A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
2405.13762
0
0
Abstract
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
Create account to get full access
Overview
• This paper presents a versatile diffusion transformer model capable of generating audiovisual content by leveraging a mixture of noise levels. • The key ideas include:
- Using a diffusion transformer architecture that can handle both audio and visual inputs.
- Incorporating a mixture of noise levels during the diffusion process to improve the model's generative capabilities.
- Demonstrating the model's versatility through its ability to perform tasks like image generation, audio generation, and audiovisual generation.
Plain English Explanation
The researchers have developed a powerful AI model that can create both images and sounds. This model is based on a diffusion transformer, which means it uses a series of steps to gradually transform simple noise into complex, realistic-looking images and sounds.
One of the novel aspects of this model is that it uses a "mixture of noise levels" during the diffusion process. This means the model is trained on a variety of noise levels, from very subtle to very strong. This helps the model become more versatile and able to generate a wider range of content, from clear and detailed images and sounds to more abstract and creative ones.
The model can be used for a variety of tasks, such as generating images, generating audio, or even generating images and audio together, like in a video or animation. This makes it a very flexible and powerful tool for creators and researchers working in areas like visual-echoes-simple-unified-transformer-audio-visual, sonicdiffusion-audio-driven-image-generation-editing-pretrained, empowering-diffusion-models-embedding-space-text-generation, generative-ai-beyond-llms-system-implications-multi, and diffscaler-enhancing-generative-prowess-diffusion-transformers.
Technical Explanation
The paper introduces a novel diffusion transformer model that can generate both audio and visual content. The key technical innovations include:
-
Diffusion Transformer Architecture: The model uses a transformer-based architecture that can process both audio and visual inputs, allowing it to generate audiovisual content.
-
Mixture of Noise Levels: During the diffusion process, the model is trained on a mixture of noise levels, from very subtle to very strong. This helps the model become more versatile and able to generate a wider range of content.
-
Multimodal Generation: The model is capable of performing various generation tasks, including image generation, audio generation, and audiovisual generation. This demonstrates the model's versatility and broad applicability.
The paper presents experimental results that showcase the model's impressive performance on these different generation tasks, highlighting its ability to create high-quality, diverse, and coherent audiovisual content.
Critical Analysis
The paper presents a well-designed and comprehensive study on a novel diffusion transformer model for audiovisual generation. The key strengths of the research include:
-
Versatility: The ability of the model to handle multiple modalities (audio and visual) and perform various generation tasks is a significant advancement in the field of generative AI.
-
Noise Level Mixture: The incorporation of a mixture of noise levels during the diffusion process is a unique and potentially impactful contribution, as it enhances the model's generative capabilities.
-
Thorough Experimentation: The paper presents a robust set of experiments that thoroughly evaluate the model's performance on different tasks, providing a comprehensive understanding of its strengths and limitations.
However, the paper could be further improved by addressing the following potential limitations:
-
Computational Complexity: The use of a transformer-based architecture and the mixture of noise levels may increase the computational requirements of the model, which could limit its practical deployment in certain scenarios.
-
Evaluation of Audiovisual Coherence: While the paper assesses the individual quality of generated audio and visual content, it could benefit from a more in-depth evaluation of the coherence and synchronization between the two modalities in the generated audiovisual samples.
-
Potential Biases: As with any generative model, it is essential to investigate potential biases in the training data and their impact on the generated content, especially when dealing with multimodal generation.
Overall, the paper presents a significant contribution to the field of generative AI, and the proposed diffusion transformer model with a mixture of noise levels showcases promising avenues for further research and real-world applications in areas like visual-echoes-simple-unified-transformer-audio-visual, sonicdiffusion-audio-driven-image-generation-editing-pretrained, empowering-diffusion-models-embedding-space-text-generation, generative-ai-beyond-llms-system-implications-multi, and diffscaler-enhancing-generative-prowess-diffusion-transformers.
Conclusion
This paper presents a novel diffusion transformer model that can generate both audio and visual content by leveraging a mixture of noise levels during the diffusion process. The model's versatility, demonstrated through its ability to perform various generation tasks, is a significant advancement in the field of generative AI.
