AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
2406.07686
0
0
Abstract
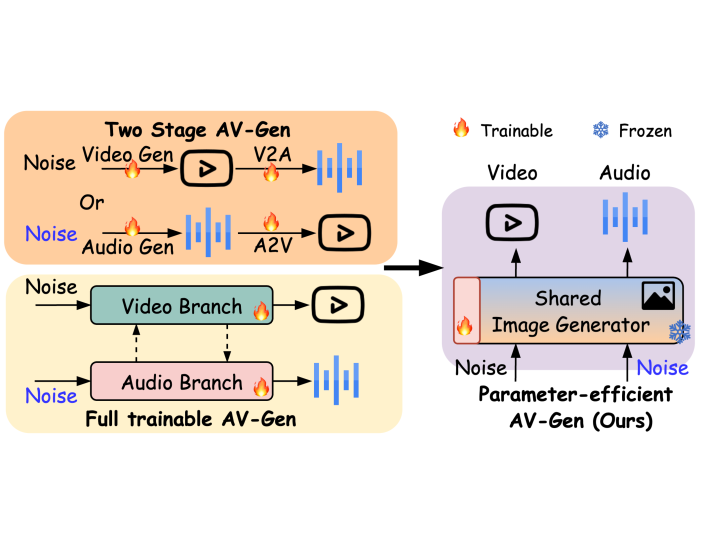
Recent Diffusion Transformers (DiTs) have shown impressive capabilities in generating high-quality single-modality content, including images, videos, and audio. However, it is still under-explored whether the transformer-based diffuser can efficiently denoise the Gaussian noises towards superb multimodal content creation. To bridge this gap, we introduce AV-DiT, a novel and efficient audio-visual diffusion transformer designed to generate high-quality, realistic videos with both visual and audio tracks. To minimize model complexity and computational costs, AV-DiT utilizes a shared DiT backbone pre-trained on image-only data, with only lightweight, newly inserted adapters being trainable. This shared backbone facilitates both audio and video generation. Specifically, the video branch incorporates a trainable temporal attention layer into a frozen pre-trained DiT block for temporal consistency. Additionally, a small number of trainable parameters adapt the image-based DiT block for audio generation. An extra shared DiT block, equipped with lightweight parameters, facilitates feature interaction between audio and visual modalities, ensuring alignment. Extensive experiments on the AIST++ and Landscape datasets demonstrate that AV-DiT achieves state-of-the-art performance in joint audio-visual generation with significantly fewer tunable parameters. Furthermore, our results highlight that a single shared image generative backbone with modality-specific adaptations is sufficient for constructing a joint audio-video generator. Our source code and pre-trained models will be released.
Create account to get full access
Overview
- This paper presents a new model called AV-DiT (Audio-Visual Diffusion Transformer) that can generate both audio and video content simultaneously.
- The model uses a diffusion-based approach, which involves gradually adding noise to the input data and then learning to reverse the process to generate new content.
- AV-DiT is designed to be efficient and scalable, allowing it to handle high-resolution audio and video inputs.
Plain English Explanation
AV-DiT is a machine learning model that can create both audio and video content at the same time. It works by starting with a noisy version of the desired output and then gradually refining it to become a clear, high-quality audio and video clip.
The key innovation of AV-DiT is that it can handle audio and video inputs efficiently, allowing it to generate high-resolution content without requiring a lot of computational resources. This makes it a practical tool for applications like video generation or text-to-speech systems.
The model uses a technique called diffusion, which involves adding noise to the input data and then learning to reverse that process. This allows AV-DiT to generate novel content from scratch, rather than just modifying existing media.
Overall, AV-DiT represents an important step forward in the field of generative AI, demonstrating how audio and video can be generated together in an efficient and scalable way.
Technical Explanation
The core of AV-DiT is a diffusion-based architecture that operates on both audio and video inputs simultaneously. The model starts with a noisy version of the desired output and then uses a series of denoising steps to gradually refine the content.
This diffusion process is implemented using a transformer-based neural network, which allows AV-DiT to capture the complex relationships between the audio and video components. The model also employs techniques like efficient quantization to reduce the computational burden and enable high-resolution generation.
Through extensive experiments, the authors demonstrate that AV-DiT outperforms previous state-of-the-art models on a range of audio-visual generation tasks. The model is able to generate cohesive and realistic content, with the audio and video components seamlessly synchronized.
