Awareness of uncertainty in classification using a multivariate model and multi-views
2404.10314
0
0

Abstract
One of the ways to make artificial intelligence more natural is to give it some room for doubt. Two main questions should be resolved in that way. First, how to train a model to estimate uncertainties of its own predictions? And then, what to do with the uncertain predictions if they appear? First, we proposed an uncertainty-aware negative log-likelihood loss for the case of N-dimensional multivariate normal distribution with spherical variance matrix to the solution of N-classes classification tasks. The loss is similar to the heteroscedastic regression loss. The proposed model regularizes uncertain predictions, and trains to calculate both the predictions and their uncertainty estimations. The model fits well with the label smoothing technique. Second, we expanded the limits of data augmentation at the training and test stages, and made the trained model to give multiple predictions for a given number of augmented versions of each test sample. Given the multi-view predictions together with their uncertainties and confidences, we proposed several methods to calculate final predictions, including mode values and bin counts with soft and hard weights. For the latter method, we formalized the model tuning task in the form of multimodal optimization with non-differentiable criteria of maximum accuracy, and applied particle swarm optimization to solve the tuning task. The proposed methodology was tested using CIFAR-10 dataset with clean and noisy labels and demonstrated good results in comparison with other uncertainty estimation methods related to sample selection, co-teaching, and label smoothing.
Create account to get full access
Overview
- The paper proposes a method to quantify the uncertainty in multi-view classification tasks using a multivariate model.
- It aims to provide a more comprehensive understanding of the uncertainty associated with the classification process.
- The approach leverages multiple data views, such as different feature sets or modalities, to better capture the uncertainty inherent in the classification problem.
Plain English Explanation
The researchers developed a new way to measure the uncertainty in classification tasks that use multiple types of data, such as different sets of features or data from different sensors. In many real-world applications, there is inherent uncertainty in the data, and understanding this uncertainty is crucial for making reliable decisions.
The Hinge-Wasserstein: Estimating Multimodal Aleatoric Uncertainty in Regression and Probabilistic Uncertainty Quantification for Prediction Models: Application to Personalized Medicine papers have also explored ways to quantify uncertainty in different machine learning tasks.
The key idea in this paper is to use multiple "views" of the data, such as different sets of features or data from different sensors, to better understand the uncertainty in the classification process. By considering these multiple perspectives, the researchers can gain a more comprehensive understanding of the uncertainty involved, which can be helpful in applications where reliable decision-making is critical.
Technical Explanation
The paper proposes a method for quantifying uncertainty in multi-view classification tasks using a multivariate model. The approach leverages multiple data views, such as different feature sets or modalities, to better capture the uncertainty inherent in the classification problem.
The Misspecification Uncertainties in Near-Deterministic Regression and A Comprehensive Survey of Uncertainty Quantification in Deep Learning papers have also explored techniques for quantifying uncertainty in machine learning models.
The method involves training a multivariate model that predicts the class probabilities for each data view. The model is designed to capture the correlations and dependencies between the different views, which can provide a more comprehensive understanding of the overall uncertainty in the classification process.
The Calibration-Aware Bayesian Learning paper has also explored approaches for improving the calibration of uncertainty estimates in machine learning models.
The paper presents experiments on several real-world datasets, demonstrating the effectiveness of the proposed approach in quantifying uncertainty and its potential benefits for applications where reliable decision-making is crucial.
Critical Analysis
The paper presents a novel and promising approach for quantifying uncertainty in multi-view classification tasks. However, the authors acknowledge that the proposed method may have some limitations.
One potential concern is the computational complexity of the multivariate model, which could make it challenging to scale to large-scale problems or real-time applications. The authors suggest that further research may be needed to address this issue.
Additionally, the paper does not explore the impact of different types of data views or feature sets on the performance and uncertainty estimates. It would be interesting to see how the method performs under varying data characteristics and whether certain data views are more informative than others for quantifying uncertainty.
The authors also note that the proposed approach assumes that the data views are independent and identically distributed. In practical scenarios, this assumption may not always hold, and further research may be needed to relax this constraint.
Conclusion
The paper presents a novel approach for quantifying uncertainty in multi-view classification tasks using a multivariate model. By leveraging multiple data views, the method aims to provide a more comprehensive understanding of the uncertainty inherent in the classification process.
