Trusted Multi-view Learning with Label Noise
2404.11944
0
0
Abstract
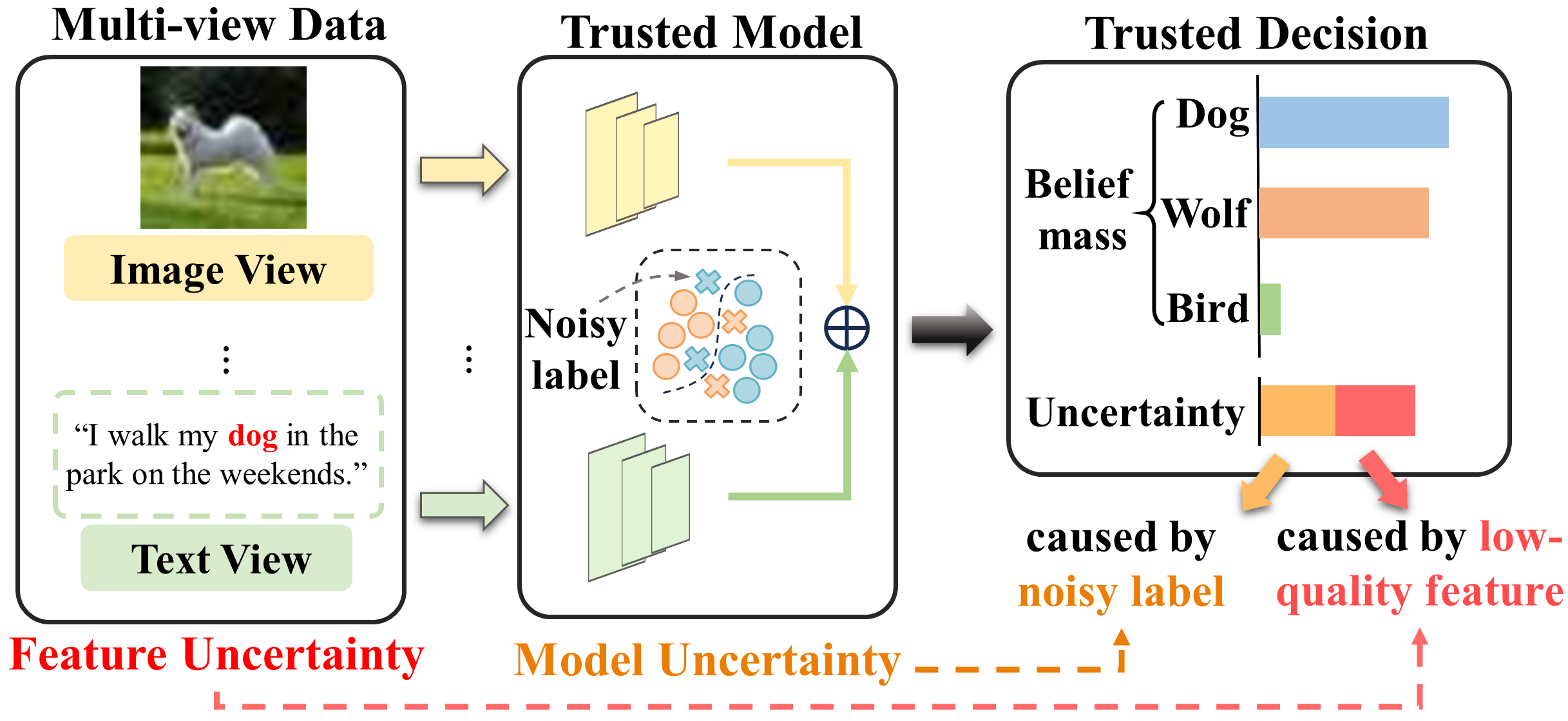
Multi-view learning methods often focus on improving decision accuracy while neglecting the decision uncertainty, which significantly restricts their applications in safety-critical applications. To address this issue, researchers propose trusted multi-view methods that learn the class distribution for each instance, enabling the estimation of classification probabilities and uncertainty. However, these methods heavily rely on high-quality ground-truth labels. This motivates us to delve into a new generalized trusted multi-view learning problem: how to develop a reliable multi-view learning model under the guidance of noisy labels? We propose a trusted multi-view noise refining method to solve this problem. We first construct view-opinions using evidential deep neural networks, which consist of belief mass vectors and uncertainty estimates. Subsequently, we design view-specific noise correlation matrices that transform the original opinions into noisy opinions aligned with the noisy labels. Considering label noises originating from low-quality data features and easily-confused classes, we ensure that the diagonal elements of these matrices are inversely proportional to the uncertainty, while incorporating class relations into the off-diagonal elements. Finally, we aggregate the noisy opinions and employ a generalized maximum likelihood loss on the aggregated opinion for model training, guided by the noisy labels. We empirically compare TMNR with state-of-the-art trusted multi-view learning and label noise learning baselines on 5 publicly available datasets. Experiment results show that TMNR outperforms baseline methods on accuracy, reliability and robustness. The code and appendix are released at https://github.com/YilinZhang107/TMNR.
