Large Language Model Enhanced Knowledge Representation Learning: A Survey
2407.00936
0
0

Abstract
The integration of Large Language Models (LLMs) with Knowledge Representation Learning (KRL) signifies a pivotal advancement in the field of artificial intelligence, enhancing the ability to capture and utilize complex knowledge structures. This synergy leverages the advanced linguistic and contextual understanding capabilities of LLMs to improve the accuracy, adaptability, and efficacy of KRL, thereby expanding its applications and potential. Despite the increasing volume of research focused on embedding LLMs within the domain of knowledge representation, a thorough review that examines the fundamental components and processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain, proposing pathways for continued progress.
Create account to get full access
Overview
- This paper provides a comprehensive survey of the role of large language models (LLMs) in enhancing knowledge representation learning.
- It covers the fundamentals of LLMs and their applications in areas like natural language processing, image analysis, and recommendation systems.
- The paper also discusses the challenges and perspectives associated with using LLMs for knowledge representation learning.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. In this paper, the authors explore how these LLMs can be used to improve the way computers learn and represent knowledge.
Traditionally, knowledge representation has been a challenge for computers. They struggle to capture the nuanced and interconnected nature of human knowledge. However, the authors suggest that LLMs, with their ability to understand and generate language, can help overcome these limitations.
By incorporating LLMs into the knowledge representation learning process, computers can better understand the relationships between different concepts and extract more meaningful insights from data. This could lead to improvements in a wide range of applications, from natural language processing to image analysis and recommendation systems.
However, the authors also highlight the challenges and perspectives associated with using LLMs for knowledge representation learning. For example, these models can be computationally expensive and may struggle with tasks that require deep reasoning or domain-specific knowledge.
Overall, this paper provides a comprehensive overview of the exciting potential of LLMs to revolutionize the way computers understand and represent knowledge. As these technologies continue to evolve, we can expect to see even more innovative applications in a variety of fields.
Technical Explanation
The paper begins by introducing the fundamentals of large language models (LLMs) and their applications in various domains, including natural language processing, image analysis, and recommendation systems.
The authors then delve into the core focus of the paper: the role of LLMs in enhancing knowledge representation learning. They explain how traditional knowledge representation approaches have struggled to capture the complexity and interconnectedness of human knowledge, and how LLMs can potentially address these limitations.
The paper outlines several ways in which LLMs can be incorporated into the knowledge representation learning process, such as using them to extract semantic relationships, generate knowledge graphs, and augment existing knowledge bases. The authors also discuss the potential benefits of this approach, including improved understanding of concepts, more accurate inference, and better support for complex reasoning tasks.
To support their claims, the authors review a range of relevant research studies and highlight key insights and findings. For example, they discuss how LLMs can learn to represent and reason about abstract concepts, and how they can be used to generate novel knowledge by combining and extrapolating from existing information.
The paper also addresses the challenges and perspectives associated with using LLMs for knowledge representation learning. These include the computational complexity of training and deploying LLMs, the potential for biases and inconsistencies in the knowledge they acquire, and the need for domain-specific fine-tuning to ensure accurate and reliable performance.
Overall, the technical explanation covers the key elements of the paper, including the experimental design, the proposed approaches, and the insights and limitations identified by the authors. The paper provides a comprehensive and well-researched overview of this important and rapidly evolving field.
Critical Analysis
The paper presents a thorough and well-researched survey of the role of large language models (LLMs) in enhancing knowledge representation learning. The authors have done an excellent job of highlighting the potential benefits of this approach, as well as the challenges and perspectives that need to be addressed.
One of the key strengths of the paper is its comprehensive coverage of the relevant research in this area. The authors have reviewed a wide range of studies and extracted the most relevant insights and findings. This provides readers with a strong foundation for understanding the current state of the field and the ongoing research efforts.
However, the paper could have been strengthened by a more in-depth discussion of the limitations and potential drawbacks of using LLMs for knowledge representation learning. While the authors do touch on some of these issues, such as the computational complexity and the potential for biases, they could have explored these topics in greater depth.
Additionally, the paper could have benefited from a more critical analysis of the research methodologies and experimental designs used in the reviewed studies. This could have helped readers to better evaluate the validity and reliability of the reported findings.
Despite these minor shortcomings, the paper remains an excellent resource for researchers and practitioners working in the field of knowledge representation learning. The authors have done a commendable job of synthesizing a vast amount of information and presenting it in a clear and accessible manner.
Conclusion
This paper provides a comprehensive survey of the role of large language models (LLMs) in enhancing knowledge representation learning. The authors have demonstrated the potential of LLMs to address the limitations of traditional knowledge representation approaches and improve our understanding of complex, interconnected concepts.
The paper covers a wide range of applications, from natural language processing to image analysis and recommendation systems, and highlights the key challenges and perspectives associated with using LLMs for knowledge representation learning.
