions between humans and robots. Recognizing the vast and anticipated potential, we introduce an initial design space that incorporates domain-specific LVMs, chosen for their superior performance over normal models. We delve into three primary dimensions: HRI contexts, vision-based tasks, and specific domains. The empirical validation was implemented among 15 experts across six evaluated metrics, showcasing the primary efficacy in relevant decision-making scenarios. We explore the process of ideation and potential application scenarios, envisioning this design space as a foundational guideline for future HRI system design, emphasizing accurate domain alignment and model selection.
4/24/2024
🖼️
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
0
0
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
4/30/2024

Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
0
0
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
4/16/2024
Analyzing the Roles of Language and Vision in Learning from Limited Data
Allison Chen, Ilia Sucholutsky, Olga Russakovsky, Thomas L. Griffiths
0
0
Does language help make sense of the visual world? How important is it to actually see the world rather than having it described with words? These basic questions about the nature of intelligence have been difficult to answer because we only had one example of an intelligent system -- humans -- and limited access to cases that isolated language or vision. However, the development of sophisticated Vision-Language Models (VLMs) by artificial intelligence researchers offers us new opportunities to explore the contributions that language and vision make to learning about the world. We ablate components from the cognitive architecture of these models to identify their contributions to learning new tasks from limited data. We find that a language model leveraging all components recovers a majority of a VLM's performance, despite its lack of visual input, and that language seems to allow this by providing access to prior knowledge and reasoning.
5/13/2024