Critical Analysis
The AV-DiT paper presents a promising approach to the challenging problem of joint audio and video generation. The use of a diffusion-based transformer architecture is a clever way to handle the complexity of this task, and the authors have done a good job of optimizing the model for efficiency and scalability.
However, the paper does not explore the limitations of the approach in depth. For example, it would be interesting to understand how AV-DiT performs on more diverse or challenging audio-visual datasets, or how it compares to other generative models like VAEs or GANs in terms of sample quality and diversity.
Additionally, the paper does not delve into the potential social implications or ethical considerations of this type of technology. As generative AI models become more advanced, it will be important to carefully consider their potential for misuse or unintended consequences.
Overall, AV-DiT represents an interesting and promising development in the field of audio-visual generation. However, further research and critical analysis will be necessary to fully understand the capabilities and limitations of this approach.
Conclusion
The AV-DiT model presented in this paper is a significant advancement in the field of joint audio and video generation. By leveraging a diffusion-based transformer architecture, the authors have developed a scalable and efficient model that can generate high-quality audio-visual content.
The key innovation of AV-DiT is its ability to handle both audio and video inputs simultaneously, allowing for the creation of cohesive and synchronized multimedia. This could have important implications for a wide range of applications, from virtual assistants and text-to-speech systems to video generation and generative AI.
While the paper demonstrates the effectiveness of AV-DiT, it also highlights the need for further research to fully understand the capabilities and limitations of this approach. As generative AI models become more advanced, it will be crucial to carefully consider the ethical and social implications of this technology.
Overall, the AV-DiT paper represents an important step forward in the field of audio-visual generation, and the ideas and techniques presented here are likely to inspire further innovation and progress in this exciting area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, Jos'e Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli
0
0
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
5/24/2024

Complex Image-Generative Diffusion Transformer for Audio Denoising
Junhui Li, Pu Wang, Jialu Li, Youshan Zhang
0
0
The audio denoising technique has captured widespread attention in the deep neural network field. Recently, the audio denoising problem has been converted into an image generation task, and deep learning-based approaches have been applied to tackle this problem. However, its performance is still limited, leaving room for further improvement. In order to enhance audio denoising performance, this paper introduces a complex image-generative diffusion transformer that captures more information from the complex Fourier domain. We explore a novel diffusion transformer by integrating the transformer with a diffusion model. Our proposed model demonstrates the scalability of the transformer and expands the receptive field of sparse attention using attention diffusion. Our work is among the first to utilize diffusion transformers to deal with the image generation task for audio denoising. Extensive experiments on two benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods.
6/14/2024

ViDiT-Q: Efficient and Accurate Quantization of Diffusion Transformers for Image and Video Generation
Tianchen Zhao, Tongcheng Fang, Enshu Liu, Wan Rui, Widyadewi Soedarmadji, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, Yu Wang
0
0
Diffusion transformers (DiTs) have exhibited remarkable performance in visual generation tasks, such as generating realistic images or videos based on textual instructions. However, larger model sizes and multi-frame processing for video generation lead to increased computational and memory costs, posing challenges for practical deployment on edge devices. Post-Training Quantization (PTQ) is an effective method for reducing memory costs and computational complexity. When quantizing diffusion transformers, we find that applying existing diffusion quantization methods designed for U-Net faces challenges in preserving quality. After analyzing the major challenges for quantizing diffusion transformers, we design an improved quantization scheme: ViDiT-Q: Video and Image Diffusion Transformer Quantization) to address these issues. Furthermore, we identify highly sensitive layers and timesteps hinder quantization for lower bit-widths. To tackle this, we improve ViDiT-Q with a novel metric-decoupled mixed-precision quantization method (ViDiT-Q-MP). We validate the effectiveness of ViDiT-Q across a variety of text-to-image and video models. While baseline quantization methods fail at W8A8 and produce unreadable content at W4A8, ViDiT-Q achieves lossless W8A8 quantization. ViDiTQ-MP achieves W4A8 with negligible visual quality degradation, resulting in a 2.5x memory optimization and a 1.5x latency speedup.
6/5/2024
Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
Shiqi Yang, Zhi Zhong, Mengjie Zhao, Shusuke Takahashi, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
5/27/2024