AutoML-guided Fusion of Entity and LLM-based representations

0

Sign in to get full access
Overview
- Fuses entity embeddings with low-dimensional projections of large language model (LLM) representations to create more compact and effective knowledge representations.
- Proposes a method called BabelFusion that learns these fused representations.
- Demonstrates superior performance on knowledge base completion and entity typing tasks compared to standalone LLM-based or entity embedding models.
Plain English Explanation
The paper introduces a novel approach called BabelFusion that aims to create more efficient and effective knowledge representations. Traditional methods for representing entities in knowledge bases often rely on entity embeddings - compact vector representations that capture the semantic properties of entities.
However, recent advancements in large language models (LLMs) have shown that their representations can also be useful for knowledge-related tasks. The key insight of BabelFusion is to fuse these two types of representations - entity embeddings and low-dimensional projections of LLM-based representations.
By combining the strengths of both approaches, BabelFusion is able to create more compact and powerful knowledge representations that outperform standalone entity embeddings or LLM-based models on tasks like knowledge base completion and entity typing. This fusion of complementary information sources allows for more efficient and effective utilization of knowledge in downstream applications.
Technical Explanation
The BabelFusion method proposed in the paper learns fused representations by:
-
Extracting LLM-based Representations: The authors use a pre-trained LLM, such as BERT, to generate contextualized representations for each entity in the knowledge base.
-
Projecting LLM Representations: To reduce the dimensionality of the LLM-based representations, a low-rank linear projection is learned to map the high-dimensional LLM outputs to a more compact latent space.
-
Fusing with Entity Embeddings: The low-dimensional projected LLM representations are then combined with standalone entity embeddings, which are learned jointly during the training process.
The fused representations are trained end-to-end using a multi-task objective that includes knowledge base completion and entity typing tasks. This allows the model to learn representations that are effective for both reasoning about entity relationships and classifying entity types.
The experiments in the paper demonstrate that BabelFusion outperforms standalone LLM-based and entity embedding models on both knowledge base completion and entity typing benchmarks. The authors attribute this performance gain to the complementary nature of the fused representations, which capture rich semantic and structural information about entities.
Critical Analysis
The paper presents a compelling approach to enhancing knowledge representations by fusing entity embeddings with LLM-based representations. A key strength is the ability to leverage the strengths of both approaches - the compact and structured nature of entity embeddings, and the rich semantic information captured by LLMs.
However, one potential limitation is the reliance on a pre-trained LLM, which may limit the model's ability to generalize to domains or languages not covered by the original LLM. Additionally, the low-rank projection used to reduce the dimensionality of the LLM representations could potentially lead to a loss of important information.
Further research could explore alternative methods for integrating LLM-based and entity embedding representations, such as using more sophisticated fusion techniques or jointly learning the projection and fusion components. Evaluating the model's performance on a wider range of knowledge-intensive tasks would also help assess its broader applicability.
Conclusion
The BabelFusion approach presented in this paper offers a promising way to enhance knowledge representations by fusing entity embeddings with low-dimensional projections of LLM-based representations. By combining the strengths of these two complementary information sources, the model is able to achieve superior performance on tasks like knowledge base completion and entity typing.
This work highlights the potential for leveraging large language models to improve the efficiency and effectiveness of knowledge representation learning, which has important implications for a wide range of applications that rely on structured knowledge, such as question answering, knowledge-based reasoning, and information retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AutoML-guided Fusion of Entity and LLM-based representations
Boshko Koloski, Senja Pollak, Roberto Navigli, Blav{z} v{S}krlj
Large semantic knowledge bases are grounded in factual knowledge. However, recent approaches to dense text representations (embeddings) do not efficiently exploit these resources. Dense and robust representations of documents are essential for effectively solving downstream classification and retrieval tasks. This work demonstrates that injecting embedded information from knowledge bases can augment the performance of contemporary Large Language Model (LLM)-based representations for the task of text classification. Further, by considering automated machine learning (AutoML) with the fused representation space, we demonstrate it is possible to improve classification accuracy even if we use low-dimensional projections of the original representation space obtained via efficient matrix factorization. This result shows that significantly faster classifiers can be achieved with minimal or no loss in predictive performance, as demonstrated using five strong LLM baselines on six diverse real-life datasets.
Read more8/20/2024

0
Towards Ontology-Enhanced Representation Learning for Large Language Models
Francesco Ronzano, Jay Nanavati
Taking advantage of the widespread use of ontologies to organise and harmonize knowledge across several distinct domains, this paper proposes a novel approach to improve an embedding-Large Language Model (embedding-LLM) of interest by infusing the knowledge formalized by a reference ontology: ontological knowledge infusion aims at boosting the ability of the considered LLM to effectively model the knowledge domain described by the infused ontology. The linguistic information (i.e. concept synonyms and descriptions) and structural information (i.e. is-a relations) formalized by the ontology are utilized to compile a comprehensive set of concept definitions, with the assistance of a powerful generative LLM (i.e. GPT-3.5-turbo). These concept definitions are then employed to fine-tune the target embedding-LLM using a contrastive learning framework. To demonstrate and evaluate the proposed approach, we utilize the biomedical disease ontology MONDO. The results show that embedding-LLMs enhanced by ontological disease knowledge exhibit an improved capability to effectively evaluate the similarity of in-domain sentences from biomedical documents mentioning diseases, without compromising their out-of-domain performance.
Read more6/3/2024