Create account to get full access
Overview
- This paper proposes a trusted multi-view learning framework to handle label noise in multi-view data.
- The approach leverages multiple views of the data to learn a robust model that can accurately classify samples, even in the presence of noisy labels.
- The framework combines self-supervised learning and meta-learning techniques to learn reliable classifiers.
Plain English Explanation
In many real-world machine learning scenarios, the training data may contain inaccurate or unreliable labels. This can happen for various reasons, such as human error, ambiguity in the data, or biases in the data collection process. When training machine learning models on noisy data, the models can learn incorrect patterns and perform poorly on new, unseen data.
The authors of this paper propose a solution to this problem in the context of multi-view learning. Multi-view learning is a technique where the same data is represented from multiple perspectives or "views," such as images, text, and sensor data. The key insight is that by leveraging these multiple views, the model can learn more robust and reliable representations of the data, even in the presence of noisy labels.
The proposed framework combines two powerful machine learning techniques: self-supervised learning and meta-learning. Self-supervised learning allows the model to learn useful features from the data without relying on human-provided labels, while meta-learning helps the model adapt to the noise in the training data.
By using this combined approach, the model can learn to identify and overcome the noisy labels, resulting in a more reliable and accurate classifier. This is particularly useful in applications where the data is complex and the labels are difficult to obtain, such as medical imaging or autonomous driving.
Technical Explanation
The paper proposes a Trusted Multi-view Learning with Label Noise (TMULN) framework that leverages multiple views of the data to learn a robust model in the presence of noisy labels. The key components of the framework are:
-
Multi-view Encoder: The model uses a multi-view encoder to extract features from the different views of the data. This allows the model to learn a more comprehensive representation of the samples.
-
Self-supervised Learning: The model is first pre-trained using self-supervised learning tasks, such as view prediction or contrastive learning. This helps the model learn useful representations without relying on the potentially noisy labels.
-
Meta-learning: The model is then fine-tuned using a meta-learning approach, where it learns to adapt to the noisy label distribution. This involves training the model on multiple batches of data with different levels of label noise, allowing it to learn strategies for handling noisy labels.
-
Trusted Classifier: The final step is to train a trusted classifier that can accurately predict the true labels, even in the presence of noise. This is achieved by combining the features learned from the multi-view encoder and the meta-learning process.
The authors evaluate the TMULN framework on several multi-view datasets with different levels of label noise. The results show that the proposed approach outperforms existing methods for learning with noisy labels, demonstrating its effectiveness in handling complex, multi-view data with unreliable labels.
Critical Analysis
The paper presents a well-designed and comprehensive framework for learning robust classifiers from multi-view data with noisy labels. The authors have thoughtfully combined state-of-the-art techniques, such as self-supervised learning and meta-learning, to address this challenging problem.
One potential limitation of the approach is that it may require a significant amount of compute resources and training time, as it involves multiple stages of model training and fine-tuning. This could limit the practical application of the framework in scenarios with strict computational or time constraints.
Additionally, the paper does not discuss in depth the potential biases or fairness implications of the proposed approach. It would be valuable to investigate how the TMULN framework might perform on datasets with demographic biases or other forms of systematic noise in the labels.
Overall, the paper presents a promising and well-executed solution to the important problem of learning from noisy, multi-view data. The authors have made a valuable contribution to the field of robust machine learning and multi-view learning.
Conclusion
The Trusted Multi-view Learning with Label Noise (TMULN) framework proposed in this paper offers a robust and effective solution for learning accurate classifiers from complex, multi-view data with noisy labels. By combining self-supervised learning and meta-learning techniques, the model can learn reliable representations and adapt to the noise in the training data, resulting in a more trustworthy and accurate classifier.