As the field of AI continues to evolve, the insights and findings presented in this paper will be invaluable for researchers and practitioners working to push the boundaries of what's possible in knowledge representation and beyond. By leveraging the power of LLMs, we may unlock new and exciting possibilities for how computers understand and interact with the world around us.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Large Knowledge Model: Perspectives and Challenges
Huajun Chen
0
0
Humankind's understanding of the world is fundamentally linked to our perception and cognition, with emph{human languages} serving as one of the major carriers of emph{world knowledge}. In this vein, emph{Large Language Models} (LLMs) like ChatGPT epitomize the pre-training of extensive, sequence-based world knowledge into neural networks, facilitating the processing and manipulation of this knowledge in a parametric space. This article explores large models through the lens of knowledge. We initially investigate the role of symbolic knowledge such as Knowledge Graphs (KGs) in enhancing LLMs, covering aspects like knowledge-augmented language model, structure-inducing pre-training, knowledgeable prompts, structured CoT, knowledge editing, semantic tools for LLM and knowledgeable AI agents. Subsequently, we examine how LLMs can boost traditional symbolic knowledge bases, encompassing aspects like using LLM as KG builder and controller, structured knowledge pretraining, and LLM-enhanced symbolic reasoning. Considering the intricate nature of human knowledge, we advocate for the creation of emph{Large Knowledge Models} (LKM), specifically engineered to manage diversified spectrum of knowledge structures. This promising undertaking would entail several key challenges, such as disentangling knowledge base from language models, cognitive alignment with human knowledge, integration of perception and cognition, and building large commonsense models for interacting with physical world, among others. We finally propose a five-A principle to distinguish the concept of LKM.
6/27/2024
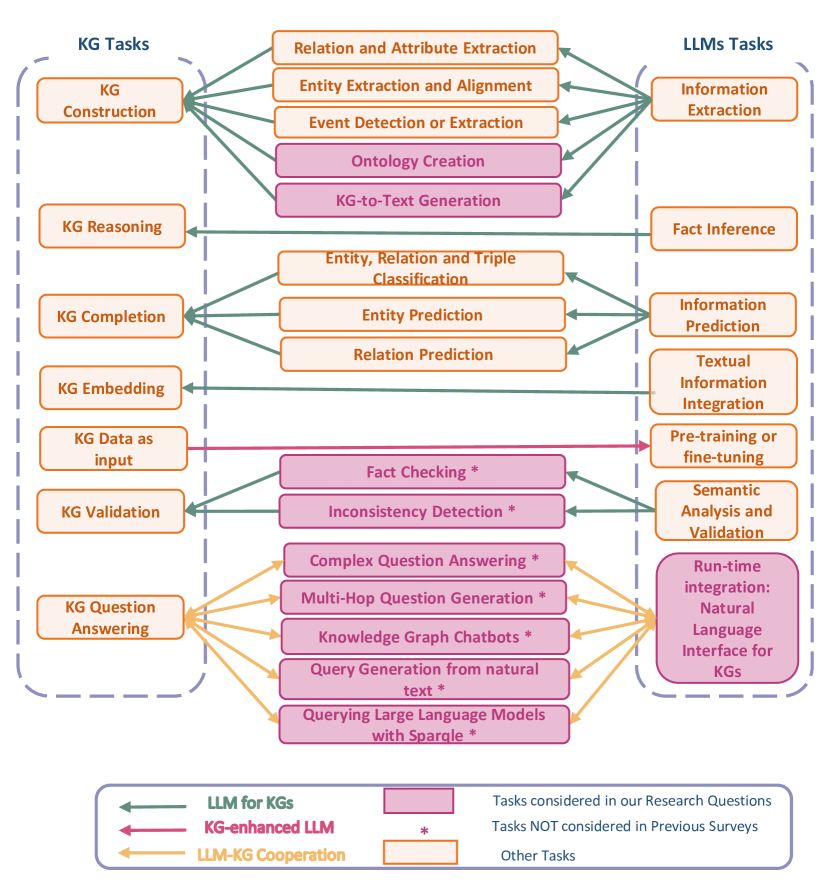
Research Trends for the Interplay between Large Language Models and Knowledge Graphs
Hanieh Khorashadizadeh, Fatima Zahra Amara, Morteza Ezzabady, Fr'ed'eric Ieng, Sanju Tiwari, Nandana Mihindukulasooriya, Jinghua Groppe, Soror Sahri, Farah Benamara, Sven Groppe
0
0
This survey investigates the synergistic relationship between Large Language Models (LLMs) and Knowledge Graphs (KGs), which is crucial for advancing AI's capabilities in understanding, reasoning, and language processing. It aims to address gaps in current research by exploring areas such as KG Question Answering, ontology generation, KG validation, and the enhancement of KG accuracy and consistency through LLMs. The paper further examines the roles of LLMs in generating descriptive texts and natural language queries for KGs. Through a structured analysis that includes categorizing LLM-KG interactions, examining methodologies, and investigating collaborative uses and potential biases, this study seeks to provide new insights into the combined potential of LLMs and KGs. It highlights the importance of their interaction for improving AI applications and outlines future research directions.
6/13/2024
💬
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
5/24/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024