The proposed technique has the potential to be beneficial in applications where reliable decision-making is crucial, such as medical diagnosis, autonomous systems, or risk management. The authors have demonstrated the effectiveness of their approach on several real-world datasets, but further research may be needed to address potential limitations and explore the impact of different data characteristics on the method's performance.
Overall, this paper contributes to the growing body of research on uncertainty quantification in machine learning, which is an important topic for ensuring the safe and reliable deployment of these technologies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
Hinge-Wasserstein: Estimating Multimodal Aleatoric Uncertainty in Regression Tasks
Ziliang Xiong, Arvi Jonnarth, Abdelrahman Eldesokey, Joakim Johnander, Bastian Wandt, Per-Erik Forssen
0
0
Computer vision systems that are deployed in safety-critical applications need to quantify their output uncertainty. We study regression from images to parameter values and here it is common to detect uncertainty by predicting probability distributions. In this context, we investigate the regression-by-classification paradigm which can represent multimodal distributions, without a prior assumption on the number of modes. Through experiments on a specifically designed synthetic dataset, we demonstrate that traditional loss functions lead to poor probability distribution estimates and severe overconfidence, in the absence of full ground truth distributions. In order to alleviate these issues, we propose hinge-Wasserstein -- a simple improvement of the Wasserstein loss that reduces the penalty for weak secondary modes during training. This enables prediction of complex distributions with multiple modes, and allows training on datasets where full ground truth distributions are not available. In extensive experiments, we show that the proposed loss leads to substantially better uncertainty estimation on two challenging computer vision tasks: horizon line detection and stereo disparity estimation.
6/24/2024
🧠
Just rotate it! Uncertainty estimation in closed-source models via multiple queries
Konstantinos Pitas, Julyan Arbel
0
0
We propose a simple and effective method to estimate the uncertainty of closed-source deep neural network image classification models. Given a base image, our method creates multiple transformed versions and uses them to query the top-1 prediction of the closed-source model. We demonstrate significant improvements in the calibration of uncertainty estimates compared to the naive baseline of assigning 100% confidence to all predictions. While we initially explore Gaussian perturbations, our empirical findings indicate that natural transformations, such as rotations and elastic deformations, yield even better-calibrated predictions. Furthermore, through empirical results and a straightforward theoretical analysis, we elucidate the reasons behind the superior performance of natural transformations over Gaussian noise. Leveraging these insights, we propose a transfer learning approach that further improves our calibration results.
5/24/2024
📶
Epistemic Uncertainty-Weighted Loss for Visual Bias Mitigation
Rebecca S Stone, Nishant Ravikumar, Andrew J Bulpitt, David C Hogg
0
0
Deep neural networks are highly susceptible to learning biases in visual data. While various methods have been proposed to mitigate such bias, the majority require explicit knowledge of the biases present in the training data in order to mitigate. We argue the relevance of exploring methods which are completely ignorant of the presence of any bias, but are capable of identifying and mitigating them. Furthermore, we propose using Bayesian neural networks with a predictive uncertainty-weighted loss function to dynamically identify potential bias in individual training samples and to weight them during training. We find a positive correlation between samples subject to bias and higher epistemic uncertainties. Finally, we show the method has potential to mitigate visual bias on a bias benchmark dataset and on a real-world face detection problem, and we consider the merits and weaknesses of our approach.