0
Large Language Model Enhanced Knowledge Representation Learning: A Survey
Xin Wang, Zirui Chen, Haofen Wang, Leong Hou U, Zhao Li, Wenbin Guo
The integration of Large Language Models (LLM) with Knowledge Representation Learning (KRL) signifies a significant advancement in the field of artificial intelligence (AI), enhancing the ability to capture and utilize both structure and textual information. Despite the increasing research on enhancing KRL with LLMs, a thorough survey that analyse processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain.
Read more7/19/2024
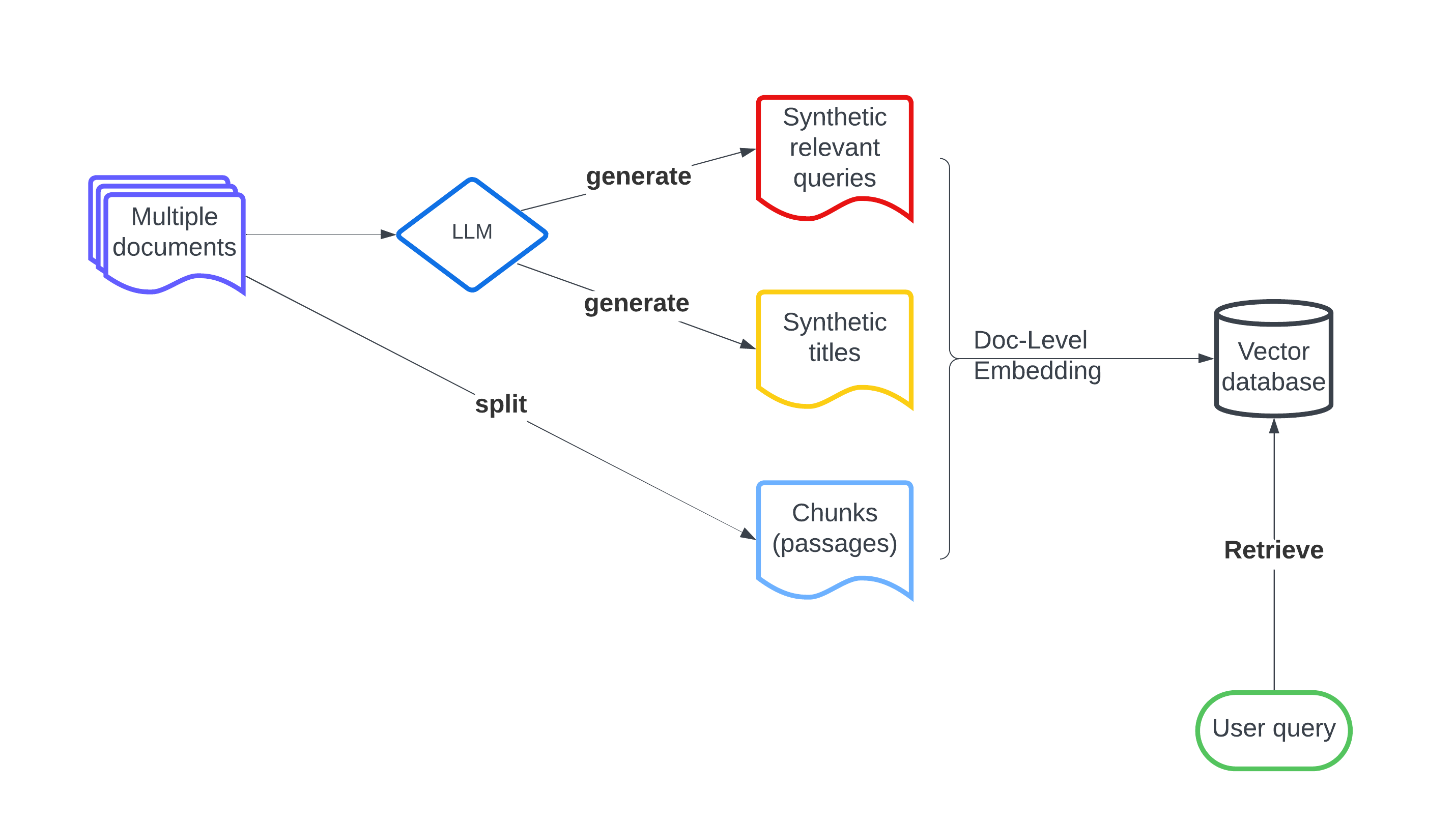
0
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024