AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing

0

Sign in to get full access
Overview
- This paper introduces AutoSafeCoder, a multi-agent framework for securing code generation by large language models (LLMs) through static analysis and fuzz testing.
- The key goal is to improve the safety and security of code produced by LLMs, which can be prone to vulnerabilities.
- The framework uses a combination of static analysis, fuzz testing, and a multi-agent architecture to identify and mitigate potential issues in the generated code.
Plain English Explanation
The paper presents a system called AutoSafeCoder that helps make code generated by large language models (LLMs) more secure. LLMs are powerful AI models that can produce human-like text, including code. However, the code they generate may contain vulnerabilities or security flaws.
AutoSafeCoder uses a combination of techniques to improve the safety of the generated code:
- Static Analysis: It analyzes the code statically (without running it) to identify potential issues, such as security vulnerabilities or coding errors.
- Fuzz Testing: It applies random inputs to the generated code to see how it behaves and uncover any bugs or vulnerabilities.
- Multi-Agent Architecture: It uses a team of specialized agents, each focused on a different aspect of code security, to work together to analyze and improve the generated code.
The goal is to catch and fix issues in the code before it is used, making it more secure and reliable. This is important because LLM-generated code is becoming more common, and it needs to be just as safe as code written by human developers.
Technical Explanation
The AutoSafeCoder paper presents a multi-agent framework for securing code generation by large language models (LLMs) through static analysis and fuzz testing.
The key components of the framework are:
- Static Analysis Agent: This agent uses static code analysis techniques to identify potential security vulnerabilities, coding errors, and other issues in the generated code.
- Fuzz Testing Agent: This agent applies random, invalid, or unexpected inputs to the generated code to uncover bugs or vulnerabilities that may not be detected by static analysis.
- Coordination Agent: This agent manages the overall workflow, orchestrating the actions of the Static Analysis and Fuzz Testing agents and deciding when the generated code is ready for deployment.
The paper describes the architecture and workflow of the system, as well as the specific techniques used by each agent. For example, the Static Analysis Agent employs a range of security-focused static analysis tools, while the Fuzz Testing Agent uses advanced fuzz testing algorithms to generate effective test cases.
The authors evaluate the effectiveness of AutoSafeCoder on a dataset of LLM-generated code and demonstrate that it is able to identify and mitigate a significant number of security issues, including vulnerabilities, coding errors, and performance problems.
Critical Analysis
The AutoSafeCoder paper presents a promising approach to improving the security of code generated by large language models (LLMs). The use of a multi-agent framework, combining static analysis and fuzz testing, is a well-designed strategy for addressing the unique challenges posed by LLM-generated code.
One potential limitation of the research is that it focuses primarily on identified security issues and may not fully capture the broader range of code quality and maintainability concerns. While security is a critical aspect, the long-term viability and usability of LLM-generated code also depend on factors such as code readability, modularity, and adherence to best practices.
Additionally, the evaluation in the paper is conducted on a limited dataset of LLM-generated code, and it would be valuable to see the framework tested on a wider range of code samples and real-world applications to further validate its effectiveness.
Overall, the AutoSafeCoder paper makes a valuable contribution to the ongoing efforts to ensure the safety and reliability of LLM-generated code. As LLMs become more prevalent in software development, frameworks like AutoSafeCoder will play an increasingly important role in maintaining the security and quality of the generated code.
Conclusion
The AutoSafeCoder paper presents a multi-agent framework for securing code generation by large language models (LLMs) through static analysis and fuzz testing. By combining these techniques in a coordinated, multi-agent architecture, the framework aims to identify and mitigate potential security issues and vulnerabilities in the generated code.
The research demonstrates the effectiveness of this approach and highlights the growing importance of ensuring the safety and reliability of LLM-generated code as it becomes more widely adopted in software development. As LLMs continue to advance, frameworks like AutoSafeCoder will play a crucial role in maintaining the integrity of the code they produce, ultimately contributing to the broader goal of making AI-generated code as secure and trustworthy as human-written code.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!AutoSafeCoder: A Multi-Agent Framework for Securing LLM Code Generation through Static Analysis and Fuzz Testing
Ana Nunez, Nafis Tanveer Islam, Sumit Kumar Jha, Peyman Najafirad
Recent advancements in automatic code generation using large language models (LLMs) have brought us closer to fully automated secure software development. However, existing approaches often rely on a single agent for code generation, which struggles to produce secure, vulnerability-free code. Traditional program synthesis with LLMs has primarily focused on functional correctness, often neglecting critical dynamic security implications that happen during runtime. To address these challenges, we propose AutoSafeCoder, a multi-agent framework that leverages LLM-driven agents for code generation, vulnerability analysis, and security enhancement through continuous collaboration. The framework consists of three agents: a Coding Agent responsible for code generation, a Static Analyzer Agent identifying vulnerabilities, and a Fuzzing Agent performing dynamic testing using a mutation-based fuzzing approach to detect runtime errors. Our contribution focuses on ensuring the safety of multi-agent code generation by integrating dynamic and static testing in an iterative process during code generation by LLM that improves security. Experiments using the SecurityEval dataset demonstrate a 13% reduction in code vulnerabilities compared to baseline LLMs, with no compromise in functionality.
Read more9/18/2024