The incorporation of a mixture of noise levels during the diffusion process is a unique contribution that enhances the model's generative capabilities, allowing it to create a diverse range of high-quality audiovisual content. The thorough experimental evaluation provides a comprehensive understanding of the model's strengths and potential limitations, paving the way for further research and real-world applications in areas like visual-echoes-simple-unified-transformer-audio-visual, sonicdiffusion-audio-driven-image-generation-editing-pretrained, empowering-diffusion-models-embedding-space-text-generation, generative-ai-beyond-llms-system-implications-multi, and diffscaler-enhancing-generative-prowess-diffusion-transformers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
Shiqi Yang, Zhi Zhong, Mengjie Zhao, Shusuke Takahashi, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
5/27/2024
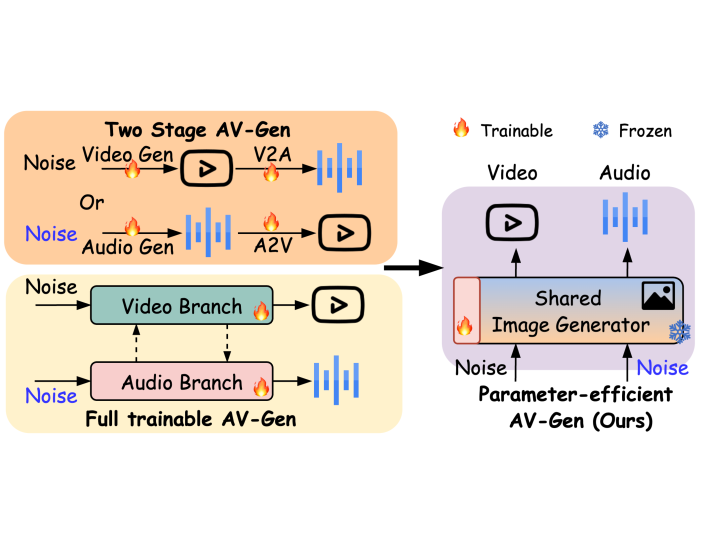
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian
0
0
Recent Diffusion Transformers (DiTs) have shown impressive capabilities in generating high-quality single-modality content, including images, videos, and audio. However, it is still under-explored whether the transformer-based diffuser can efficiently denoise the Gaussian noises towards superb multimodal content creation. To bridge this gap, we introduce AV-DiT, a novel and efficient audio-visual diffusion transformer designed to generate high-quality, realistic videos with both visual and audio tracks. To minimize model complexity and computational costs, AV-DiT utilizes a shared DiT backbone pre-trained on image-only data, with only lightweight, newly inserted adapters being trainable. This shared backbone facilitates both audio and video generation. Specifically, the video branch incorporates a trainable temporal attention layer into a frozen pre-trained DiT block for temporal consistency. Additionally, a small number of trainable parameters adapt the image-based DiT block for audio generation. An extra shared DiT block, equipped with lightweight parameters, facilitates feature interaction between audio and visual modalities, ensuring alignment. Extensive experiments on the AIST++ and Landscape datasets demonstrate that AV-DiT achieves state-of-the-art performance in joint audio-visual generation with significantly fewer tunable parameters. Furthermore, our results highlight that a single shared image generative backbone with modality-specific adaptations is sufficient for constructing a joint audio-video generator. Our source code and pre-trained models will be released.
6/13/2024
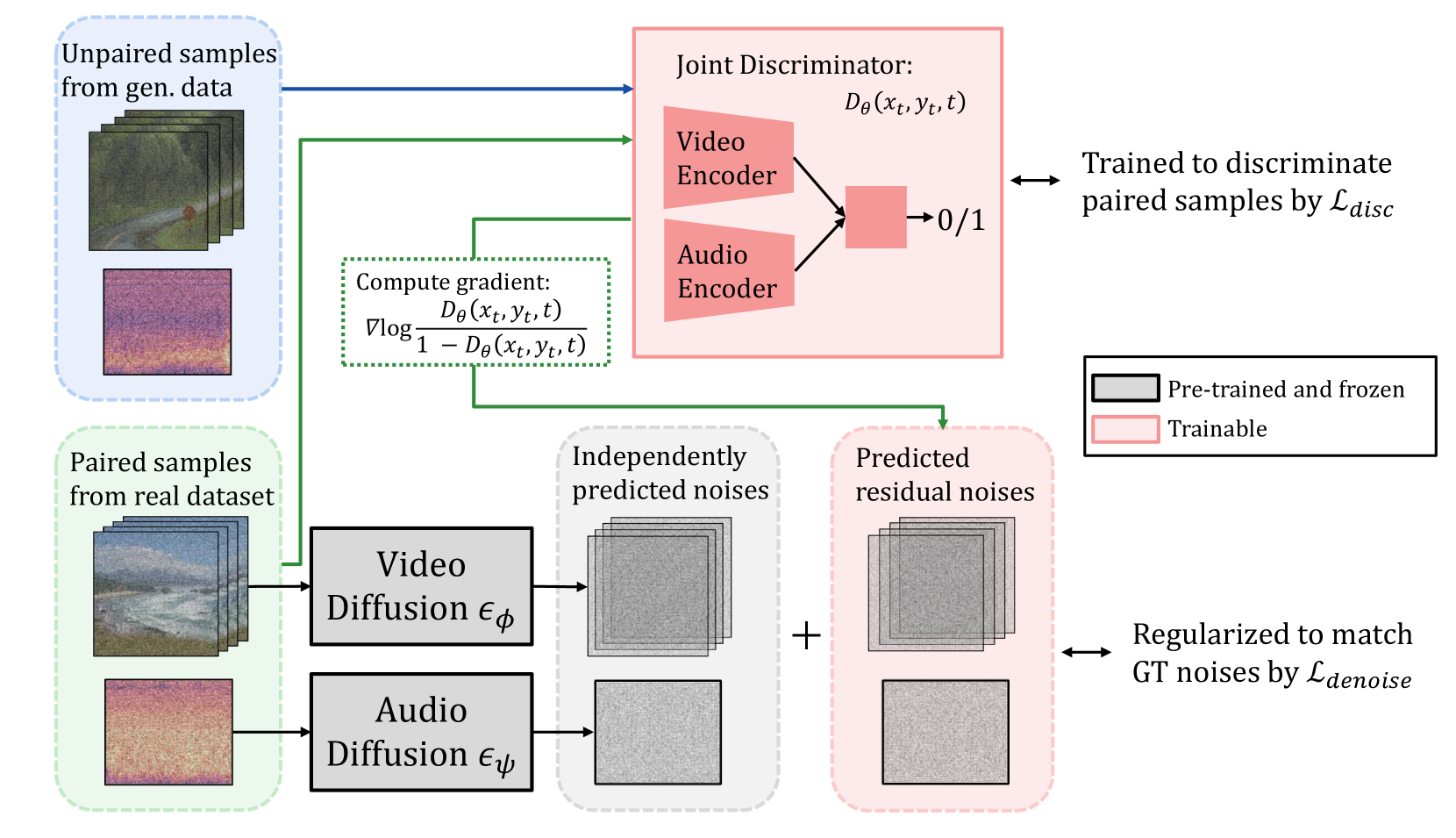
Discriminator-Guided Cooperative Diffusion for Joint Audio and Video Generation