6/5/2024
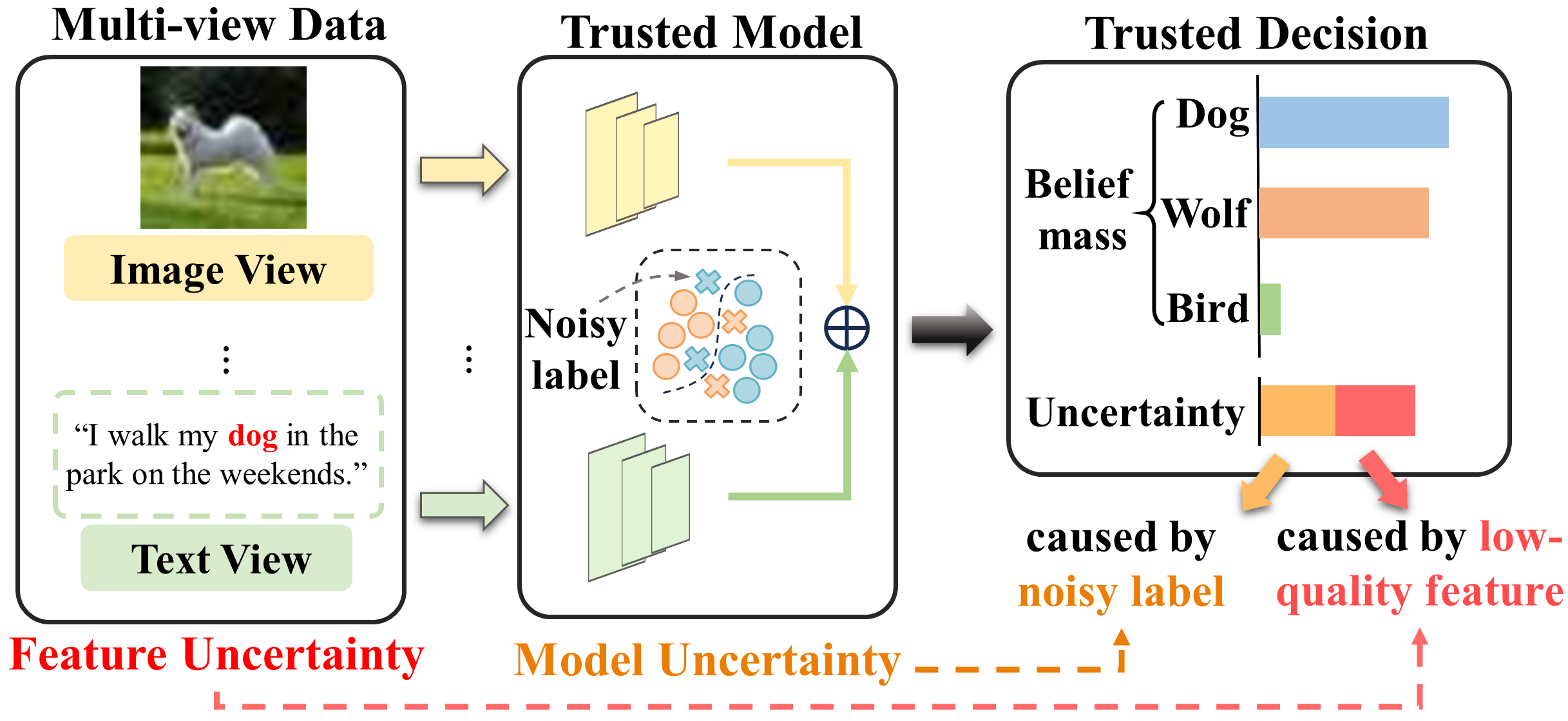
Trusted Multi-view Learning with Label Noise
Cai Xu, Yilin Zhang, Ziyu Guan, Wei Zhao
0
0
Multi-view learning methods often focus on improving decision accuracy while neglecting the decision uncertainty, which significantly restricts their applications in safety-critical applications. To address this issue, researchers propose trusted multi-view methods that learn the class distribution for each instance, enabling the estimation of classification probabilities and uncertainty. However, these methods heavily rely on high-quality ground-truth labels. This motivates us to delve into a new generalized trusted multi-view learning problem: how to develop a reliable multi-view learning model under the guidance of noisy labels? We propose a trusted multi-view noise refining method to solve this problem. We first construct view-opinions using evidential deep neural networks, which consist of belief mass vectors and uncertainty estimates. Subsequently, we design view-specific noise correlation matrices that transform the original opinions into noisy opinions aligned with the noisy labels. Considering label noises originating from low-quality data features and easily-confused classes, we ensure that the diagonal elements of these matrices are inversely proportional to the uncertainty, while incorporating class relations into the off-diagonal elements. Finally, we aggregate the noisy opinions and employ a generalized maximum likelihood loss on the aggregated opinion for model training, guided by the noisy labels. We empirically compare TMNR with state-of-the-art trusted multi-view learning and label noise learning baselines on 5 publicly available datasets. Experiment results show that TMNR outperforms baseline methods on accuracy, reliability and robustness. The code and appendix are released at https://github.com/YilinZhang107/TMNR.
5/13/2024