0
Code Agents are State of the Art Software Testers
Niels Mundler, Mark Niklas Muller, Jingxuan He, Martin Vechev
Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents for formalizing user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth patches, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using fail-to-pass rate and coverage metrics, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent.
Read more6/21/2024

0
Is Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jiexin Wang, Xitong Luo, Liuwen Cao, Hongkui He, Hailin Huang, Jiayuan Xie, Adam Jatowt, Yi Cai
Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Read more7/8/2024
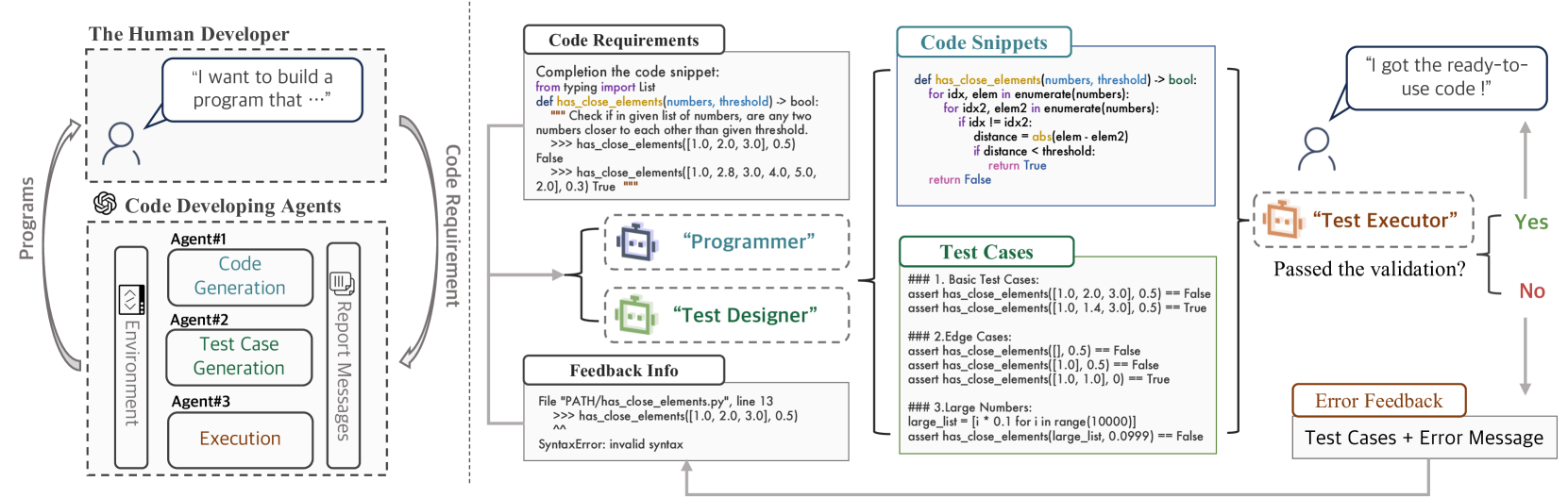
0
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Jie M. Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, Heming Cui
The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder (GPT-4) achieves 96.3% and 91.8% pass@1 in HumanEval and MBPP datasets with an overall token overhead of 56.9K and 66.3K, while state-of-the-art obtains only 90.2% and 78.9% pass@1 with an overall token overhead of 138.2K and 206.5K.
Read more5/27/2024