Akio Hayakawa, Masato Ishii, Takashi Shibuya, Yuki Mitsufuji
0
0
In this study, we aim to construct an audio-video generative model with minimal computational cost by leveraging pre-trained single-modal generative models for audio and video. To achieve this, we propose a novel method that guides each single-modal model to cooperatively generate well-aligned samples across modalities. Specifically, given two pre-trained base diffusion models, we train a lightweight joint guidance module to adjust scores separately estimated by the base models to match the score of joint distribution over audio and video. We theoretically show that this guidance can be computed through the gradient of the optimal discriminator distinguishing real audio-video pairs from fake ones independently generated by the base models. On the basis of this analysis, we construct the joint guidance module by training this discriminator. Additionally, we adopt a loss function to make the gradient of the discriminator work as a noise estimator, as in standard diffusion models, stabilizing the gradient of the discriminator. Empirical evaluations on several benchmark datasets demonstrate that our method improves both single-modal fidelity and multi-modal alignment with a relatively small number of parameters.
5/29/2024

SonicDiffusion: Audio-Driven Image Generation and Editing with Pretrained Diffusion Models
Burak Can Biner, Farrin Marouf Sofian, Umur Berkay Karakac{s}, Duygu Ceylan, Erkut Erdem, Aykut Erdem
0
0
We are witnessing a revolution in conditional image synthesis with the recent success of large scale text-to-image generation methods. This success also opens up new opportunities in controlling the generation and editing process using multi-modal input. While spatial control using cues such as depth, sketch, and other images has attracted a lot of research, we argue that another equally effective modality is audio since sound and sight are two main components of human perception. Hence, we propose a method to enable audio-conditioning in large scale image diffusion models. Our method first maps features obtained from audio clips to tokens that can be injected into the diffusion model in a fashion similar to text tokens. We introduce additional audio-image cross attention layers which we finetune while freezing the weights of the original layers of the diffusion model. In addition to audio conditioned image generation, our method can also be utilized in conjuction with diffusion based editing methods to enable audio conditioned image editing. We demonstrate our method on a wide range of audio and image datasets. We perform extensive comparisons with recent methods and show favorable performance.
5/3/2024