This research has important implications for a wide range of real-world applications, where the available training data may be imperfect or unreliable. The ability to learn robust models in the presence of noisy labels can enable the deployment of machine learning systems in challenging domains, such as medical diagnosis, autonomous driving, and environmental monitoring, where data quality is a critical concern.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Awareness of uncertainty in classification using a multivariate model and multi-views
Alexey Kornaev, Elena Kornaeva, Oleg Ivanov, Ilya Pershin, Danis Alukaev
0
0
One of the ways to make artificial intelligence more natural is to give it some room for doubt. Two main questions should be resolved in that way. First, how to train a model to estimate uncertainties of its own predictions? And then, what to do with the uncertain predictions if they appear? First, we proposed an uncertainty-aware negative log-likelihood loss for the case of N-dimensional multivariate normal distribution with spherical variance matrix to the solution of N-classes classification tasks. The loss is similar to the heteroscedastic regression loss. The proposed model regularizes uncertain predictions, and trains to calculate both the predictions and their uncertainty estimations. The model fits well with the label smoothing technique. Second, we expanded the limits of data augmentation at the training and test stages, and made the trained model to give multiple predictions for a given number of augmented versions of each test sample. Given the multi-view predictions together with their uncertainties and confidences, we proposed several methods to calculate final predictions, including mode values and bin counts with soft and hard weights. For the latter method, we formalized the model tuning task in the form of multimodal optimization with non-differentiable criteria of maximum accuracy, and applied particle swarm optimization to solve the tuning task. The proposed methodology was tested using CIFAR-10 dataset with clean and noisy labels and demonstrated good results in comparison with other uncertainty estimation methods related to sample selection, co-teaching, and label smoothing.
4/17/2024
Navigating Conflicting Views: Harnessing Trust for Learning
Jueqing Lu, Lan Du, Wray Buntine, Myong Chol Jung, Joanna Dipnall, Belinda Gabbe
0
0
Resolving conflicts is essential to make the decisions of multi-view classification more reliable. Much research has been conducted on learning consistent informative representations among different views, assuming that all views are identically important and strictly aligned. However, real-world multi-view data may not always conform to these assumptions, as some views may express distinct information. To address this issue, we develop a computational trust-based discounting method to enhance the existing trustworthy framework in scenarios where conflicts between different views may arise. Its belief fusion process considers the trustworthiness of predictions made by individual views via an instance-wise probability-sensitive trust discounting mechanism. We evaluate our method on six real-world datasets, using Top-1 Accuracy, AUC-ROC for Uncertainty-Aware Prediction, Fleiss' Kappa, and a new metric called Multi-View Agreement with Ground Truth that takes into consideration the ground truth labels. The experimental results show that computational trust can effectively resolve conflicts, paving the way for more reliable multi-view classification models in real-world applications.
6/4/2024

Rethinking the impact of noisy labels in graph classification: A utility and privacy perspective
De Li, Xianxian Li, Zeming Gan, Qiyu Li, Bin Qu, Jinyan Wang
0
0
Graph neural networks based on message-passing mechanisms have achieved advanced results in graph classification tasks. However, their generalization performance degrades when noisy labels are present in the training data. Most existing noisy labeling approaches focus on the visual domain or graph node classification tasks and analyze the impact of noisy labels only from a utility perspective. Unlike existing work, in this paper, we measure the effects of noise labels on graph classification from data privacy and model utility perspectives. We find that noise labels degrade the model's generalization performance and enhance the ability of membership inference attacks on graph data privacy. To this end, we propose the robust graph neural network approach with noisy labeled graph classification. Specifically, we first accurately filter the noisy samples by high-confidence samples and the first feature principal component vector of each class. Then, the robust principal component vectors and the model output under data augmentation are utilized to achieve noise label correction guided by dual spatial information. Finally, supervised graph contrastive learning is introduced to enhance the embedding quality of the model and protect the privacy of the training graph data. The utility and privacy of the proposed method are validated by comparing twelve different methods on eight real graph classification datasets. Compared with the state-of-the-art methods, the RGLC method achieves at most and at least 7.8% and 0.8% performance gain at 30% noisy labeling rate, respectively, and reduces the accuracy of privacy attacks to below 60%.
6/12/2024
🌀
Noise Correction on Subjective Datasets
Uthman Jinadu, Yi Ding
0
0
Incorporating every annotator's perspective is crucial for unbiased data modeling. Annotator fatigue and changing opinions over time can distort dataset annotations. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, this method provides a controllable way to encourage or discourage disagreement. We demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
6/5/2024